InnoDB Architecture
Mysql은 스토리지 엔진이라 불리는 플러그 인 방식으로 데이터베이스를 관리
그 중 가장 많이 사용되는 엔진이 Mysql8.0버전 이상부터는 InnoDB엔진을 가장 많이 사용
InnoDB 구조
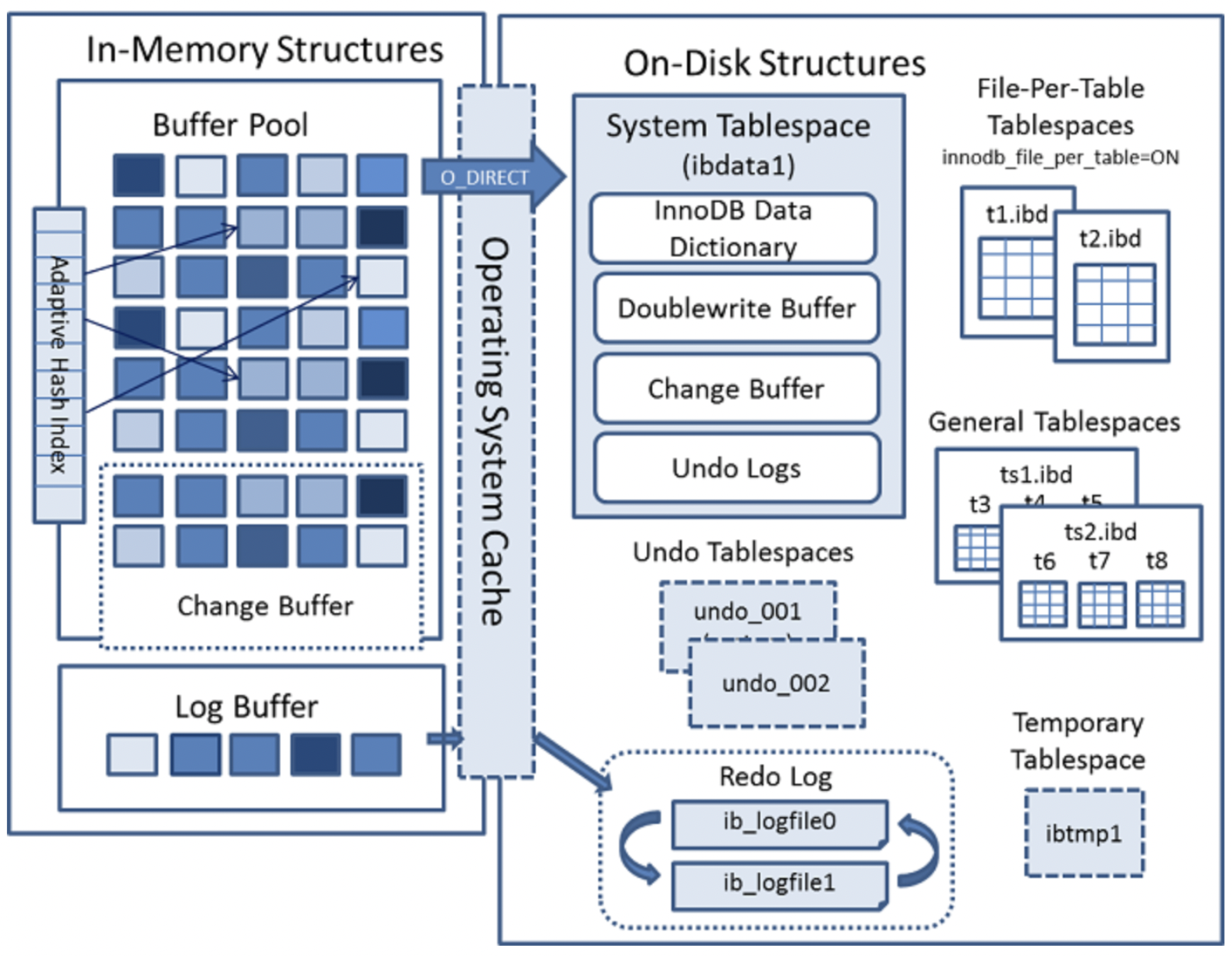
- InnoDB는 IN-memory구조로, 데이터와 인덱스를 캐싱하기 위한 Buffer Pool이라는 저장 영역을 유지 및 관리
- 주요 구성요소는 총 4가지
- Buffer Pool
- Change Buffer
- Adaptive Hash Index
- Log Buffer
Buffer Pool
- InnoDB가 엑세스할 때 테이블과 인덱스 데이터를 캐시하는 메인 메모리영역
-> 디스크가 아닌 메모리에서 데이터를 직접 처리하기 때문에 처리속도를 향상 - InnoDB는 데이터에 엑세스 할 때, 우선적으로 Buffer Pool을 확인한 후 원하는 데이터가 없을 시 디스크에서 페이지를 읽은 후 Buffer Pool에 추가
- Buffer Pool은 LRU알고리즘으로 구현되어 있어 새 패이지를 추가하기 위한 영역이 필요한 경우, 가장 오래전 페이지를 삭제하고 새 페이지가 리스트의 중앙에 추가
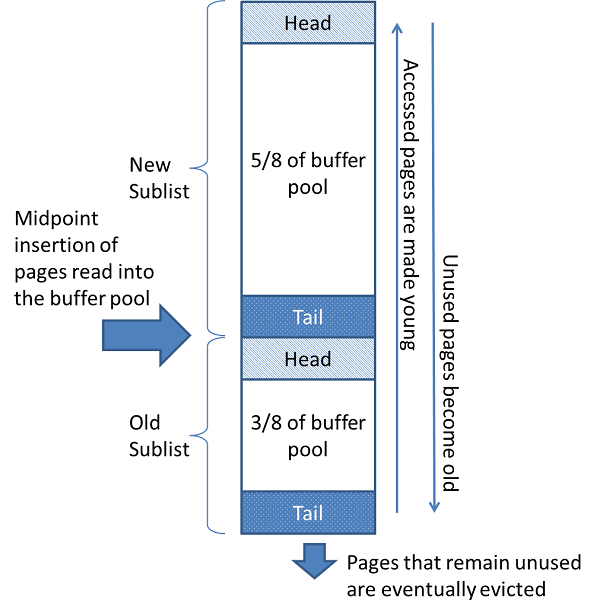
Buffer Pool의 LRU알고리즘
- Buffer Pool의 각 페이지를 리스트로 연결하여 페이지에 엑세스 할 때마다 대상의 페이지를 리스트의 맨 앞(MRU : Most Recently Used)로 이동
- 사용되지 않는 페이지는 말단(LRU : Least Recently Used)으로 이동되어 Buffer Pool의 용량을 초과한 것은 메모리에서 삭제
Change Buffer
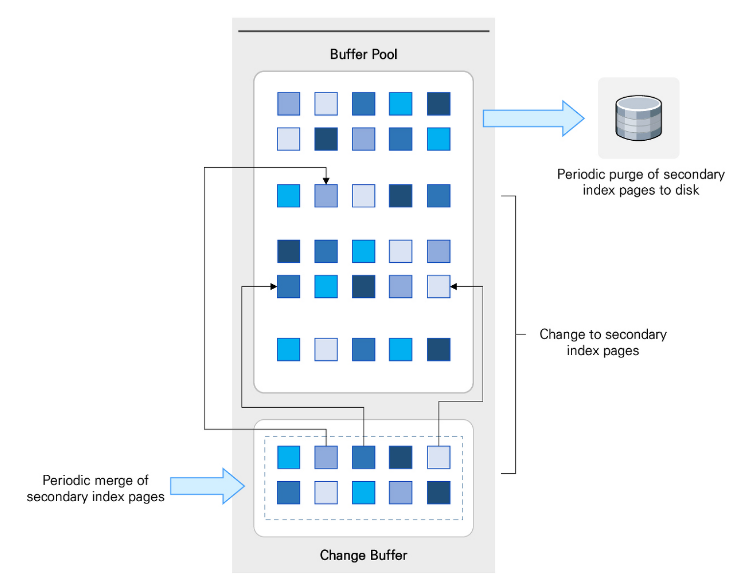
- Change Buffer는 InnoDB Buffer Pool에 포함되는 영역으로 Secondary Index page(논클러스터 인덱스)의 변경 내용을 캐싱하기 위한 임시 공간
- Insert, delete, update 등의 DML작업은 Secondary Index에 대한 변경작업을 필요로 하여 많은 디스크 리소스가 필요
- 변경해야 할 Secondary Index의 페이지가 Buffer Pool에 존재할 경우 바로 메모리 내에서 작업 가능하나, 없을 경우에는 변경 내역만을 Change Buffer에 저장 후 적용하는 방식을 통해 성능 향상
- Change Buffer에 저장된 변경내역은 추후 다른 Read작업에 의해 페이지가 Buffer Pool에 로드될 때 Merge
- 이러한 동작 방식으로 디스크에서 Buffer Pool로 Secondary Index Page를 읽는데 필요한 I/O를 줄임
Adaptive Hash Index
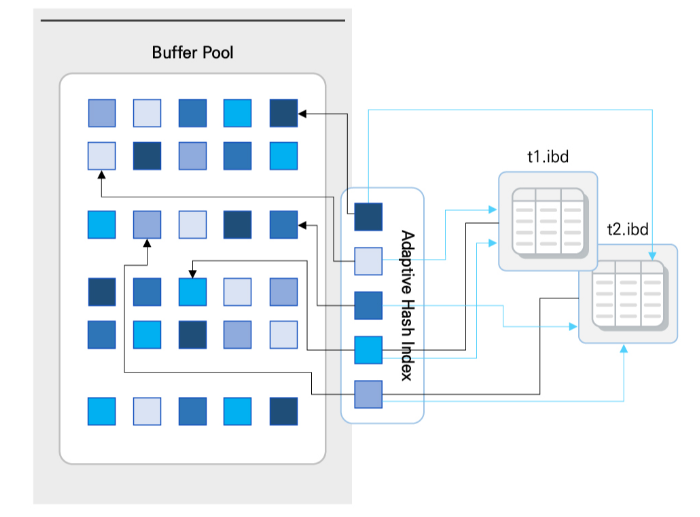
- Adaptive Hash Index도 Buffer Pool공간의 일정 부분을 사용
- Adaptive Hash Index는 B-tree Index의 한계를 보완하기 위한 InnoDB의 주요 기능으로, 자주 사용되는 컬럼을 Hash로 정의하여 B-Tree Index를 이용하지 않고 직접 Data에 엑세스 가능
- 이 기능을 통해 InnoDB는 트랜재션 기능이나, 신뢰성 저항 없이 Buffer Pool의 성능을 향상 시킬 수 있음
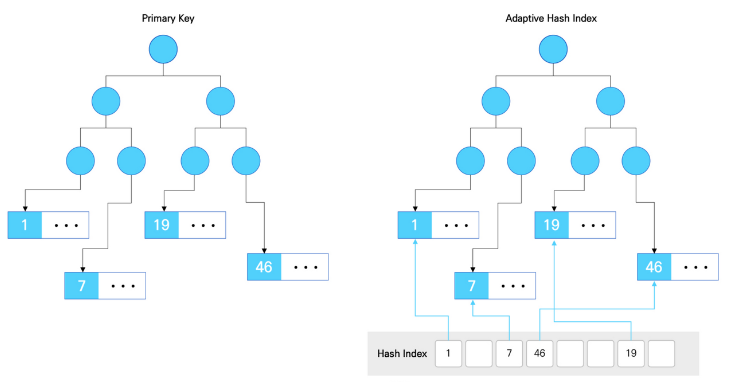
- Adaptive Hash Index는 index key값과 이 주소가 저장된 data페이지로 구성되어 자주 엑세스하는 index페이지만 생성
Log Buffer
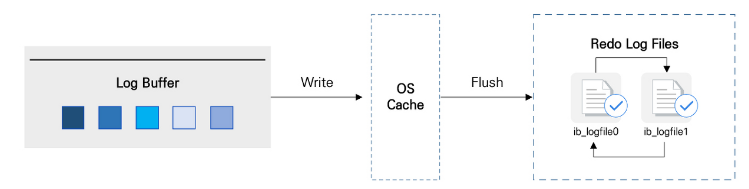
- Log Buffer는 Redo Log파일에 기록할 데이터를 보관하는 메모리 영역
- InnoDB는 Buffer Pool의 데이터를 변경할 때 Log Buffer에 기록한 후, 설정된 주기 혹은 트랜잭션 Commit시점에 디스크로 내려쓰기 진행
- Log Buffer의 크기는
innodb_log_buffer_size라는 변수로 설정가능- 값이 클 시, 트랜잭션이 commit되기 전에 Redo log Data를 디스크에 쓸 필요없이 대용량 트랜잭션 가능
- 값이 작을 시, 체크포인트가 자주 발생하여 디스크 I/O가 많아짐
redo Log
- 데이터베이스에서 일어난 모든 변화를 저장하는 메모리 공간
- 사용자의 Insert, delete, update작업으로 인해 데이터의 변화가 아직 디스크에는 적용되지 않는 상태로 에러가 발생할 때, redo log를 활용해 디스크에 반영하는 작업 진행
InnoDB 특징
1. PK로 클러스터링
- InnoDB에서는 PK(프라이머리 키)를 기준으로 정렬된 형태도 실제 데이터를 저장
- 이로 인해 인덱스 레인지 스캔을 활용하면 데이터를 빨리 조회할 수가 있음
2. 외래키 지원
- 데이터의 무결성을 지원하기 위해 외래키 기능 사용
- 그러나 데이터 변경 시에는 반드시 부모, 자식테이블에 데이터가 있는지 체크하는 작업이 필요하므로 잠금이 여러 테이블에 있어 데드락 발생 가능성 보유
3. MVCC지원(Multi version Concurrency Control)
- InnoDB는 다중버전 스토리지 엔진으로, 동시성 및 롤백 등의 트랜잭션 기능을 지원하기 위해 이전 버전의 변경된 데이터에 대한 정보를 유지
- 즉, 하나의 레코드에 대해 격리수준에 따라 여러 버전이 존재하고, 필요에 따라 데이터가 어떻게 보여질지 달라지는 구조
4. 자동 데드락 감지
- InnoDB스토리지 엔진에서는 내부적으로 잠금이 교착상태에 있는지 체크하기 위해 잠금 대기 상황을 그래프로 관리
5. 자동화된 장애 복구
- Mysql이 갑자기 종료되어 완료되지 못한 트랜잭션이나 디스크에 일부만 써진 데이터가 존재한다면 InnoDB는 서버를 재시작할 때 자동으로 복구
- 자동복구가 자동으로 안될 때는
innodb_force_recovery변수를 설정 필요 -> 이 부분은 차후 글을 올리겠습니다
참조
https://blog.ex-em.com/1698
https://neverfadeaway.tistory.com/61
https://myinfrabox.tistory.com/42
Real mysql8.0 1권
