프로젝트 개요
1. 전이학습 활용 연예인 얼굴 분류 모델(.h5) 생성
2. Django로 이미지 업로드 시 닮은 연예인을 분류하는 홈페이지 생성
전체적 구조
face
┣ mysite
┃ ┣ config
┃ ┃ ┣ __pycache__
┃ ┃ ┃ ┣ __init__.cpython-310.pyc
┃ ┃ ┃ ┣ __init__.cpython-39.pyc
┃ ┃ ┃ ┣ settings.cpython-310.pyc
┃ ┃ ┃ ┣ settings.cpython-39.pyc
┃ ┃ ┃ ┣ urls.cpython-310.pyc
┃ ┃ ┃ ┣ urls.cpython-39.pyc
┃ ┃ ┃ ┣ wsgi.cpython-310.pyc
┃ ┃ ┃ ┗ wsgi.cpython-39.pyc
┃ ┃ ┣ __init__.py
┃ ┃ ┣ asgi.py
┃ ┃ ┣ settings.py
┃ ┃ ┣ urls.py
┃ ┃ ┗ wsgi.py
┃ ┣ star
┃ ┃ ┣ __pycache__
┃ ┃ ┃ ┣ __init__.cpython-310.pyc
┃ ┃ ┃ ┣ __init__.cpython-39.pyc
┃ ┃ ┃ ┣ admin.cpython-310.pyc
┃ ┃ ┃ ┣ admin.cpython-39.pyc
┃ ┃ ┃ ┣ apps.cpython-310.pyc
┃ ┃ ┃ ┣ apps.cpython-39.pyc
┃ ┃ ┃ ┣ forms.cpython-310.pyc
┃ ┃ ┃ ┣ models.cpython-310.pyc
┃ ┃ ┃ ┣ models.cpython-39.pyc
┃ ┃ ┃ ┣ urls.cpython-310.pyc
┃ ┃ ┃ ┣ urls.cpython-39.pyc
┃ ┃ ┃ ┣ views.cpython-310.pyc
┃ ┃ ┃ ┗ views.cpython-39.pyc
┃ ┃ ┣ migrations
┃ ┃ ┃ ┣ __pycache__
┃ ┃ ┃ ┃ ┣ __init__.cpython-310.pyc
┃ ┃ ┃ ┃ ┗ __init__.cpython-39.pyc
┃ ┃ ┃ ┗ __init__.py
┃ ┃ ┣ .DS_Store
┃ ┃ ┣ __init__.py
┃ ┃ ┣ admin.py
┃ ┃ ┣ apps.py
┃ ┃ ┣ forms.py
┃ ┃ ┣ models.py
┃ ┃ ┣ team3_new.h5
┃ ┃ ┣ tests.py
┃ ┃ ┣ urls.py
┃ ┃ ┗ views.py
┃ ┣ static
┃ ┃ ┣ assets
┃ ┃ ┃ ┣ img
┃ ┃ ┃ ┃ ┣ .DS_Store
┃ ┃ ┃ ┃ ┣ bg-callout.jpg
┃ ┃ ┃ ┃ ┣ bg-masthead.jpg
┃ ┃ ┃ ┃ ┣ portfolio-1.jpg
┃ ┃ ┃ ┃ ┣ portfolio-2.jpg
┃ ┃ ┃ ┃ ┣ portfolio-3.jpg
┃ ┃ ┃ ┃ ┗ portfolio-4.jpg
┃ ┃ ┃ ┣ .DS_Store
┃ ┃ ┃ ┗ favicon.ico
┃ ┃ ┣ css
┃ ┃ ┃ ┣ style.css
┃ ┃ ┃ ┗ styles.css
┃ ┃ ┣ js
┃ ┃ ┃ ┗ scripts.js
┃ ┃ ┗ .DS_Store
┃ ┣ templates
┃ ┃ ┣ index.html
┃ ┃ ┗ result.html
┃ ┣ .DS_Store
┃ ┣ db.sqlite3
┃ ┣ manage.py
┃ ┗ requirements.txt
┗ .DS_Store모델 생성(vgg16)
# 라이브러리 임포트
import tensorflow as tf
from tensorflow.keras.preprocessing import image
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.image import pad_to_bounding_box
from tensorflow.image import central_crop
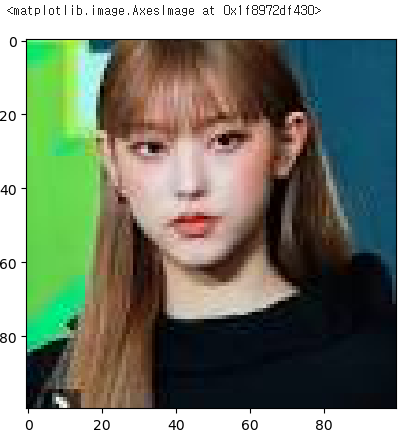
from tensorflow.image import resize#이미지 불러오기
bgd = image.load_img('./train/train_1/4.jpg')
bgd_vector = np.asarray(image.img_to_array(bgd))
bgd_vector = bgd_vector/255
#이미지 형태 확인
bgd_vector.shape
#이미지 확인
plt.imshow(bgd_vector)
plt.show()-
이미지 파일을 numpy배열로 변환하여 np.asarray()함수를 사용하여 배열로 변환
-
bad_vector 배열의 모든 원소를 255로 나누어서 0~1범위로 정규화

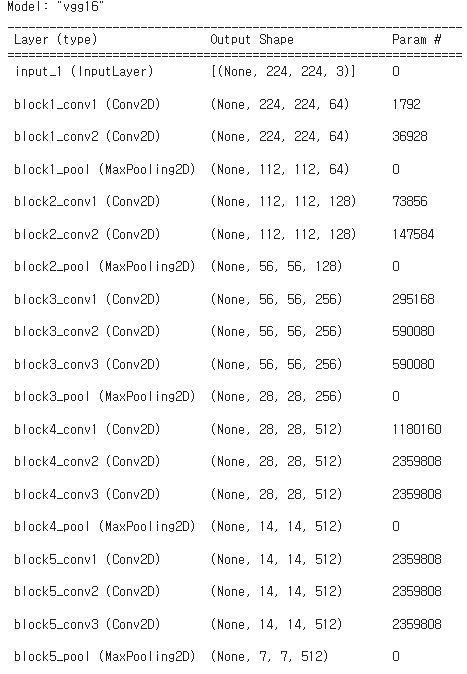
from tensorflow.keras.applications.vgg16 import VGG16
#weight, include_top 파라미터 설정
model = VGG16(weights='imagenet', include_top=True)
model.summary()- TensorFlow의 keras라이브러리에서 vgg16모델을 훈련
- weight : 사전에 훈련된 가중치를 지정하고 'imagenet'을 지정하면 imageNet 데이터셋으로 사전 훈련된 가중치를 사용
- include_top : 모델의 최상위에 있는 완전 연결 레이어를 포함여부 결정(True = 포함)
이미지 전처리 및 정규화
from tensorflow.keras.applications.vgg16 import preprocess_input
from tensorflow.keras.preprocessing import image
import matplotlib.pyplot as plt
from PIL import Image
from tensorflow.keras.applications.imagenet_utils import decode_predictions
from tensorflow.keras.applications.imagenet_utils import preprocess_input
import numpy as np
#from google.colab import drive
#drive.mount('/content/gdrive')
img = Image.open('./train/train_1/4.jpg')
img.size
plt.imshow(np.asarray(img))
- import preprocess_input : vgg16모델에 입력하기 전에 이미리를 전처리
- import image : 이미지를 전처리하기 위한 'image'모듈 호출
- decode_predictions : vgg16모델의 출력을 해석하여 가장 가능성 있는 클래스 레이브을 가져오기
#VGG16이 입력받는 이미지크기 확인
model.layers[0].input_shape
#이미지 리사이즈
target_size = 224
img = img.resize((target_size, target_size)) # resize from 280x280 to 224x224
plt.imshow(np.asarray(img))
img.size #변경된 크기 확인- 이미지 크기를 vgg16모델의 적합한 224*224크기로 resize
#numpy array로 변경
np_img = image.img_to_array(img)
np_img.shape #(224, 224, 3)
#4차원으로 변경
img_batch = np.expand_dims(np_img, axis=0)
img_batch.shape
--> (1, 224, 224, 3)
- img이미지를 img_to_array()함수를 이용하여 numpy배열로 변환하여 np_img변수에 할당
- np.expand_dims(np_img, axis = 0)를 통해 첫 번째 축을 추가하여 np_img배열의 차원을 4차원으로 생성
- (1,224,224,3) : 이미지 배치의 개수, 이미지 높이, 이미지 너비, 채널 수
#feature normalization
pre_processed = preprocess_input(img_batch)
pre_processed
y_preds = model.predict(pre_processed)
y_preds.shape # 종속변수가 취할 수 있는 값의 수 = 1000
np.set_printoptions(suppress=True, precision=10)
y_preds
#가장 확률이 높은 값
np.max(y_preds)- model에 입력 이미지 pre_processed를 전달하여 예측 수행하고, model.predict()함수는 입력 이미지에 대한 예측 결과를 반환
- y_preds.shape에서 배열의 크기를 확인하면 (1,1000)으로 표시되는데 여기서 1은 입력 이미지의 배치 크기, 1000은 vgg16모델이 imagenet데이터셋에 대해 분류할 수 있는 클래스 개수 표시
- np.set_printoptions(suppress=True, precision=10) : numpy 배열 출력 옵션 설정 (suppress = True - 지수 표기법 사용하지 않음, precision = 10 - 소수점 아래 10자리까지 출력)
- np.max(y_preds) : y_preds배열에서 가장 큰 값, 가장 높은 확률을 출력

모델 생성
TRAIN_DATA_DIR = './train'
VALIDATION_DATA_DIR = './validation'
TEST_DATA_DIR = './test'
TRAIN_SAMPLES = 800*2
VALIDATION_SAMPLES = 400*2
NUM_CLASSES = 2
IMG_WIDTH, IMG_HEIGHT = 224, 224
BATCH_SIZE = 64
train_datagen = ImageDataGenerator(preprocessing_function=preprocess_input,
rotation_range=20,
width_shift_range=0.2,
height_shift_range=0.2,
zoom_range=0.2)
val_datagen = ImageDataGenerator(preprocessing_function=preprocess_input)- preprocessing_function 매개변수를 통해 이미지 전처리 함수를 사용하여 preprocess_input함수로 vgg16모델에 적합한 형태로 전처리
- 이미지 회전, 가로/세로 이동, 확대/축소 등의 데이터 증강 수행
train_generator = train_datagen.flow_from_directory(TRAIN_DATA_DIR,
target_size=(IMG_WIDTH,
IMG_HEIGHT),
batch_size=BATCH_SIZE,
shuffle=True,
seed=12345,
class_mode='categorical')
validation_generator = val_datagen.flow_from_directory(
VALIDATION_DATA_DIR,
target_size=(IMG_WIDTH, IMG_HEIGHT),
batch_size=BATCH_SIZE,
shuffle=False,
class_mode='categorical')train_generator(훈련 데이터용 모델 생성)
- TRAIN_DATA_DIR경로에 있는 데이터 로드하여 입력 이미지 크기(target_size), 배치에 포함할 이미지 개수(batch_size) 설정
- 다중분류를 위해 categorical로 설정
validation_generator(검증 데이터용 모델 생성)
- 데이터 경로를 VALIDATION_DATA_DIR로 설정하고 훈련 데이터용 모델과 동일하게 매개변수 설정
최종 모델 생성
def model_maker():
base_model = VGG16(include_top=False, input_shape=(IMG_WIDTH, IMG_HEIGHT, 3))
print(len(base_model.layers))
for layer in base_model.layers[:]:
layer.trainable = False
input = Input(shape=(IMG_WIDTH, IMG_HEIGHT, 3))
custom_model = base_model(input)
custom_model = GlobalAveragePooling2D()(custom_model)
custom_model = Dense(32, activation='relu')(custom_model)
predictions = Dense(NUM_CLASSES, activation='softmax')(custom_model)
return Model(inputs=input, outputs=predictions)
model_final = model_maker()
model_final.summary()- 최상위 레이어(nclude_top=False)를 포함하지 않도록 설정
- for layer in base_model.layers[:]: layer.trainable = False : 기본 모든 레이어를 동결하여 레이어의 가중치가 업데이드 되지 않도록 설정(기본 모델의 훈련을 방지)
- custom_model에 입력 레이어를 기반으로 기본 모델 적용하고, GlobalAveragePooling2D()(custom_model)를 통해 차원축소 진행
- Dense(32, activation='relu')(custom_model) : 전역 평균 풀링 이후 완전 연결 레이어 추가(뉴런 32개, ReLu활성화 함수 사용)
- Dense(NUM_CLASSES, activation='softmax')(custom_model) : 클래스 개수 표시 후 'softmax'활성화 함수를 사용하여 클래스별 확률 계산

최종모델 컴파일
model_final.compile(loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(0.001),
metrics=['acc'])
history = model_final.fit(
train_generator,
steps_per_epoch=TRAIN_SAMPLES // BATCH_SIZE, # number of updates
epochs=10,
validation_data=validation_generator,
validation_steps=VALIDATION_SAMPLES // BATCH_SIZE)- 손실함수(loss)는 categorical_crossentropy를 사용하고 학습률은 0.001로 설정
- 훈련 데이터와 검증 데이터를 사용하여 모델을 학습하고, 10 에포크로 fit함수를 통해 훈련하고 history에 학습결과 저장
테스트 데이터 모델 생성
test_datagen = ImageDataGenerator(preprocessing_function=preprocess_input)
test_generator = val_datagen.flow_from_directory(
TEST_DATA_DIR,
target_size=(IMG_WIDTH, IMG_HEIGHT),
batch_size=BATCH_SIZE,
shuffle=False,
class_mode='categorical')- TEST_DATA_DIR경로에 데이터를 활용하여 테스트 데이터 모델 생성
모델 성능 파악
model_final.evaluate(test_generator, steps=800 // BATCH_SIZE)
- 테스트 데이터를 사용하여 모델의 성능 파악, 800번의 업데이트 진행
prediction = model_final.predict(preprocessed_img)
print(np.array(prediction[0]))
- 전처리된 사진과 테스트 데이터 모델과 비교 시 prediction배열의 첫 번째 원소(확률 값) 출력
프로젝트 진행 후 생각
- 사진 데이터 수집 시 크롤링 함수를 구현하여 진행하였는데, 연예인 사진이 얼굴이 정확한 사진(데이터셋) 부족으로 모델의 학습이 부족함
- 얼굴 사진 라이브러리 확인 및 함수 구현 방법으로 대체 필요
- cpu로 처리하여 처리 속도 부족으로 aws의 머신러닝 처리기 등 GPU가 지원되는 방법으로 진행 필요
