MLOPS Pipeline
MLOPS 정의
개발과 운영을 따로 나누지 않고 개발의 생산성과 운영의 안정성을 최적화하기 위한 문화이자 방법론인 DevOps를 ML 시스템에 적용한 것이며, ML의 전체 Lifecycle을 관리함
ML의 대상
- ML 모델
- 데이터를 수집하고 분석하는 단계(Data Collection, Ingestion, Analysis, Labeling, Validation, Preparation)
- ML 모델을 학습하고 배포하는 단계(Model Training, Validation, Deployment)
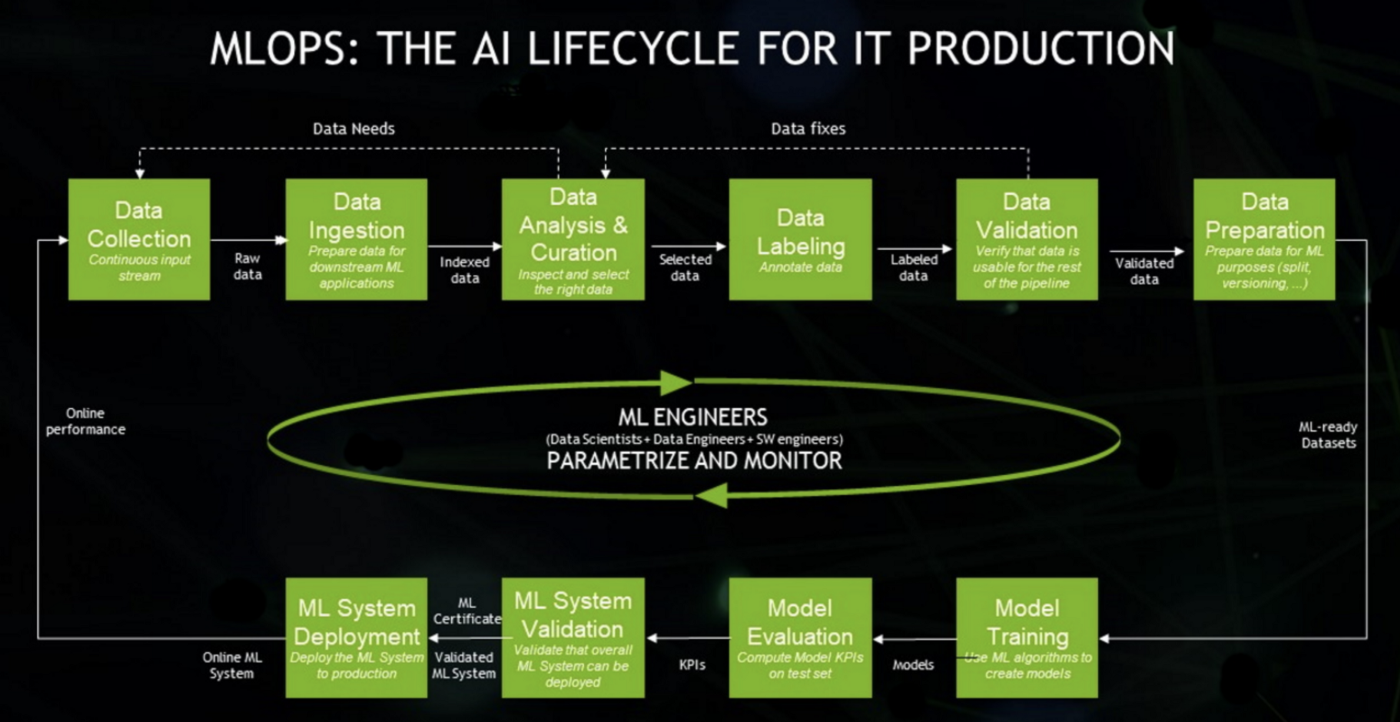 MLOPS by NVIDIA(from https://blogs.nvidia.com/blog/2020/09/03/what-is-mlops/)
MLOPS by NVIDIA(from https://blogs.nvidia.com/blog/2020/09/03/what-is-mlops/)
시스템의 요소
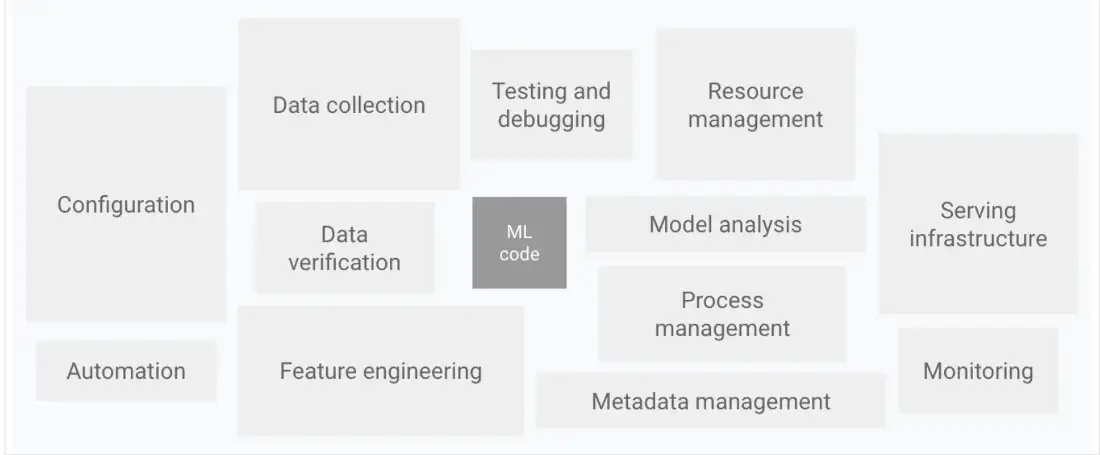 ML 시스템의 요소(Hidden Technical Debt in Machine Learning Systems)
ML 시스템의 요소(Hidden Technical Debt in Machine Learning Systems)
- Testing
일반적인 단위, 통합 테스트 외에 데이터 검증, 학습된 모델 품질 평가, 모델 검증이 추가로 필요하다.
- Deployment
오프라인에서 학습된 ML모델을 배포하는 수준에 그치는 것이 아니라, 새 모델을 재학습하고, 검증하는 과정을 자동화해야 한다.
- Production
일반적으로 알고리즘과 로직의 최적화를 통해 최적의 성능을 낼 수 있는 소프트웨어 시스템과 달리, ML 모델은 이에 더해서 지속적으로 진화하는 data profile 자체만으로도 성능이 저하될 수 있다.
즉, 기존 소프트웨어 시스템보다 더 다양한 이유로 성능이 손상될 수 있으므로, 데이터의 summary statistics를 꾸준히 추적하고, 모델의 온라인 성능을 모니터링하여 값이 기대치를 벗어나면 알림을 전송하거나 롤백을 할 수 있어야 한다.
- CI (Continuous Integration)
CI는 code와 components뿐만 아니라 data, data schema, model에 대해 모두 테스트되고 검증되어야 한다.
- CD (Continuous Delivery)
단일 소프트웨어 패키지가 아니라 ML 학습 파이프라인 전체를 배포해야한다.
- CT (Continuous Training)
ML 시스템만의 속성으로, 모델을 자동으로 학습시키고 평가하는 단계이다.
ML Project Process
- Data Extraction(데이터 추출)
데이터 소스에서 관련 데이터 추출 - Data Analysis(데이터 분석)
데이터의 이해를 위한 탐사적 데이터 분석(EDA) 수행
모델에 필요한 데이터 스키마 및 특성 이해 - Data Preparation(데이터 준비)
데이터의 학습, 검증, 테스트 세트 분할
Model Training(모델 학습)
다양한 알고리즘 구현, 하이퍼 파라미터 조정 및 적용
output은 학습fsf된 모델. - Model Evaluation(모델 평가)
holdout test set에서 모델을 평가
output은 모델의 성과 평가 metric. - Model Validation(모델 검증)
기준치 이상의 모델 성능이 검증되고, 배포에 적합한 수준인지 검증 - Model Serving(모델 서빙)
온라인 예측을 제공하기 위해 REST API가 포함된 마이크로 서비스
배치 예측 시스템
모바일 서비스의 embedded 모델
-Model Monitoring(모델 모니터링)
모델의 예측 성능을 모니터링
ML Manual Process 에서 ML Pipeline Automation 으로 개선
ML Manual Porcess
- 데이터 추출과 분석, 모델 학습, 검증을 포함한 모든 단계가 수동(Manual Process)
- 데이터 사이언티스트가 모델을 아티팩트로 전달하고, 엔지니어가 low latency로 프로덕션 환경에 배포
- 모델 변경이 자주 발생되지 않는 경우이며 CI/CD 없이 비정기적으로 수동 수행
- 로그나 모델의 예측 성능 등을 모니터링하지 않으므로 모델의 성능이 저하되거나 모델이 이상동작 하는 것을 감지할 수 없음
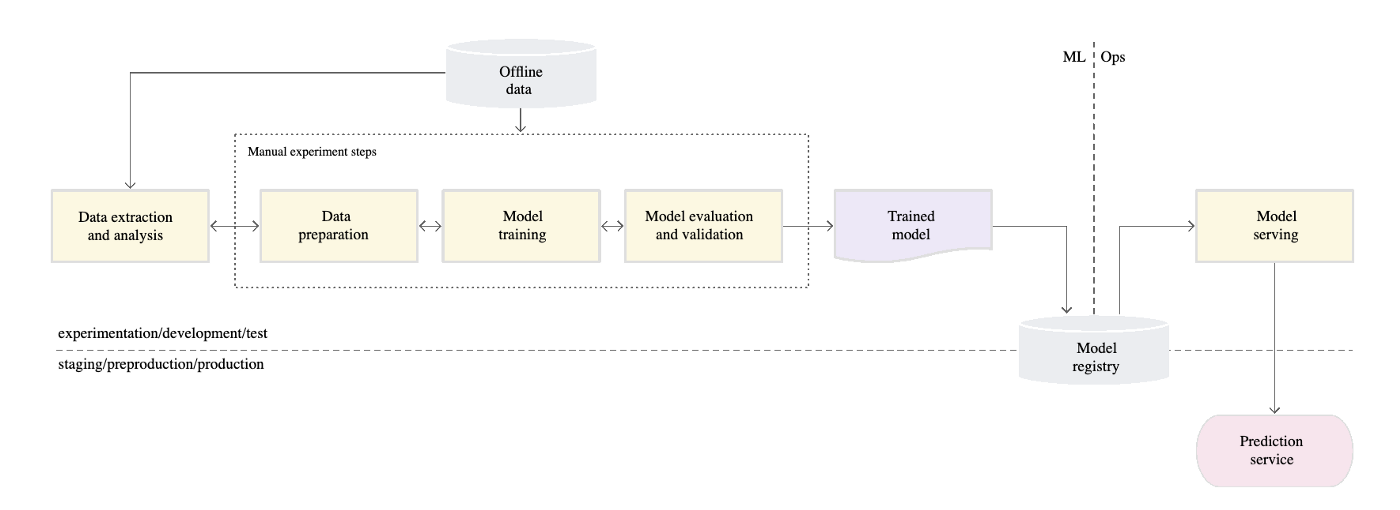 MLOps Level 0 : Manual process (from google cloud MLOps)
MLOps Level 0 : Manual process (from google cloud MLOps)
ML Pipeline Automation
- 자동화된 ML 파이프라인을 통해 지속적인 학습 프로세스 동작
- 모델 실험을 빠르게 반복하고, 전체 파이프라인을 프로덕션으로 빠르게 배포
- 개발 환경에서 쓰인 파이프라인이 운영 환경에도 그대로 쓰임. DevOps의 MLOps 통합에 있어 핵심적인 요소
- 새로운 데이터를 사용하여 프로덕션 모델의 자동 CT 수행
- 새로운 데이터로 학습되고 검증된 모델이 지속적으로 배포
- CT 필수 요소
- Data Validation
데이터 검증에서 실패(예상치 못한 데이터가 생성(Data schema skews))된 경우 신규 모델 배포 중지
데이터 검증 실패시 데이터 재검증 트리거
- Model Validation
모델이 새로운 데이터로 재학습을 마치고, 운영 환경에 반영되기 전에 평가되고 검증되도록 함 - Feature Store
학습과 서빙에 사용되는 모든 feature들을 저장하여 대용량 배치 처리와 low latency의 실시간 서빙을 모두 지원 - Metadata management
ML 파이프라인의 실행 정보, 데이터 및 아티팩트의 계보 등을 저장 - ML Pipeline Trigger
모델을 재학습 시키는 파이프라인의 자동화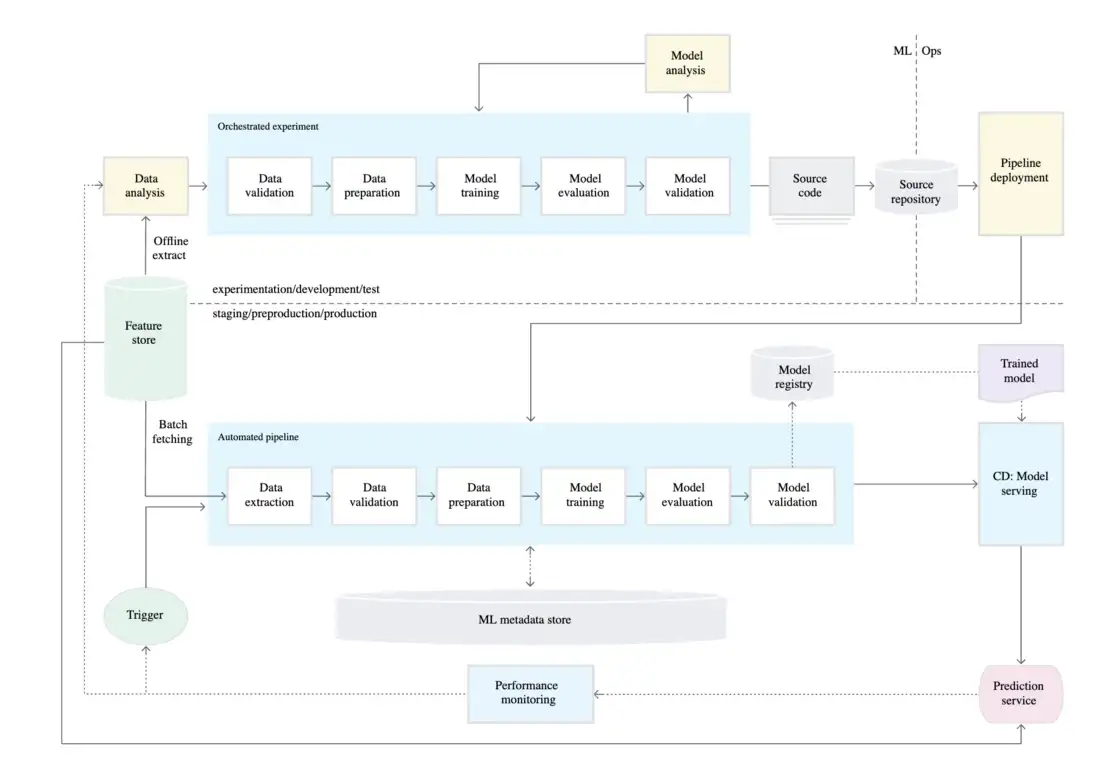 CT를 위한 ML 파이프라인 자동화 (from google cloud MLOps)
CT를 위한 ML 파이프라인 자동화 (from google cloud MLOps)
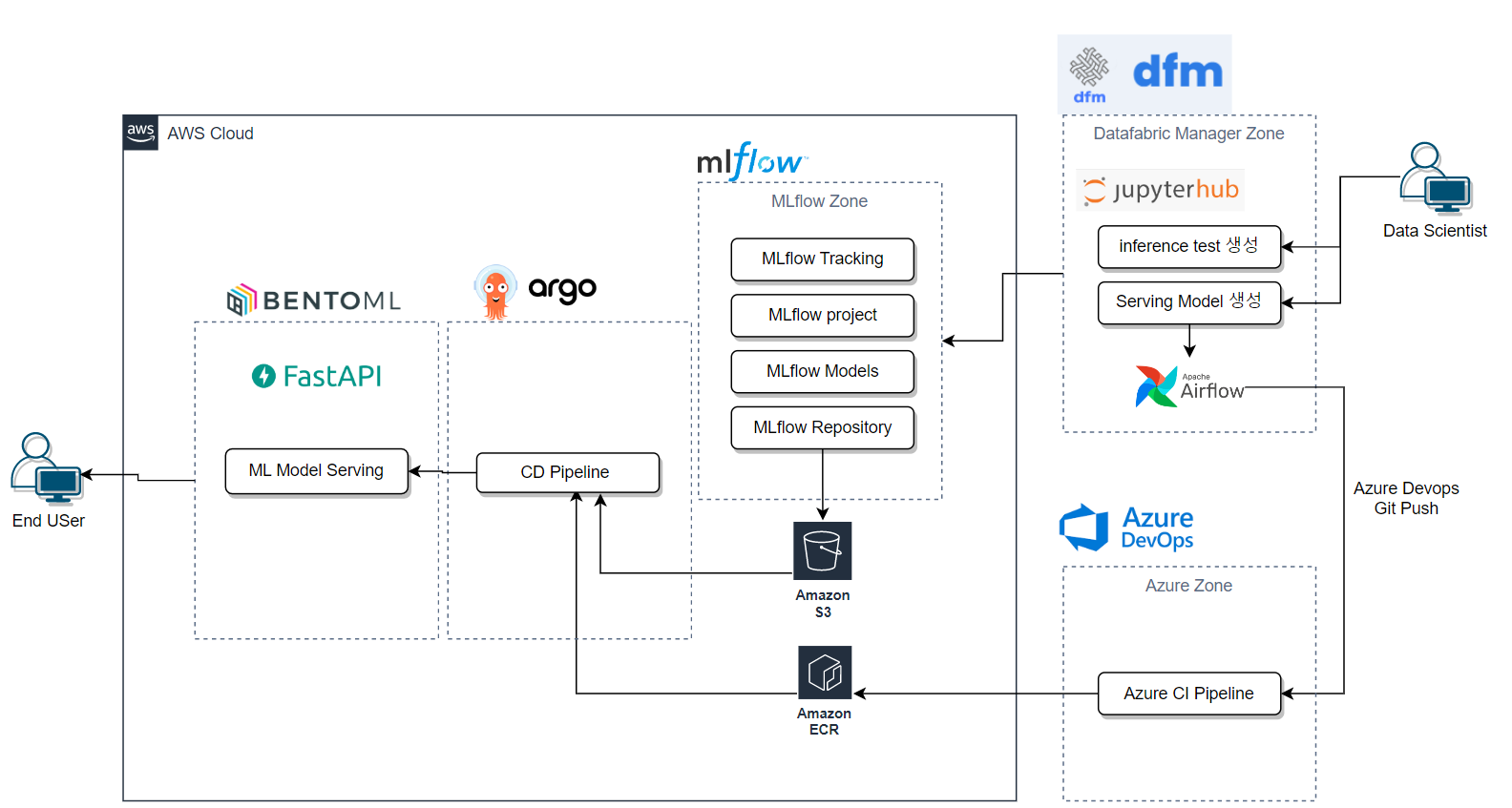
ML Component 오픈소스를 활용한 ML Pipeline

개발하는 곽선생