들어가며
AWS 신규 계정 생성 후 서버 세팅을 거의 마무리했다. 기대를 하며 postman으로 서버에 요청을 날려봤지만 돌아온 것은 503 에러였다.
오류
503 Service Temporarily Unavailable
구글링해보니 크게 두 가지 경우의 원인이 있는 것 같다.
대상그룹
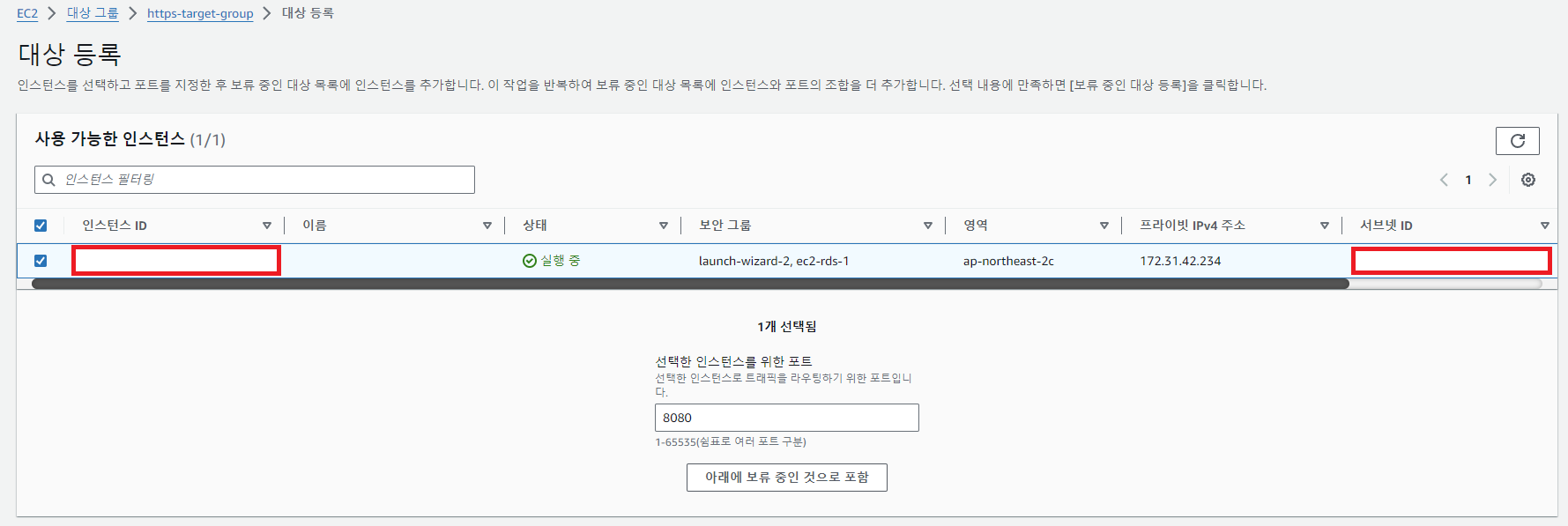
로드밸런서의 대상 그룹에 등록된 대상이 없을 때 503 에러가 발생할 수 있다. 나는 대상그룹에 사용할 EC2 인스턴스를 등록해준 후 해결되었다. 포트는 별도로 설정하지 않았으므로 스프링의 기본 사용 포트인 8080으로 해주었다.
가용영역
EC2 인스턴스와 로드밸런서의 가용 영역(AZ; availability zone)이 다른 경우에도 같은 오류 메세지를 출력하는 것 같다. EC2 또는 로드밸런서 인스턴스 삭제 후 가용영역이 일치하게 재생성 해야한다.
502 Bad Gateway
503 문제를 해결했더니 다음에는 502 에러가 발생했다.
로드밸런서

이 문제도 로드밸런서가 원인일 가능성이 높다고 해서 확인해보았다. EC2 - 로드밸런싱 - 대상 그룹 페이지의 아래쪽에서 확인할 수 있다. (현재 스샷은 "Healthy" 상태이지만 오류가 발생했을 때에는 "Unhealthy" 상태였다.)

대상 그룹의 "Healthy" 상태 검사 방법은 위의 설정 화면처럼 일정 주기마다 정해진 경로로 요청을 보낸 후, 200 status code를 받아야 한다. 요청 간격이나 제한 시간, 몇 번 연속으로 성공해야 되는지 등은 임의로 편집할 수 있다.
@RestController
@RequestMapping("/aws")
public class LoadbalancerHealthController {
@GetMapping("")
public ApiResponse<?> successHealthCheck() {
return ApiResponse.createSuccessWithNoContent(ResponseCode.LOADBALANCER_HEALTH_CHECK_SUCCESS);
}
}기본 상태확인 요청 경로는 /이지만 나는 /aws 경로로 GET 요청이 들어오면 처리하는 controller를 구현하여 200 응답을 받을 수 있도록 해주었다.
서버 프로그램 실행 확인
위에서 대상 그룹 설정을 수정하고 전용 controller를 구현했음에도 Unhealthy 상태에서 바뀌지 않았다. 현재 CodeDeploy를 사용하여 서버를 배포&실행하고 있었기 때문에 이를 직접 확인하기 위해 EC2 인스턴스에 연결했다.
[ec2-user@ip-172-31-42-234 ~]$ ps -ef | grep java
ec2-user 44611 44118 0 21:17 pts/0 00:00:00 grep --color=auto javaEC2 인스턴스에서 서버 프로그램이 정상적으로 실행되고 있는지 확인하기 위해서 명령어를 입력해봤지만 프로그램은 실행되지 않고 있었다. 정상 케이스는 jar 파일이 실행되고 있어야 했다.
java -jar -Dspring.profiles.active=aws imad-webapp.jar
...
Factory method 'redisConnectionFactory' threw exception; Host name must not be null or empty여러 yml 중 "aws" 프로필을 활성화하여 스프링 부트 서버를 실행해보았는데, Redis 관련 에러가 발생했다. 아차, 개발 코드에 Redis 의존성과 코드를 추가해놓고 AWS에는 설정을 하지 않고 있었다. 이 때문에 서버가 실행되지 못하고 있던 것이었다. 이를 해결한 내용은 해당 포스트를 확인하자.
EC2 연결성 검사 실패

서버 프로그램 정상 동작까지 확인했지만, 여전히 502 에러를 뱉고 있었다. EC2 인스턴스를 확인해보니 상태 검사가 실패했었다.

https://repost.aws/ko/knowledge-center/ec2-linux-status-check-failure
AWS에서 EC2는 두 가지 상태 확인을 사용하여 인스턴스의 상태를 모니터링한다.
- 시스템 상태 확인
인스턴스의 기본 하드웨어 관련 문제를 감지한다. 네트워크, 하드웨어 또는 소프트웨어 문제로 인해 기본 하드웨어가 응답하지 않거나 연결할 수 없는 경우, 시스템 상태 확인이 실패한다. - 인스턴스 상태 확인
인스턴스 상태 확인 실패는 인스턴스에 연결할 수 없음을 나타낸다. 다음과 같은 일반적인 문제로 인해 인스턴스 상태 확인이 실패한다. :- 운영 체제(OS)를 부팅하지 못함
- 볼륨을 올바르게 마운트하지 못함
- CPU 및 메모리 소진
- 커널 패닉
- 네트워크 장애
정확한 원인을 파악하기 위해서 작업 - 모니터링 및 문제 해결 - 시스템 로그 가져오기에서 로그를 확인해보았다.
[413868.634744] systemd-sysv-generator[207228]: SysV service '/etc/rc.d/init.d/cfn-hup' lacks a native systemd unit file. Automatically generating a unit file for compatibility. Please update package to include a native systemd unit file, in order to make it more safe and robust.
[413868.653192] zram_generator::config[207230]: zram0: system has too much memory (949MB), limit is 800MB, ignoring.
[413869.827043] systemd-sysv-generator[207294]: SysV service '/etc/rc.d/init.d/cfn-hup' lacks a native systemd unit file. Automatically generating a unit file for compatibility. Please update package to include a native systemd unit file, in order to make it more safe and robust.
[413869.869157] zram_generator::config[207296]: zram0: system has too much memory (949MB), limit is 800MB, ignoring.여러 시스템 관련 로그가 있었는데, 그 중 의심가는 부분이 위의 내용이다. 읽어봤을 때 메모리 부족 문제로 추측된다. 먼저 어떤 것 때문에 발생하지 않았던 메모리 부족 문제가 발생했는지 원인을 파악하고, 필요하다면 스왑 메모리 설정을 하려고 했다. 이를 위해 EC2 인스턴스를 재부팅 했는데...
문제가 해결되버렸다. 재현도 안 되고 연결성 검사가 실패했을 때에는 인스턴스에 접속도 timeout 에러가 발생하며 되지 않았기 때문에 터미널에서 램 할당 내역도 볼 수 없었다. 가장 의심되는건 직전에 ElastiCache와 연결 테스트를 하기 위해 redis를 실행했던 것인데... 당장은 보류 상태로 둬야할 것 같다.
어쨌든 인스턴스 재부팅 후 연결성 검사도 정상적으로 통과했고, 대상 그룹의 상태 검사도 "Healthy" 상태로 바뀌었다. 추후 필요하다고 판단된다면 스왑 메모리 설정도 해주려고 한다.
참고
