T-test
T-test란?
- 모집단의 분산이나 표준편차를 알지 못할 때 모집단을 대표하는 표본으로부터 추정된 분산이나 표준편차를 가지고 검정하는 방법
즉, 두 개의 집단 간 평균 차이가 통계적으로 유의미한지를 검정하는 방법
t값(t-value)
- t값이란 t검정에 이둉되는 검정통계량, 두 집단의 차이의 평균을 표준오차로 나눈 값
즉, 표준오차와 표본평균 사이의 차이의 비율
T-test 예시
1. 가정
- 한 게임 회사가 게임 A와 게임 B를 출시
- 두 게임의 평균 플레이 시간이 차이가 있는지 확인을 위한 t검정 실행
2. 데이터 수집
- 무작위로 선택한 각 게임별 30명의 플레이어들에게 게임 A,B를 플레이
- 각 플레이어들의 플레이 시간을 기록
3. 가설 설정
- 귀무 가설 : 게임A와 게임B의 평균 플레이 시간은 같다
- 대립 가설 : 게임A와 게임B의 평균 플레이 시간은 다르다
4. T-검정 수행
- 두 집단(게임A, 게임B)간의 평균 플레이 시간 차이를 비교하기 위해 t검정 수행
- t검정은 표본의 평균, 표준편차, 표본 크기 등을 고려하여 검정 통계량(t값)을 계산
5. 유의수준과 기각 영역 판단
- 사전에 결정한 유의 수준(예 : 0.05)에 따라 임계값을 설정
- t-검정 결과에서 계산된 t-value를 임계값과 비교
- t-value가 임계값보다 크거나 작으면, 귀무가설을 기각하고 대립가설을 채택
주유소 데이터 활용 T-test 진행
주제 : 강남과 강북의 휘발유 평균 차이는 있는가?
# 서울 자치구 상반기&하반기 주유소 데이터를 가져와서 concat으로 결합
import pandas as pd
df1 = pd.read_csv("./상반기 주유소 판매가격.csv", encoding='cp949')
df2 = pd.read_csv("./하반기 주유소 판매가격.csv", encoding='cp949')
oil = pd.concat([df1, df2], ignore_index=True )

# 지역별 휘발유 가격
oil.groupby(['지역'])['휘발유'].mean().sort_values()

#강남구, 강북구 휘발유 평균
a = oil.query(" 지역 == '서울 강북구'")['휘발유'].values
b = oil.query(" 지역 == '서울 강남구'")['휘발유'].values
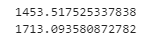
print (oil.query(" 지역 == '서울 강북구'")['휘발유'].mean())
print (oil.query(" 지역 == '서울 강남구'")['휘발유'].mean())
# t-test (독립표본 t-test )
stats.ttest_ind(oil.query(" 지역 == '서울 강북구'")['휘발유'],
oil.query(" 지역 == '서울 강남구'")['휘발유'])
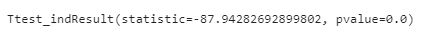
- 검정통계량(statistic) 값이 87.94로 첫 번째 집단의 평균이 두 번째 집단의 평균보다 작아 유의미한 평균차이가 있으며, p-value값이 0으로 유의수준(0.05)보다 작아 귀무가설을 기각하고 대립가설을 채택 함

