들어가며
지난 5월 27일부터 내일배움캠프에서 진행하는 최종 프로젝트 기간이 시작됐다. 길어야 1~2주 안에 끝마쳐야 했던 기존 개인, 팀 프로젝트와 달리 이번에는 약 한 달 동안 진행하게 된다.
짧지 않은 기간동안 진행되는 만큼, 캠프 측에서 팀원을 지정해주던 이전 프로젝트들과 달리 이번에는 직접 정할 수 있었다. 나는 좀 특이하게도 같은 조를 해봤던 사람들이 아니라 모르는 분들이 있는 팀에 합류해서 걱정이 조금 됐었는데, 지금은 내가 그런 걱정을 했었나 싶을 정도로 만족하는 중이다.
어쨌든, 앞으로 최종 프로젝트를 하면서 겪은 문제나 생각들, 구현한 기능들에 대해 작성해 나가려고 한다. 사실 대략적인 내용은 이미 따로 정리하고 있었지만, 바쁘거나 주말에는 쉬고 싶다는 핑계로 계속 미루다보니 이제서야 쓰기 시작한다. 후딱후딱 써서 현재 진행 상황과 싱크를 맞추기 전까지는 거의 매일 글을 작성할 것 같다.
이 글에서는 프로젝트 주제 선정과 기획 과정, 의사결정 과정 등 개발 내용보다는 사설이 좀 많을 것 같다.
프로젝트 기획
주제 선정
최종 프로젝트 기간이 시작되기 전부터 팀원들끼리 미리 모여서 주제에 대해 의논했었다. 티켓팅 사이트, 그룹웨어, 팀 매칭 플랫폼, 음성 메신저 프로그램, 지역 상인 중계 플랫폼 등 다양한 이야기가 나왔는데, 그 중 코딩 테스트 사이트가 주제로 선정됐다. (내가 냈던 주제라서 솔직히 기분 좋았다.)
코딩 테스트 사이트를 최종 프로젝트 주제로 정하게 된 이유는 다음과 같다.
1️⃣ 익숙한 도메인이다.
다들 개발자 지망생이니 만큼 코딩 테스트 서비스를 이용한 경험이 최소 한 군데 이상은 있었기 때문에, 도메인에 대해 따로 알아보거나 이해할 시간이 다른 주제들에 비해 덜 필요했다. 레퍼런스들도 많았고.
그러나 이 말은 경쟁자가 많기도 하다는 뜻이다. 그래서 다른 서비스들과 차별화되는 특색을 만들려고 많은 아이디어가 나왔었다.
2️⃣ 주변에 잠재적 이용자들이 많다.
현재 수강하고 있는 것이 백엔드 부트캠프이므로, 관련자들은 모두 코딩 테스트를 한 번쯤은 해 본 사람들이다. 즉, 이 캠프의 수강생들과 튜터님, 매니저님들은 모두가 잠재적 고객, 공짜 테스터들이다.
서비스의 실제 고객을 받아본 경험도 중요하므로 이러한 부분 또한 큰 매력으로 다가왔다.
3️⃣ 기본적인 기능 외에도 확장 가능성이 많다.
단순히 문제를 풀고, 제출하고, 채점 받는다는 핵심 기능 외에도 다양한 기능들을 적용해볼 수 있다. 커뮤니티, 랭킹, 티어 시스템, 스터디그룹, 오답노트, AI 피드백, 통계 및 분석 등 접목할 수 있는 부분이 많았고 이는 팀원들로부터 프로젝트 주제에 대해 흥미를 이끌어내기에 충분했다.
결국 이런 팀 프로젝트에서 가장 중요한 것은 주제에 대한 흥미이기 때문이다. (라고 튜터님이 말씀하셨다.)
내가 맡은 역할
이 프로젝트에서 내가 맡은 역할은 커뮤니티와 알림 기능이다. 원래는 알림 기능만 있었는데, MVP 기준으로는 알림 쪽이 할 작업이 적기도 해서 다른 분 파트를 떼서 가져왔다.
사실 알림 기능은 별 다른 내용이 없을 것이라고 생각했는데, 튜터님과 이야기해보고 조사해보니 나름 흥미로운 주제가 많았다. 다음은 알림과 관련되어 최종 프로젝트에서 구현할 예정인 목록이다.
- scale-out 환경에서도 정상적으로 알림 기능이 동작하도록 구현
- API 서버와 알림 서버를 분리했을 때를 고려한 구조 설계
- 알림 기능 구현 시 스프링 이벤트 대신 메시지큐 사용
- 클라이언트에게 메시지 전달 시 메시지큐 사용할 경우
- 메시지큐 스펙 조사 및 선정
- 일시적으로 많은 트래픽이 몰렸을 때 메시지 유실에 대한 대비책 마련
- 모니터링 및 대응 (서버 증설, 장애 복구 등)
생각보다 해야할 내용이 많아서 기대가 된다.
프로젝트 아키텍처
프로젝트의 아키텍처는 3, 4일 정도의 회의를 거쳐 정해졌다.
결론부터 말하자면, 적용하려고 하는 아키텍처는 4 계층 아키텍처를 기반으로 헥사고날 아키텍처의 핵심 개념을 도입한 구조를 사용하기로 했다.
아키텍처 조사
프로젝트의 기반이 되는 아키텍처들에 대해 간단하게 조사해봤다.
4-tier layer Architecture
4계층 아키텍처는 시스템을 논리적인 계층으로 나누어 각 계층이 정해진 역할만 수행하도록 하는 방식이다.
- 표현 계층 (Presentation Layer) : 사용자와의 상호작용을 담당
- 응용 계층 (Application Layer) : 사용자의 요청을 받아 비즈니스 로직을 조정하고 도메인 계층에 작업을 위임한다. 유즈 케이스(사용자 시나리오)를 구현하는 계층이다.
- 도메인 계층 (Domain Layer) : 시스템의 핵심 비즈니스 로직과 규칙을 포함한다. 도메인 객체(Entity, VO)와 도메인 서비스가 여기에 속한다.
- 인프라스트럭처 계층 (Infrastructure Layer) : 데이터베이스, 외부 API 연동 등 외부 기술에 대한 구체적인 구현을 담당한다.
Hexagonal Architecture
헥사고날 아키텍처(또는 포트와 어댑터 아키텍처)는 비즈니스 로직(도메인)을 외부 기술로부터 분리하는 데 중점을 둔다.
- 포트 (Port) : 내부와 외부를 연결하는 인터페이스. 내부에 의해 정의되며, 외부와의 상호작용 방식을 규정한다.
- 어댑터 (Adapter) : 포트의 실제 구현체. 외부 기술을 비즈니스 로직에 맞게 변환하거나, 비즈니스 로직의 요청을 실제 기술로 구현한다.
우리 프로젝트에서는 헥사고날 아키텍처에서 "비즈니스 로직을 외부 기술로부터 분리"하는 개념을 가져와 도입했다.
스프링 환경에서는 의존성 역전 원칙(DIP)이 프레임워크 수준에서 자연스럽게 구현된다. 비즈니스 로직은 자신이 필요로 하는 기능(Port)을 인터페이스로 정의할 뿐, 그 실제 구현(Adapter)은 Spring 컨테이너가 런타임에 연결하므로 기술 종속성으로부터 분리된 설계가 가능해진다.
도입 이유
사실 기존에 익숙하던 3 계층 아키텍처를 버리고 새로운 아키텍처를 도입하는 것은 쉽지 않은 결정이었다. 낯선 구조이다보니 생산성도 떨어지고 많은 시행착오를 겪을 것이 훤했기 때문이다. 그럼에도 이를 도입하게 된 이유는 다음과 같다.
도메인 복잡성 증가에 대한 대응
아키텍처에 대해 본격적으로 의논하기 전 DB 설계를 먼저 했는데, MVP 기능만 고려했음에도 테이블이 20개는 가뿐히 넘었다. (현업에서 100~200개는 기본이라고 한다) 사용하던 테이블이 해봐야 10개를 간신히 넘겼던 기존 1주일짜리 프로젝트의 2배가 넘는다.
이렇게 많아진 도메인들을 Service라는 하나의 계층에서만 관리하기에는 책임이 너무 비대해지고 테스트와 유지보수가 어려워질 것이라고 판단했다. 따라서 도메인 로직과 애플리케이션 유스케이스를 명확히 분리하여, 더 유연하고 변경에 강한 구조를 만들려고 했다.
잦은 기술 교체 및 확장에 대한 유연성 확보
현재 프로젝트는 다양한 외부 기술 스택을 활용할 예정이다. 데이터베이스는 물론 메시지큐, 캐시, 외부 API 연동 등 여러 기술에 의존하게 된다. 그리고 앞으로도 고도화, 성능 최적화 등의 과정을 거치며 특정 기술을 다른 것으로 교체하거나 새로운 기술을 도입할 가능성이 매우 높다.
헥사고날 아키텍처의 포트와 어댑터 구조는 외부 기술에 대한 의존성을 분리하는 데 최적이다. 비즈니스 로직이 특정 기술이 아닌 추상화된 인터페이스(Port)에 의존함으로써, 외부 기술이 바뀌더라도 핵심 로직의 변경을 최소화할 수 있는 구조를 만들고 싶었다.
테스트 용이성
애플리케이션 서비스와 도메인 서비스를 분리하면 테스트의 목적을 명확하게 하고, 유지보수가 쉬운 테스트 코드를 작성할 수 있게 된다.
복잡한 비즈니스 로직을 가진 도메인 서비스는 외부 기술이 아닌 추상화된 인터페이스(port)에 의존하므로 단위 테스트로 빠르게 검증할 수 있다.
애플리케이션 서비스 테스트에서는 "DB에서 데이터를 잘 가져왔나? → 도메인 서비스에 잘 전달했나? → 결과는 잘 저장했나?" 와 같은 큰 그림의 '흐름'만 검증하면 된다. 이미 도메인 단위 테스트에서 모든 경우의 수를 검증했기 때문에, 통합 테스트에서 모든 비즈니스 규칙을 다시 테스트할 필요가 없다.
적용 및 구현
실제 프로젝트 적용한 방법, 패키지 구조, 코드 작성 시 주의사항 등에 대해 정리해봤다.
패키지 구조
my.ezcode.codetest
├── common // 🌎 공통 관심사 (AOP, 예외 처리, 설정)
│ ├── config
│ └── exception
├── presentation // 💻 표현 계층 (컨트롤러)
├── application // 🚀 응용 계층 (UseCases)
│ └── service
│ └── dto
├── domain // 🧠 도메인 계층 (Core Business Logic)
│ ├── model // 도메인 모델 (Entity, VO)
│ ├── service // 도메인 서비스
│ └── port // 포트 (Interface)
│ └── exception // 도메인 예외
└── infrastructure // 🔌 인프라 계층 (Outbound Adapter)
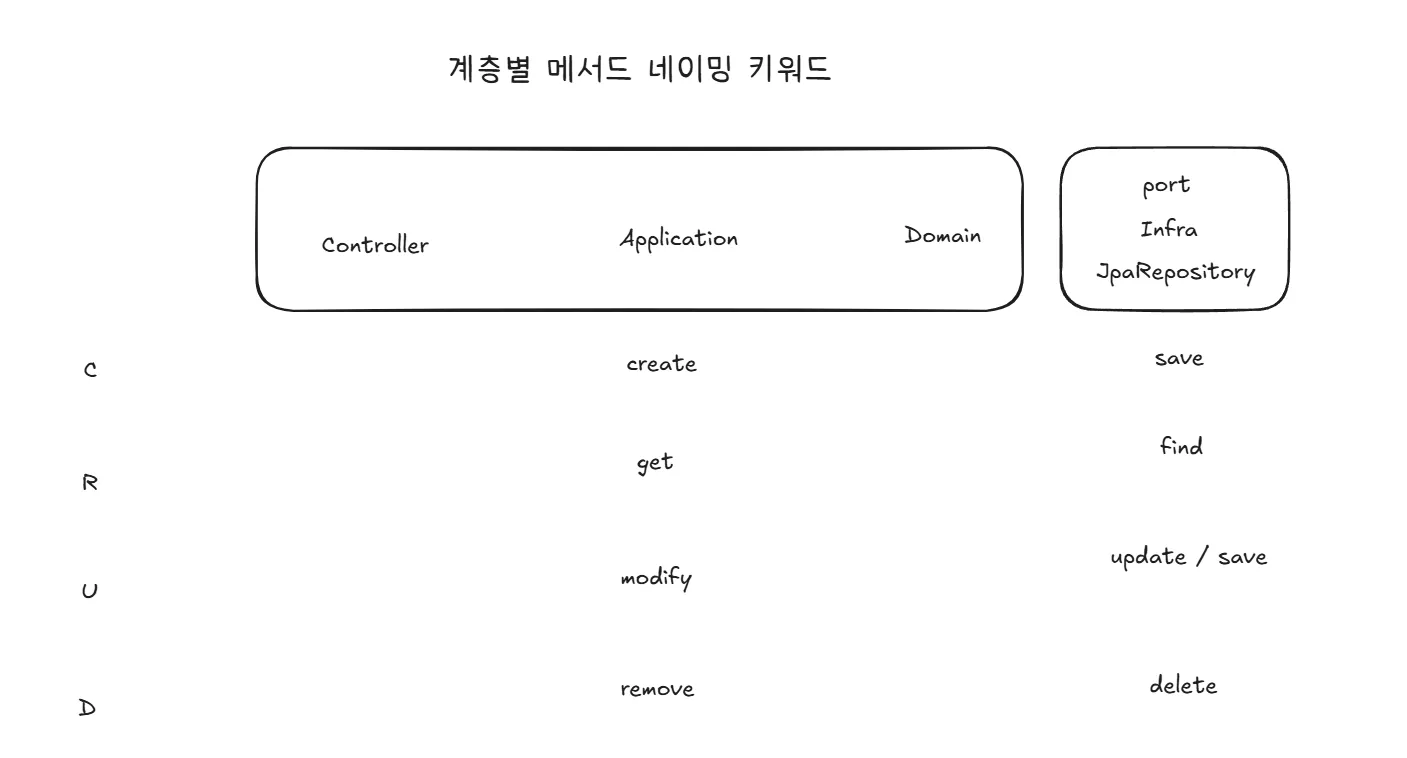
└── persistence // 영속성 (JPA repository, querydsl 등)계층별 메서드 네이밍
계층에 상관 없이 모두 같은 메서드 네이밍을 사용하면 어디서 사용되는 것인지 혼동될 수 있다. 그래서 팀원들과 논의해서 계층별로 사용하는 메서드의 단어를 일관성 있게 통일했다. 우선은 CRUD만 정해진 상태다.
핵심 개발 원칙
아래 내용은 팀원들과 합의 하에 정해진 내용으로, "이게 정답이다"라는 이야기는 아니다. 우리 프로젝트에서는 이 내용들을 중점적으로 신경 쓰면서 개발한다~ 라고 보면 될 것 같다.
1️⃣ Application vs Domain 계층 명확히 구분하기
계층별로 역할과 책임이 다르기 때문에 이를 명확히 구분해야 한다.
- Application 계층
- 사용자의 요청을 받아 하나의 유즈 케이스를 책임지고 지휘(오케스트레이션)
- 트랜잭션 관리, 이벤트 발행, 도메인 객체나 서비스에게 로직 위임 등을 수행
- Domain 계층
- 순수한 비즈니스 규칙을 정의하고, 외부 세계와의 모든 통신에 대한 요구사항(Port 인터페이스)을 명세
- "자신이 작성한 토론글만 수정, 삭제할 수 있다.", "자신이 쓴 글에는 알림을 보내지 않는다."와 같은 핵심 도메인 정책을 결정
- 도메인 서비스
- 하나 이상의 도메인 모델을 사용하여 복잡한 비즈니스 로직을 처리
- 이 과정에서 추가 데이터가 필요하다면, 자신이 정의한 port를 통해 직접 DB에 접근(호출)할 수 있음
- 포트
- 외부 기술과의 연동을 위한 인터페이스를 이곳에 정의
- 도메인이 "나는 이런 기능이 필요해"라고 선언하는 명세서의 역할
2️⃣ Port 호출 주체
우리 프로젝트에서는 도메인 계층 뿐만 아니라 일부 애플리케이션 계층에서도 Port를 호출할 수 있도록 예외를 두고 있다.
보통 도메인 계층에는 없고 인프라 계층에만 존재하는 기능을 호출할 때, 이러한 예외가 적용된다. 이에 대한 자세한 설명은 나중에 알림 기능 구현과 관련된 글을 작성할 때 하겠다.
3️⃣ Repository의 Optional 예외 처리는 Domain 서비스에서
Repository가 findById 등으로 조회했을 때 데이터가 없는 경우, Optional.empty()를 반환하는 것은 정상적인 상황이다. "데이터가 없다"는 사실을 알리는 것이 Repository의 책임이기 때문이다. 그리고 이 "데이터 없음"을 비즈니스 예외로 해석하고 던지는 책임은 도메인 서비스에 있다.
유즈 케이스인 애플리케이션 서비스 입장에서는 "데이터가 없다"라는 케이스 자체보다, "비즈니스 로직 수행이 실패했다"는 결과에 더 관심이 있다. 따라서 애플리케이션 서비스는 "ID에 해당하는 데이터를 찾아 비즈니스 로직을 수행하라"고 위임할 뿐, 그 과정에서 발생하는 "데이터 없음" 상황은 도메인 서비스가 처리하는 것이 책임의 분리에 더 적합하다.
4️⃣ Application 서비스는 유즈 케이스의 '시나리오'가 되어야 한다
애플리케이션 서비스의 메서드는 그 자체로 하나의 유즈 케이스 흐름을 설명하는 시나리오여야 한다. 코드를 읽는 것만으로 비즈니스 요구사항이 어떻게 흘러가는지 파악할 수 있어야 한다.
이를 위해서는, Application 서비스가 '어떻게(How)'를 다루지 않고 '무엇을(What)' 할지만을 나열해야 한다. if/else 분기, for 루프를 통한 계산 등 모든 잡다한 구현과 세부적인 처리 절차는 도메인 서비스나 도메인 모델에게 전부 위임한다.
튜터님께 피드백 받아 리팩토링 한 코드의 전후를 비교해보자. 아래 코드가 훨씬 보기 편하고 흐름을 파악하기 쉽다. 만약 연속해서 같은 도메인 서비스를 사용 중이라면 하나의 메서드로 묶는 것을 고려해보면 좋다.
// Bad : 세부 구현이 노출되어 있어 유즈 케이스의 흐름을 파악하기 어렵다.
@Transactional
public ReplyResponse createReply(
Long problemId,
Long discussionId,
ReplyCreateRequest request,
Long userId
) {
User user = userDomainService.getUserById(userId);
Discussion discussion = discussionDomainService.getDiscussionById(discussionId);
discussionDomainService.validateProblemMatches(discussion, problemId);
Reply parent = null;
if (request.parentReplyId() != null) {
parent = replyDomainService.getReplyById(request.parentReplyId());
replyDomainService.validateDiscussionMatches(parent, discussion);
}
Reply reply = replyDomainService.createReply(
ReplyCreateRequest.toEntity(discussion, user, parent, request)
);
return ReplyResponse.fromEntity(reply);
}// Good : 유즈 케이스의 시나리오가 한눈에 보인다.
@Transactional
public ReplyResponse createReply(
Long problemId,
Long discussionId,
ReplyCreateRequest request,
Long userId
) {
User user = userDomainService.getUserById(userId);
Discussion discussion = discussionDomainService.getDiscussionForProblem(discussionId, problemId);
Reply reply = replyDomainService.createReply(discussion, user, request.parentReplyId(), request.content());
return ReplyResponse.fromEntity(reply);
}5️⃣ 외부 기술 구현 방법
1) [Domain] 또는 [Application] Port 정의 : domain.port 패키지에 도메인이 필요로 하는 기능의 인터페이스를 먼저 정의한다. 메서드 파라미터와 반환 타입은 순수 도메인 객체를 사용한다.
2) [Infrastructure] Adatper 구현 : infrastructure 패키지에 위에서 정의한 Port 인터페이스의 구현체를 작성한다. 이 클래스는 실제 외부 기술(JPA, Redis, RestTemplate) 등을 사용한다.
3) Infrastructure 계층에서 작성한 구현체는 사용 주체(Application 또는 Domain)가 DI 받아 사용한다.
구현 예시
실제 프로젝트에서 어떻게 구현하고 있는지 예시를 가져와봤다. 패키지명, 클래스명 등은 팀원들에게 익숙한 용어들을 사용했다. 이 부분은 나중에 리팩토링 과정에서 변경될 수 있다.
아래 내용에서는 토론글(discussion)을 저장하는 과정을 설명한다.
presentation / DiscussionController.java
@RestController
@RequestMapping("/api/problems/{problemId}/discussions")
@RequiredArgsConstructor
public class DiscussionController {
private final DiscussionService discussionService;
@PostMapping
public ResponseEntity<DiscussionResponse> createDiscussion(
@PathVariable Long problemId,
@RequestBody @Valid DiscussionCreateRequest request,
@AuthenticationPrincipal AuthUser authUser
) {
return ResponseEntity
.status(HttpStatus.CREATED)
.body(discussionService.createDiscussion(problemId, request, authUser.getId()));
}
...
}사용자의 응답을 받아 처리하기 위해 애플리케이션 계층의 서비스를 호출한다.
application.service / DiscussionService.java
@Service
@RequiredArgsConstructor
public class DiscussionService {
private final DiscussionDomainService discussionDomainService;
private final UserDomainService userDomainService;
private final ProblemDomainService problemDomainService;
private final LanguageDomainService languageDomainService;
@Transactional
public DiscussionResponse createDiscussion(Long problemId, DiscussionCreateRequest request, Long userId) {
User user = userDomainService.getUserById(userId);
Problem problem = problemDomainService.getProblem(problemId);
Language language = languageDomainService.getLanguage(request.languageId());
Discussion discussionEntity = DiscussionCreateRequest.toEntity(user, problem, language, request);
return DiscussionResponse.fromEntity(discussionDomainService.createDiscussion(discussionEntity));
}
...
}여러 도메인 서비스를 조합하여 유즈 케이스를 구현한다. @Transactional을 사용해 트랜잭션을 관리한다.
애플리케이션 서비스의 코드를 읽는 것만으로도 서비스의 핵심 흐름을 파악할 수 있도록 코드를 작성해야 한다.
ex) 각 도메인의 entity 조회 -> Discussion entity 생성 -> 데이터 저장, 저장된 데이터를 DTO로 변환 후 반환
이를 위해 유효성 검증, 권한 검사 등은 도메인 서비스에게 위임한다.
domain.service / DiscussionDomainService.java
@Service
@RequiredArgsConstructor
public class DiscussionDomainService {
private final DiscussionRepository discussionRepository;
public Discussion createDiscussion(Discussion discussion) {
return discussionRepository.save(discussion);
}
...
}단순히 데이터를 저장하는 데에는 자체적인 비즈니스 로직이 따로 없으므로 바로 repository(port)를 호출한다. 만약 데이터를 저장하기 전 내부 값을 검증하는 등의 로직이 필요하다면 애플리케이션 서비스가 아닌 도메인 서비스의 이 메서드 안에서 구현될 것이다.
domain.port / DiscussionRepository.java
public interface DiscussionRepository {
Discussion save(Discussion discussion);
Optional<Discussion> findById(Long discussionId);
Page<Discussion> findAllByProblemId(Long problemId, Pageable pageable);
void updateDiscussion(Discussion discussion, Language language, String content);
void deleteDiscussion(Discussion discussion);
}도메인이 필요한 기능들을 선언하는 명세서 역할을 한다. 도메인 입장에서는 스프링의 DI 덕분에 이 메서드들이 어떻게 구현되는지 알지 못한다. (의존성 분리)
infrastructure.persistence / DiscussionRepositoryImpl.java
@Repository
@RequiredArgsConstructor
public class DiscussionRepositoryImpl implements DiscussionRepository {
private final DiscussionJpaRepository discussionJpaRepository;
@Override
public Discussion save(Discussion discussion) {
return discussionJpaRepository.save(discussion);
}
...
}도메인 계층에서 선언한 Port의 구현체를 작성한다. DiscussionJpaRepository 대신에 JdbcTemplate 등을 통해 다른 방법으로 데이터를 저장할 수 있다. 이러한 기술 변경이 있어도 애플리케이션, 도메인 계층에는 전파되지 않는다.
마치며
새로운 아키텍처에 팀원들 다 같이 도전해보기로 했다. 비록 생산성은 떨어지겠지만 시행착오를 겪고 대가리 깨져가면서 배울 수 있는 부분들이 많다고 생각했기 때문이다.
그리고 이전까지는 익숙한 3-Layer 아키텍처를 관성적으로 사용하고 다른 아키텍처에 대해서는 따로 알아보지 않고 있었는데, 이번 기회에 관련 공부를 하게 된 것 같다.
참고
