SQL INDEX 자료구조
INDEX에서 B-tree, B+tree자료구조를 사용하는 이유
- SQL INDEX는 데이터 저장, 수정, 삭제에 대한 성능을 탐색(select)성능을 대폭 상승하는 방식
- 그렇다면, INDEX는 자료 구조 중에서 B-tree를 사용하는 이유는 무엇인지?
사전 지식
페이지(page)
- 디스크와 메모리에 데이터를 읽고 쓰는 최소 작업단위
- 페이지에 저장되는 개별 데이터의 크기를 최대한 작게하고, 1개의 페이지에 많은 데이터 저장 필요
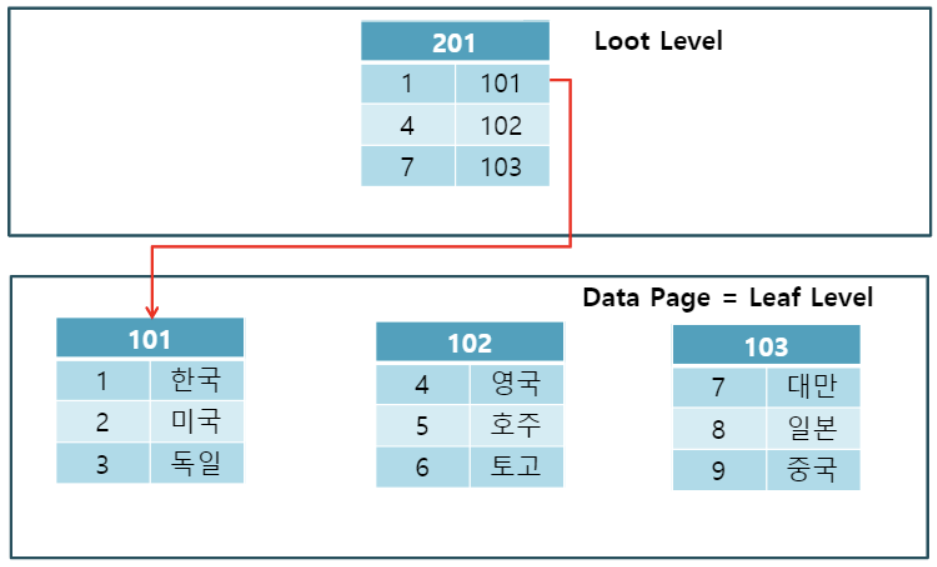
클러스터형 인덱스(Clusterd index)
- 테이블 당 한 개만 생성 가능한 인덱스
- 행 데이터를 인덱스로 지정한 열에 맞춰서 자동 정렬
- root페이지, leaf페이지로 구성되어 root페이지는 leaf페이지 주소로 저장, leaf페이지는 실제 데이터 페이지로 구성
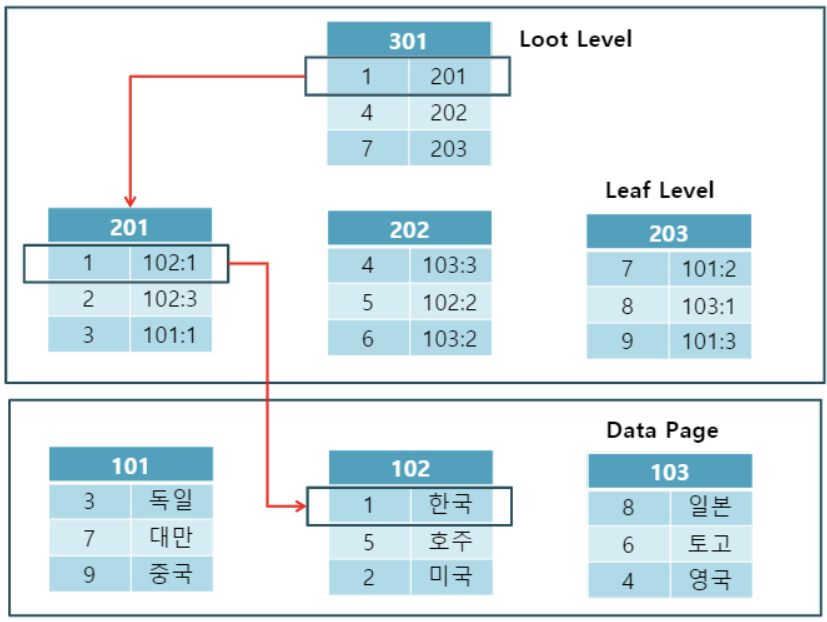
넌클러스터형 인덱스(NonClusterd index)
- 테이블 당 여러 개 생성가능한 인덱스
- 데이터페이지를 건드리지 않고, 별도의 저장소에 index페이지를 생성 및 정렬
랜덤 엑세스(RANDOM Access)
- 데이터를 저장하는 페이지를 한 번에 여러 개 엑세스하는 것이 아닌 한 번에 하나의 페이지만들 엑세스하는 방식
- 인덱스를 엑세스하여 확인한 ROWID를 이용하여 테이블을 엑세스하는 경우 발생
B-tree 인덱스(Balanced Tree, 균형 트리)
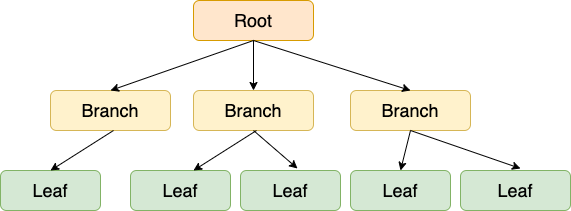
- B-tree는 하나의 노드에 여러 개의 값을 가질 수 있고, 최대 자식 노드가 2개 이상일 수 있는 자료구조
- 각 노드 내 데이터들은 항상 정렬된 상태로 데이터와 데이터 사이의 범위를 이용하여 자식 노드를 가짐
- 각 노드에는 여러 개의 key를 가지고 있으며 이 key에 대응하는 데이터값을 갖고 있음
B-tree가 빠른 이유
- 어떤 값에 대해서도 같은 시간에 결과를 얻을 수 있다는 장점 보유(균일성)
- 항상 정렬된 상태로 유지되어 있어 특정 값보다 크고 작은 부등호 연산에 문제가 없음
B+tree 인덱스
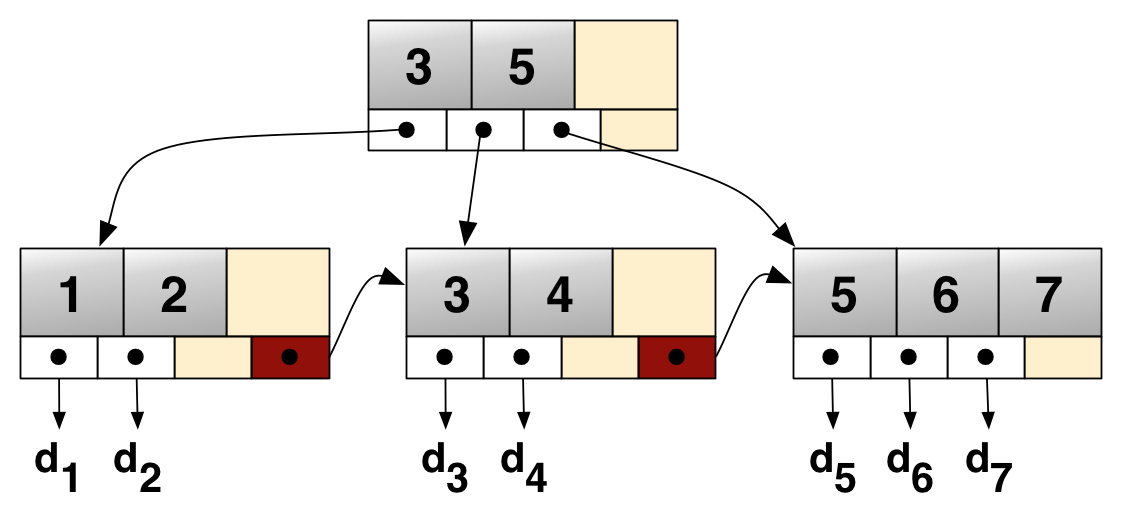
-
B-tree의 경우, branch노드에 key와 data를 담을 수 있었지만, B+tree의 경우 branch 노드에 key만 담아두고, data는 담지 않음
-
오직 leaf node에만 key와 data를 저장하고, leaf node끼리 Linked list로 연결되어 있음
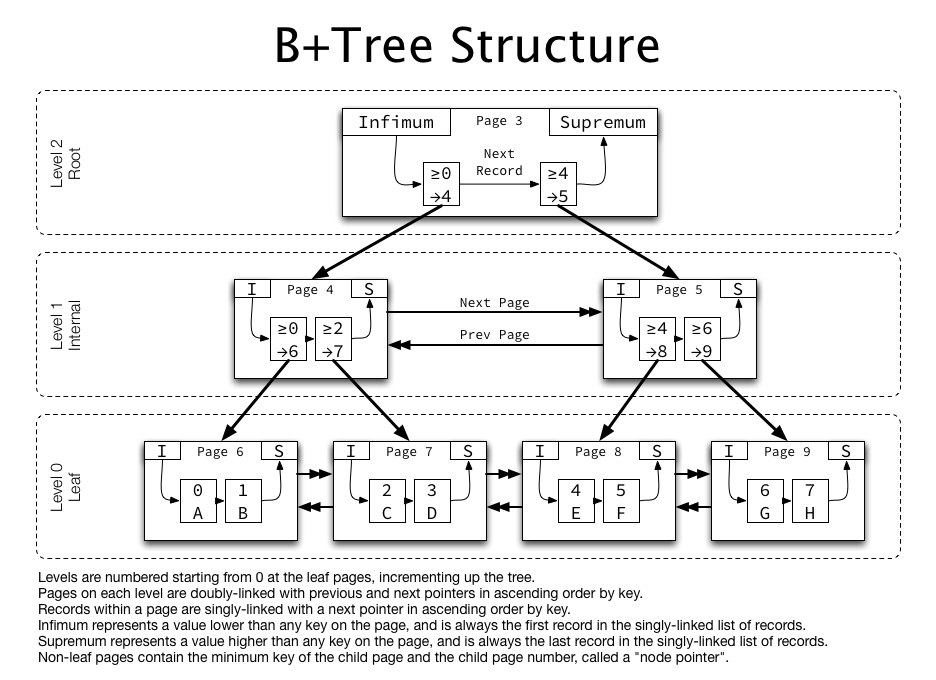
B+tree 장점
- leaf node를 제외하고 데이터를 담아두지 않기 때문에 메모리를 더 확보함으로써 더 많은 key를 담아둘 수 있음
- leaf node들은 linked list로 연결되어 있어 순차검색을 용이하게 함
- full scan 진행 시, B+tree는 leaf node에 데이터가 모두 있어 한 번의 선형 탐색만 진행하여 B-tree에 비해 빠름
- key의 범위마다 포인터가 있어, 해당 페이지 넘버를 통해 곧바로 다음 node로 이동
위의 사진에서 B+tree Structure 진행 예시
- 입력 값 예시 : 3
- 0보다 크거나 같을 때 page4로 이동
- 2보다 크니 page7로 이동
- 3 = D
참고
- https://zorba91.tistory.com/293
- https://rebro.kr/167
- https://velog.io/@sem/DB-%EC%9D%B8%EB%8D%B1%EC%8A%A4-%EC%9E%90%EB%A3%8C-%EA%B5%AC%EC%A1%B0-B-Tree
- https://velog.io/@sweet_sumin/%ED%81%B4%EB%9F%AC%EC%8A%A4%ED%84%B0%EB%93%9C-%EC%9D%B8%EB%8D%B1%EC%8A%A4-Clustered-Index-%EB%84%8C-%ED%81%B4%EB%9F%AC%EC%8A%A4%ED%84%B0%EB%93%9C-%EC%9D%B8%EB%8D%B1%EC%8A%A4-Non-Clustered-Index
