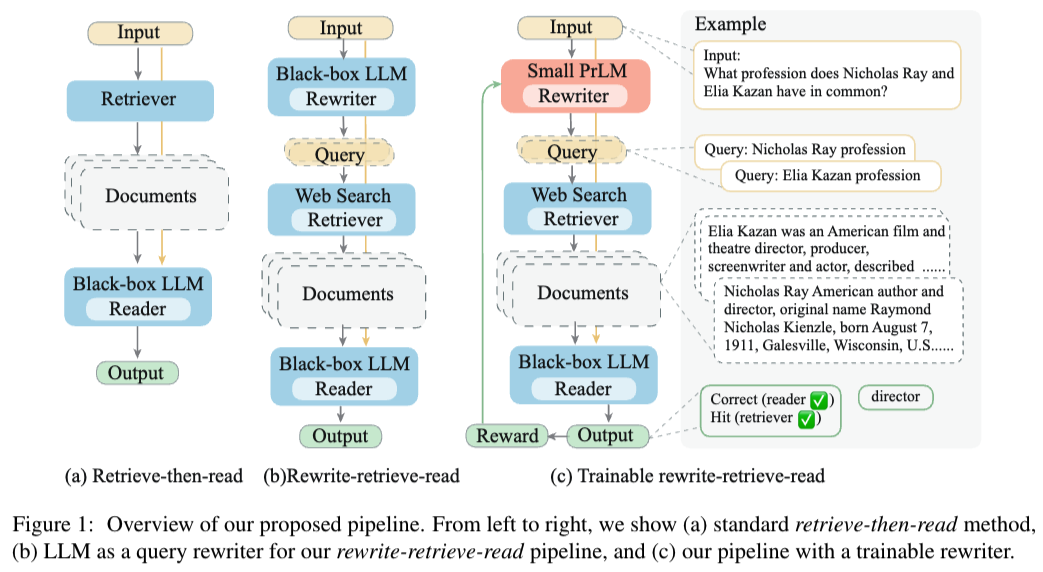
[논문 리뷰] Query Rewriting for Retrieval-Augmented Large Language Models
- Rewrite-Retrieve-Read 라는 새로운 프레임워크 소개
- RAG 성능 향상을 목표로 함.
- 기존의 검색 후 읽기 접근 방식(Retrieve-Then-Read)에서 쿼리 재작성을 추가함.
- 프로세스
- LLM에 쿼리를 생성하라는 메세지를 포함시킴.
- 이 쿼리로 웹 검색을 하고, 관련 컨텍스트를 검색함.
- sLLM을 Rewriter 모델로 사용하며 LLM 리더의 피드백을 기반으로 강화학습을 사용하여 학습함.
-
기존 연구
- Retreiver
- Sparse Retreiver (Chen et al., 2017)
- 대량의 텍스트에서 특정 키워드를 찾음.
- 사용자가 입력한 단어와 정확히 일치하는 단어를 찾아줌
- Dense Retreiver (Karpukhin et al., 2020)
- 단어의 의미로부터 관련된 텍스트를 찾음.
- Sparse Retreiver (Chen et al., 2017)
- (Izacard et al., 2022)는 '검색'을 적용하면 더 적은 파라미터 LLM 모델로도 큰 모델과 비슷한 성능을 보인다고 했음. (검색의 중요성)
- Replug (Shi et al., 2023)
- LLM의 감독 하에 LLM이 더 좋은 답변을 제공할 수 있도록 적합한 문서를 찾도록 Dense Retriever를 학습 시킴.
- Directional Stimulus Prompting (Li et al., 2023)
- 작은 모델(small model)을 사용해서 LLM에 유용한 힌트 또는 '자극'을 제공하는 방법
- 힌트(자극): 주제 요약, 대화를 위한 행동 제안 키워드 제공 등
- LLM의 보상을 통해 학습됨.
- Retreiver
-
방법
-
Rewriter 1차 학습 (Warm-up)
- 데이터셋 구축
- 프롬프팅으로 LLM에게 input question (x)에 대한 적절한 정보 검색 쿼리 를 예측하도록 함.
- (로 찾은 context를 활용한) LLM reader의 예측 결과 중 정답을 맞춘 데이터셋만 필터링함.
- 소괄호 부분은 논문에 없는 얘기임. 추정임.
- 그렇게 해서 만든 데이터셋 으로 rewriter 훈련
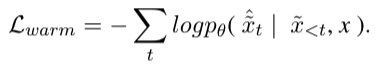
- 데이터셋 구축
-
Rewriter 2차 학습 (Reinforcement Learning; PPO)
- warm-up 된 를 initial policy model 으로 사용함.
- 현재 상태()는 입력 질문(x)와 이전 step까지의 쿼리토큰 예측값()이다.
- EOS 토큰이 나오면 한번의 에피소드는 끝난다.
- 보상은 retrieval과 reading을 마친 LLM reader의 prediction 점수로부터 계산된다.
- 은 retriever와 reader에게 모두 주입된다. (입력으로 사용된다.)
- 보상은 와 정답인 의 exact match와 F1점수로 계산된다.

-
Retriever
- Bing search engine (API) 을 사용함.
- BM25를 이용해서 query와 관련성이 높이고 문서 길이를 줄임.
-
Reader
- 사용한 frozen model: GPT3.5-turbo, Vicuna-13B
- 독해와 예측을 수행한다.
-
실험 설계
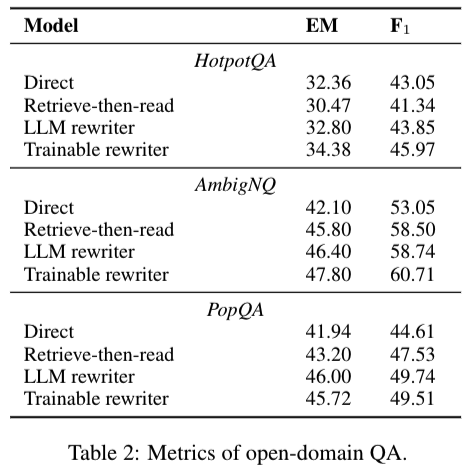
- 데이터셋
- Open-domain QA
- HotPotQA (Yang et al., 2018)
- AmbigNQ (Min et al., 2020)
- PopQA (Mallen et al., 2022)
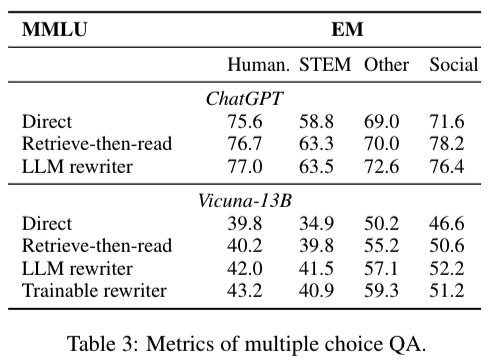
- Multiple-choice QA
- Massive Multi-task Language Understanding (MMLU) (Hendrycks et al., 2021)
- Open-domain QA
- Baselines
- Direct
- 증강 없는 표준적인 in-context learning
- Retrieve-then-read
- 표준 RAG
- Retrieved documents는 입력 질문과 concatenated됨.
- LLM as a frozen rewriter
- frozen LLM을 이용해서 query를 만든 Rewrite-Retrieve-Read 방법
- Trainable rewriter
- fine-tuned된 rewriter를 사용한 Rewrite-Retrieve-Read 방법
- Direct
- 데이터셋
-



AI 기술로 먹고 살기