
컨테이너 오케스트레이션(Container Orchestration)
컨테이너 오케스트레이션의 필요성
- 여러 컨테이너를 빌드 / 롤아웃 / 롤백 하려면?
- 각 컨테이너에 접속해서 수행 =>
번거로움- 각 컨테이너의 사용량 관리 ?
- 컨테이너의 상태를 관리하기 위해 모니터링 등 외부시스템 연결 =>
복잡- 각 컨테이너의 부하를 덜기 위해 ?
- 부하 대비가 필요한 서비스에 각각 모두 중간에 로드밸런서를 두어야 함 =>
반복 작업- 서비스 노출 ?
- public영역에 nGinX같은 프록시를 두어서 호스트에 따라 각 컨테이너에게 보내도록 설정
=>관리가 번거롭다(자동화 필요)- 서비스 이상, 부하 모니터링은 ?
- 컨테이너별로 직접 관리해줘야 함 =>
비효율적
컨테이너 오케스트레이션
- 개념
- 복잡한 컨테이너 환경을 효과적으로 관리하기 위한 도구
- 즉, 서버관리자가 하던 많은 일들을 자동화하고 편리하게 사용할 수 있게 해주는 도구
- 특징 1 : CLUSTER (
클러스터)
- 컨테이너 하나하나를 관리하는 것이 아니라, 클러스터단위로 추상화 해서 묶어서 관리
- 많은 클러스터들을 관리하기 위해서는 master를 둔다
- 클러스터 간 네트워크 통신을 위한 설정들 필요
- 특징 2 : STATE(
상태관리)
- 컨테이너의 상태 (레플리카 수 등등)를 자동으로 관리
- 특징 3 : SCHEDULING(
배포관리)
- 애플리케이션을 추가할 때, 기존의 노드의 상태를 통해서 기존 노드에 띄우거나 새로운 노드에 띄우는 것을 결정하고 관리
- 특징 4 : ROLLOUT / ROLLBACK (
버전관리)
- 각 노드의 배포의 버전 관리를 중앙에서 관리 / 자동화
- 특징 5 : SERVICE DISCOVERY (
서비스 등록 및 조회)
- 서비스를 등록하고 조회하는 절차를 중앙에서 관리 / 자동화
- 특징 6 : VOLUME (
볼륨 스토리지)
- 각 노드에 해당하는 스토리지 연결을 중앙에서 관리 / 유지보수
쿠버네티스(k8s) 기본 개념
[ 개요 ]
- k8s는 여러 서버로 구성된 클러스터 환경에서 컨테이너화 된 프로세스를 관리하기 위한
Container Orchestration
=> 다수의 서버 위에서 컨테이너의 전반적인 라이프사이클을 관리- 컨테이너 방식은 가상 머신 방식과 다르게 host OS를 공유
- 사용자는 개별 노드(
서버)를 직접 제어하지 않고 k8s라는추상화된 레이어를 통해 클러스터를 제어- 쿠버네티스는 모든 서버들을
Master/Worker노드로 구분
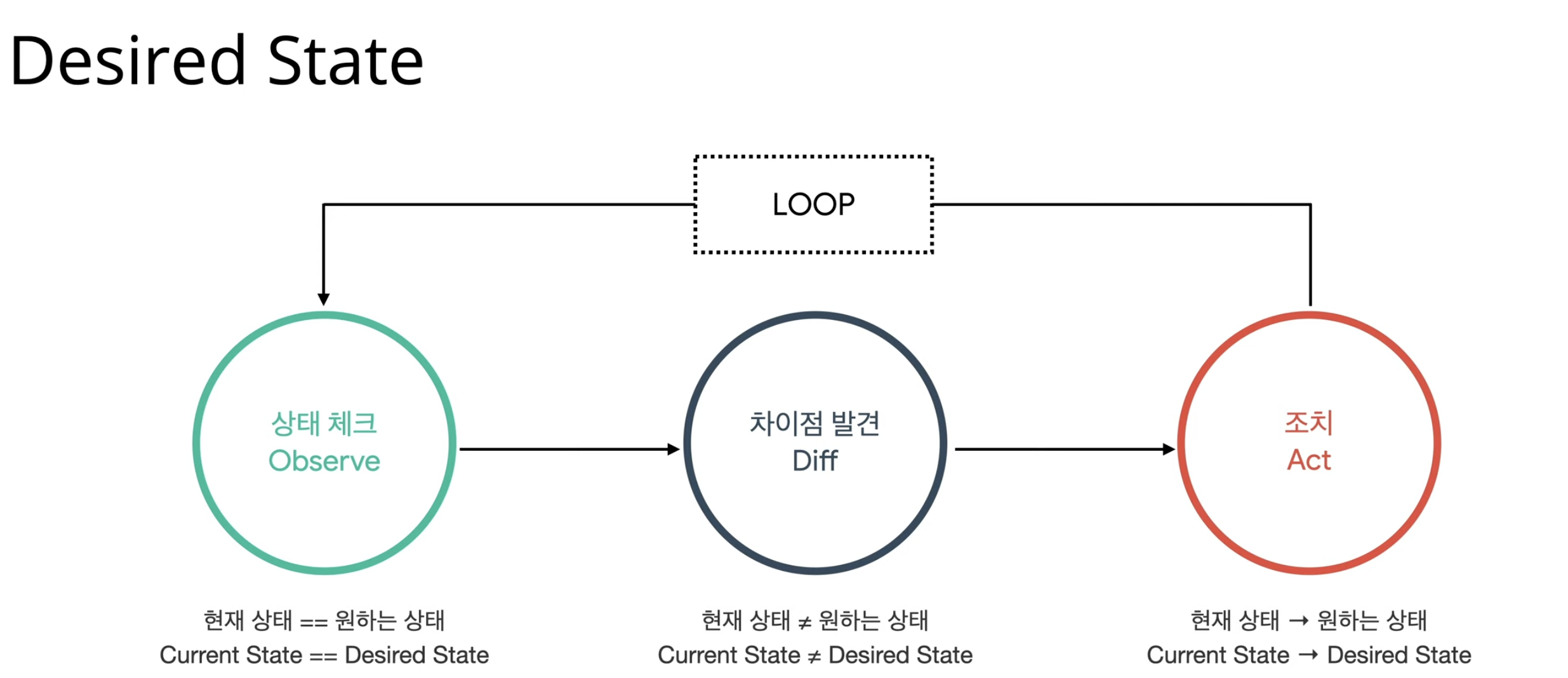
[ Desired State ]
Desired State즉, 바라는 상태라는 개념이 있다- 기본적인 쿠버네티스의 구동 원리의 핵심
- 내부적으로
Scheduler/Controller/Kubelet모두 이러한cycle을 통해etcd에 있는 데이터가 변경되면 감지- 사용자가 사전에 정의해둔 상태(바라는 상태)를 유지하기 위해 현재 상태에 정해진 특정 작업을 수행
[ Controller ]
- 현재 상태를
Desired State로 변경하는 주체control-loop라는 루프를 돌며 특정 리소스를 지속적으로 모니터링- 사용자가 생성한 리소스의 이벤트에 따라 사전에 정의된 작업(리소스 종류에 따라 상이)을 수행
- 하나의 쿠버네티스 리소스는 하나의 컨트롤러를 가진다
[ k8s resource ]
- k8s는 모든 것을 리소스(
resource)로 표현Pod/ReplicaSet/Deployment/Service/Ingress등 다양한 리소스가 존재- 각 리소스마다 세부 정의가 다르고, 그에 따른 역할과 동작이 상이
- 서로 포함하는 개념의 상위 / 하위 리소스 개념도 존재 ex)
Deployment > ReplicaSet > PodPod는 하나 이상의 컨테이너를 가지는 k8s 최소 실행 단위
[ 선언형 커맨드 ]
- k8s는 사용자가 직접 시스템의 상태를 바꾸지 않고,
바라는 상태(Desired State)를 선언적으로 기술하여 명령을 내리는 선언형(Declarative) 커맨드 방식을 지향- k8s리소스를 YAML 정의서(
description) 형식으로 구성
- 명령형(
Imperative) 커맨드와의 차이
- 명령형 커맨드
- 어떻게(
How)를 기술- ex) SQL 쿼리 =>
쿼리를 어떻게 테이블의 데이터를 질의할 것인가 ?- 선언형 커맨드
- 무엇을(
What)을 기술- ex) HTML 문서 =>
무엇을 해야하는지 기술 !
[ namespace ]
[ 개념 ]
- 클러스터를 논리적으로 분리하는 개념
- 물리적으로는 하나의 쿠버네티스 클러스터 위에 논리적으로 환경을 나누어 구성할 수 있다
[ namespace로 리소스 구분 ]
- 쿠버네티스 리소스를 구분하는 개념으로 적용
namespace 레벨 리소스
- 특정 namespace 안에 속하여 존재하는 리소스
- ex) 대부분의 k8s 리소스 (
Pod/ReplicaSet/Deployment/Service/Ingress등)클러스터 레벨 리소스
- namespace 영역에 상관 없이 클러스터 레벨에서 존재하는 리소스
- ex)
Node/PersistentVolume/StorageClass
[ k8s의 기본 namespace ]
default
- 기본 네임스페이스
- 아무런 옵션 없이 컨테이너를 만들게 되면
default로 설정kube-system
- 쿠버네티스의 핵심 컴포넌트들이 들어있는
namespace- 네트워크 설정 / DNS 서버 등의 역할을 하는 컴포넌트가 존재
kube-public
- 외부로 공개 가능한 리소스를 담고 있는
namespacekube-node-lease
- Node가 살아있는지 Master에게 알리는 용도로 존재하는
namespace
[ Label & Selector ]
Label: k8s 리소스에 존재하는key-value형식의 태그 정보Selector: 태깅한Label을 찾기 위한 것Label과Selector를 이용한 매커니즘을 통해 k8s 리소스간 관계를느슨하게 연결하여 유연한 구조를 가진다- 특정 리소스(또는
리소스 그룹)에명령을 전달하거나정보를 확인하고 싶을 때라벨링 시스템이용
[ 서비스 탐색 ]
- 사용자가 서비스에 접근하기 위해 끝점(
Endpoint)의 접속 정보를 탐색하는 것- 동일하게, 클러스터 내에서 각 노드에 상관 없이 통신하기 위해서는 서비스 끝점(
Service Endpoint)가 필요- k8s에서는
DNS기반의 서비스 탐색을 지원
=> 도메인 주소를 기반으로 서비스에 접근 가능
=> k8s에서 서비스 탐색 기능은 서비스(Service) 라는 k8s 리소스를 통해 지원
[ 설정 관리 ]
- k8s에서는 컨테이너를 실행할 때 필요한 설정값 및 민감 정보(
credentials)를 플랫폼 레벨에서 관리하는 매커니즘을 제공ConfigMap/Secret리소스를 통해 컨테이너의 설정을 관리
아키텍처
ref : https://kubernetes.io/ko/docs/concepts/overview/components/
[ Master ]
[ 개요 ]
- k8s를 클러스터를 구성하는 핵심 컴포넌트들이 존재
- 마스터는 단일 서버로 구성될 수도 있고, 고가용성을 위해 여러 서버로 클러스터 마스터로 구성될 수도 있다
- 핵심 컴포넌트
kube-apiserver: 마스터로 전달되는 모든 요청을 받는 REST API 서버etcd: 클러스터 내 모든 메타 정보를 저장하는 저장소kube-scheduler: 사용자 요청에 따라 적절하게 컨테이너를 워커(worker) 노드에 배치하는 스케줄러kube-controller-manager
: 현재 상태와 바라는 상태를 지속적으로 확인하며 특정 이벤트에 따라 특정 동작을 수행하는 컨트롤러cloud-controller-manager
: 클라우드 플랫폼(AWS / GCP / Azure)에 특화된 리소스를 제어하는 클라우드 컨트롤러
[ kube-apiserver ] - API 서버
- 다른 모든 컴포넌트들에서 오는 이벤트를 받아들이고 적절히 응답
- 반드시
api서버를 통해서 컴포넌트들이 소통하고etcd에 접근하게 된다- 사용자는
kubectl을 이용하여 api서버에 명령을 보내고 응답을 받을 수 있다- 마스터와 통신한다 == api 서버와 통신한다
[ etcd ] - 저장소
- 쿠버네티스 클러스터에 필요한 모든 데이터를 저장하는 DB 역할
- RDB가 아닌 분산형
key-value저장소- api서버 백엔드에 위치하여 필요한 데이터를 api서버에게 제공하거나 중요한 데이터는
key-value로 저장- 고가용성을 위해
etcd 클러스터를 구축하여 안정성을 증대시킬 수 있다
[ kube-scheduler ]
- 전반적인 컨테이너 스케줄링 담당
- 지속적으로 아직 실행되지 못한 컨테이너가 있는지 확인
- k8s위에 새로운 컨테이너를 실행할 때 노드 상태 / 요청 리소스량 / 제약조건에 따라 적절한 서버(
노드)를 선택
[ kube-controller-manager ]
- 컨트롤러를 하나의 컴포넌트로 합친 것
- 지속적으로
control-loop를 돌며 현재 상태(current state)와 바라는 상태(desired state)를 비교- 바라는 상태(
desired state)가 되도록 클러스터의 상태를 바꾸는 역할을 담당- 전반적인 k8s 리소스의 라이프사이클을 관리
- 각 k8s 리소스는 개별적인 리소스 컨트롤러가 존재
[ cloud-controller-manager ]
- 클라우드 플랫폼에 특화된 리소스를 제어하기 위한 컴포넌트
- 클라우드 플랫폼의 로드밸런서에 연결하거나 스토리지를 추가하는 작업 등등을 수행
[ Worker ]
[ 개요 ]
- 워커 노드에 위치하여 마스터로부터 명령을 전달받아 컨테이너를 실제로 실행시키는 주체(
kubelet)가 존재- 컨테이너가 정상적으로 실행 될 수 있도록 도와주는 네트워크 프록시(
kube-proxy)와 실행환경(runtime)도 존재
- 구성
- kubelet : 각 워커 노드마다 위치하여 마스터의 명령에 따라 컨테이너의 라이프사이클을 관리하는 노드 관리자
- kube-proxy : 컨테이너의 네트워킹을 책임지는 프록시
- container runtime : 실제 컨테이너를 실행하는 컨테이너 실행 환경
[ kubelet ]
- 각 노드에서 실행되는 메인 컴포넌트(데몬으로 동작)
- 마스터로부터 특정 컨테이너를 실행시키기 위해 상세 명세(
spec)을 받아 실행- 해당 컨테이너가 정상적으로 동작하는지 지속적으로 모니터링
- 주기적으로 api 서버와 통신하며 마스터와 노드간에 필요한 정보(
노드의 상태정보/리소스 사용량등)를 주고받음- 컨테이너 엔진(containerd)을 실제로 제어하는 주체
[ kube-proxy ]
- 역시 각 노드에 위치하여 k8s 서비스 네트워킹을 담당하는 컴포넌트
- 서비스마다 개별 IP를 가지도록 구성
- 내/외부의 트래픽을 Pod로 전달할 수 있도록 패킷을 라우팅
[ container-runtime ]
- 실제 컨테이너를 실행하기 위한 환경 ex) Docker
- 도커 뿐만 아니라 CRI(
Container Runtime Interface) 규약을 따르면 k8s의 컨테이너 런타임으로 사용 가능

Developer & PhotoGrapher