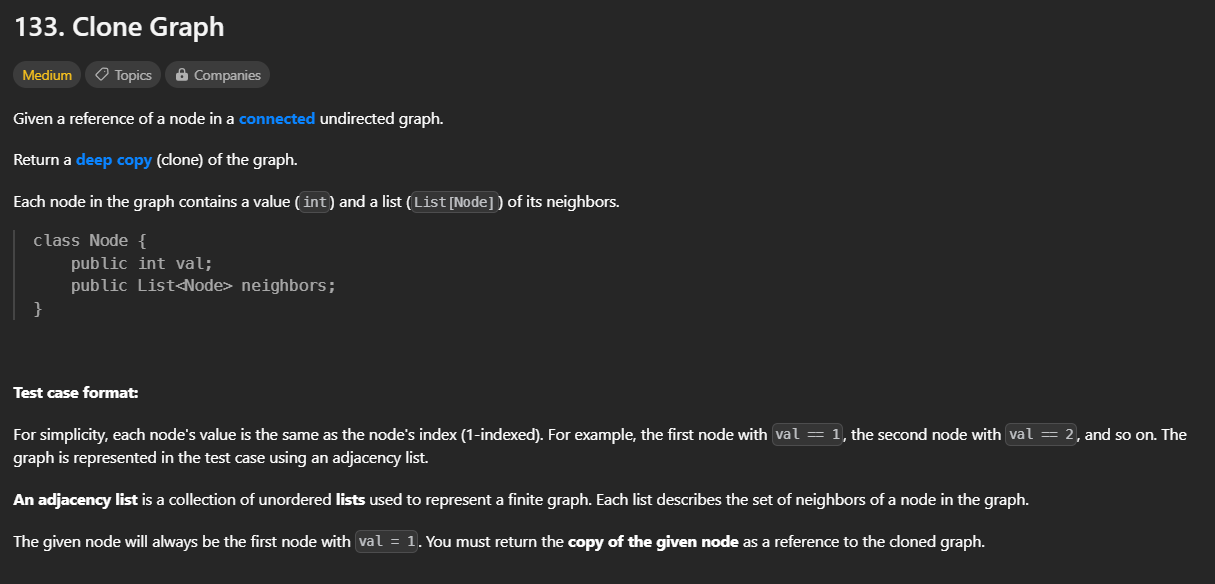
문제
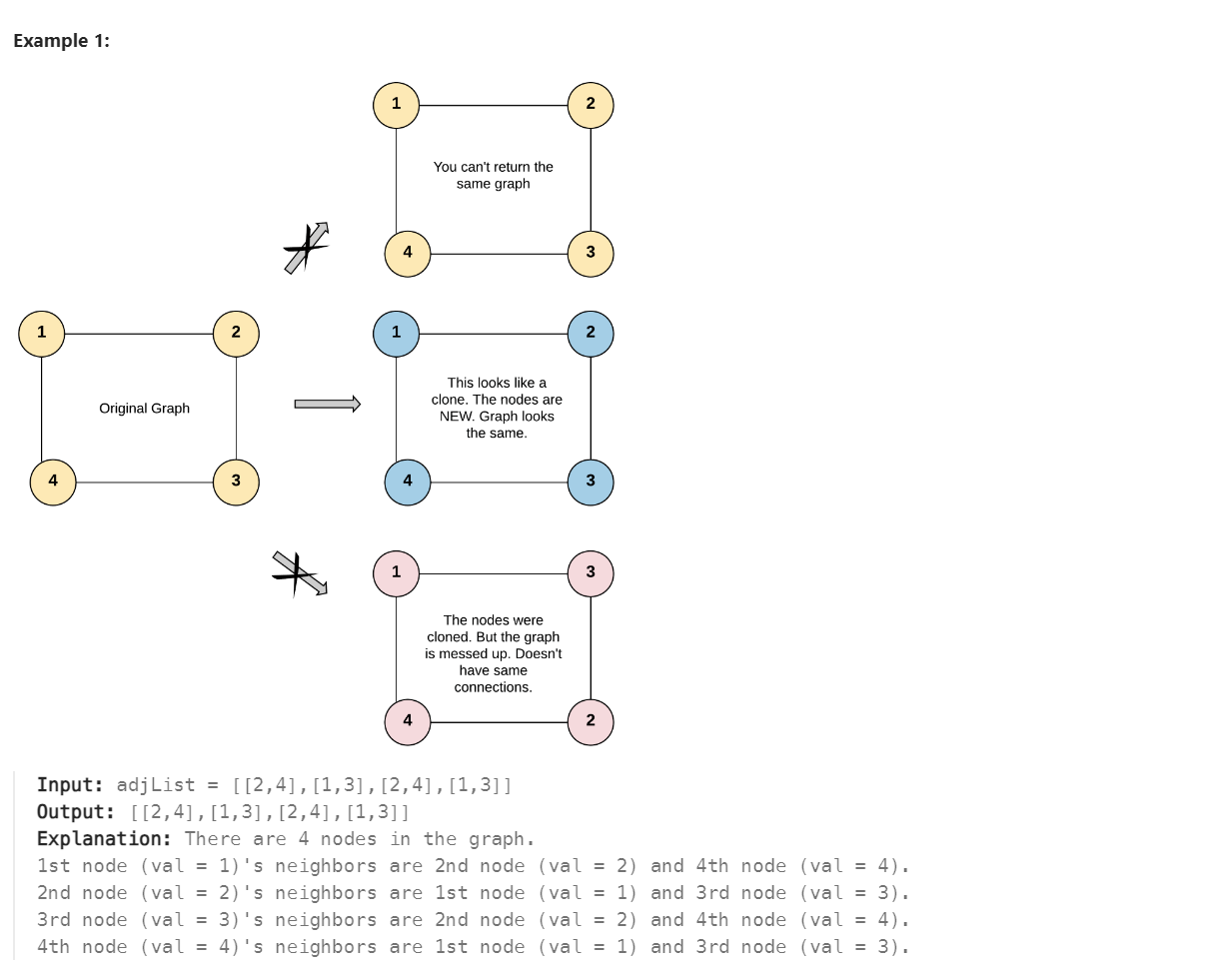
Node 클래스로 이루어진 그래프가 주어진다. 이를 똑같이 clone 하는 함수를 작성해라.
문제 분석
첫번째 시도 (DFS) : 실패
문제를 보고, dfs로 끝까지 노드를 탐색하고, 풀어야 겠다고 생각했다.
모든 노드를 끝까지 탐색하며 마지막 노드(이웃노드들은 모두 방문한 상태) 에서 node를 생성하며 돌려줘야 겠다 생각했다.
코드
class Solution {
boolean[] visited;
Node root = new Node();
public Node cloneGraph(Node node) {
// 0 dummy
visited = new boolean[101];
if(node==null) return null;
root.val = 1;
visited[1] = true;
dfs(root, node);
return root;
}
public Node dfs(Node temp, Node node){
if(node == null) return temp;
for(int i=0; i<node.neighbors.size(); i++){
if(!visited[node.neighbors.get(i).val]){
visited[node.neighbors.get(i).val] = true;
Node newNode = new Node(node.neighbors.get(i).val);
newNode = dfs(newNode, node.neighbors.get(i));
temp.neighbors.add(newNode);
}
}
return temp;
}
}결과 : 실패

테스트코드 3개중 1개가 실패했다.
원인은 이미 dfs를 하며 이미 val 1을 가진 노드를 생성했을 텐데, 양방항 그래프이기에 한 쪽에서만 이웃노드로 있으면 안되고, 양쪽 이웃노드들에 서로가 있어야하는데 이를 간과했다.
그래서 이미 생성되 노드들도 넣어줄 수 있는 방법을 고민해보았다.
두번째 시도 (BFS) : 성공
map을 사용해서 각 노드들과 클론노드를 매칭하여 넣어주도록 하였다.
이러면 각 node들이 여러번 불려도, map에서 각 노드에 해당하는 클론노드를 찾으면 됐다!
코드
class Solution {
public Node cloneGraph(Node node) {
if(node == null)
return null;
Map<Node, Node> map = new HashMap<>();
Queue<Node> queue = new LinkedList<>();
map.put(node, new Node(node.val));
queue.add(node);
while(!queue.isEmpty()){
Node currNode = queue.poll();
Node cloneNode = map.get(currNode);
for(Node temp : currNode.neighbors){
if(!map.containsKey(temp)){
map.put(temp, new Node(temp.val));
queue.add(temp);
}
cloneNode.neighbors.add(map.get(temp));
}
}
return map.get(node);
}
}결과 : 성공

Runtime

Memory

세번째 시도 (DFS) : 성공
bfs로 성공한 후, dfs 도 map을 사용해서 풀어보았다.
이떄 map을 Integer 값이 각 노드마다 unique하다고 하였으니, <Integer, Node> 로 선언해보았다.
코드
class Solution {
Map<Integer, Node> map = new HashMap<>();
public Node cloneGraph(Node node) {
if(node==null) return null;
dfs(node);
return map.get(1);
}
public void dfs(Node node){
if(node.neighbors==null)return;
map.put(node.val, new Node(node.val));
Node currNode = map.get(node.val);
for(int i=0; i<node.neighbors.size(); i++){
if(!map.containsKey(node.neighbors.get(i).val)){
dfs(node.neighbors.get(i));
}
currNode.neighbors.add(map.get(node.neighbors.get(i).val));
}
}
}결과 : 성공

Runtime

Memory

DFS가 BFS보다 2ms 정도 느렸고, 메모리도 0.4MB 더 차지했다.
아마도 DFS는 탐색에서 A -> B 경로의 유무를 판단하고, BFS는 A -> B는 최단 경로를 돌려주기에, BFS가 좀더 빠르지 않을까 싶었다. 아마 반복문 횟수가 BFS가 덜 나갈 것 같았다.
