
Intro
컬렉션 조회 최적화 ?
일대다(OneToMany)관계에 있으면필드로컬렉션(Collection)을 가지게 되고 이러한 상황에서의조회를단계적으로최적화를 다루는 것
일대일(OneToOne),다대일(ManyToOne)연관관계에서데이터 조회와최적화는 앞 글에서 다룸
- 순서
V1:(엔티티 조회)/엔티티 직접 반환V2:(엔티티 조회)/DTO를 사용한 반환V3:(엔티티 조회)/DTO 반환+fetch join/페이징 X
V3.1:페이징 OV4:(DTO 조회)/DTO 반환V5:(DTO 조회)/DTO 반환+N+1 문제해결V6:(DTO 조회)/DTO 반환+1방쿼리
엔티티 조회
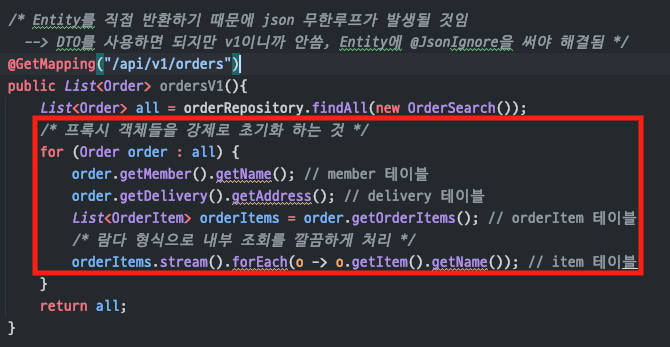
V1
(API 로직)
- 로직
:모든 Order들을 조회한 후Entity를 직접 반환- 문제점
N+1 문제
:order를 순회하면서프록시 객체를강제로 초기화json 무한루프 문제
:json 무한루프 문제를 해결하기 위해Entity에 직접@JsonIgnore를 써야함
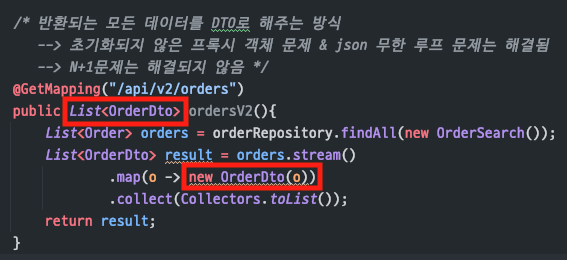
V2
(API 로직)
- 해결
DTO를 반환하여json 무한루프 문제를해결- 문제점
N+1 문제
:new OrderDto(o)과정에서order를 순회하며내부 생성자에서각 요소를 강제 초기화하기 때문에여전히 N+1 문제가 발생
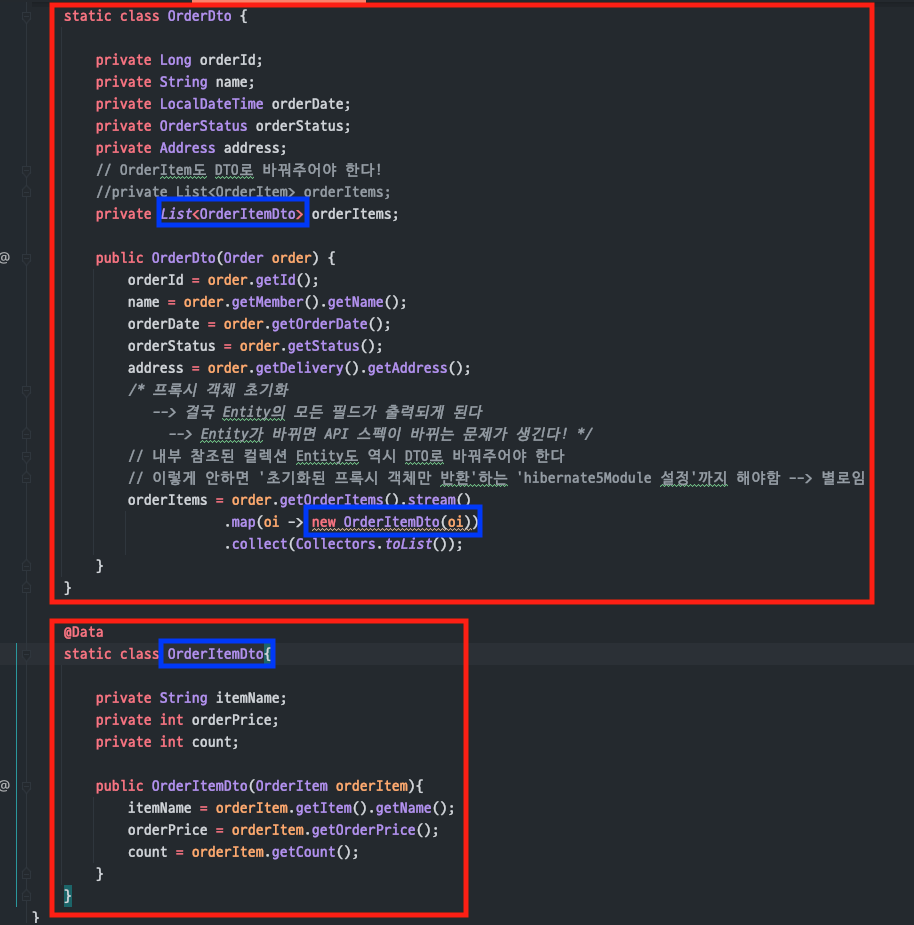
(DTO)
- 주의
Order에 있는컬렉션인orderItems도DTO를 사용해서반환해야 한다
-->실무에서 많이하는 실수!(Entity를 직접 반환하지 말자)
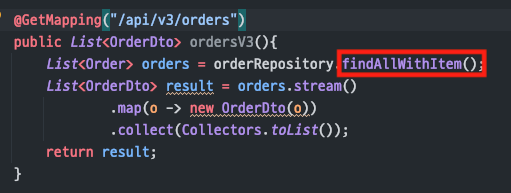
V3
(API 로직)
- 해결
fetch join을 사용해서N+1 문제를해결함
- 문제점
페이징불가능
:1:N 관계에서join을 하면데이터가 뻥튀기되어서 우리가 원하는페이징이 불가능함
(내부적으로 hibernate가 메모리에 올려서해주려고 노력은 하지만,
메모리에 모든 데이터를 올린다는 것은부하가 생길 위험이 매우 크다!
-->1:N관계에서페이징을 하려면V3.1 방법을 사용하자)
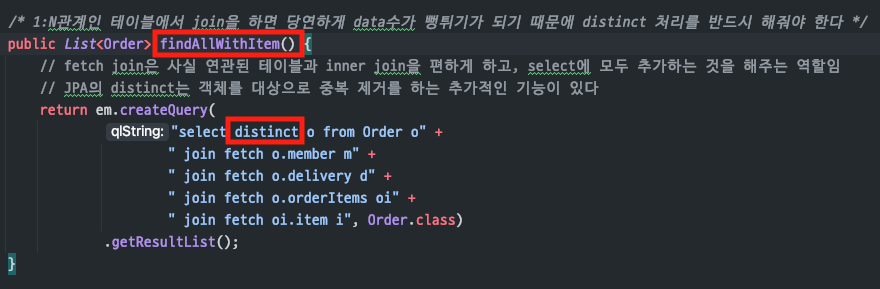
(fetch join 코드 추가 - repository)
컬렉션 패치조인은distinct 필수
:컬렉션을 가진다는 것은1:N 관계라는 것이고join시데이터가 뻥튀기됨
즉, 반드시distinct옵션으로중복 객체를 제거해야 한다
컬렉션 패치조인은1개만 사용
:컬렉션을 패치조인하면1:N으로 데이터가 증가되는데 컬렉션을또 패치조인하면
1:N:M 관계로데이터가 많아져서부정합하게 조회될 수 있음
V3.1
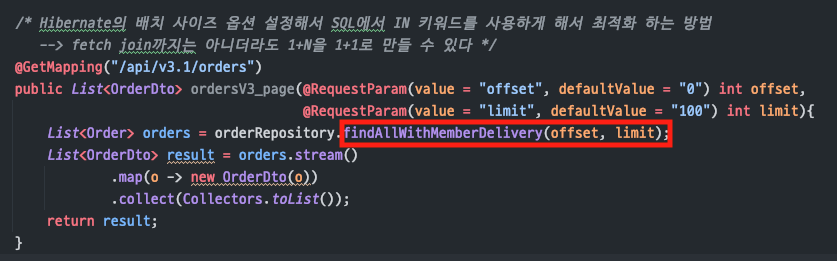
(API 로직)
- 로직
컬렉션이 아닌 Entity는fetch join을 사용해서조회 쿼리를감소시킨다OrderDto(o)과정에서지연로딩으로 인해쿼리가 나갈 때Batch size 옵션에지정한 만큼 크기를 미리 가져온다
(SQL의 IN 키워드를 통해서효율적으로 동작함)- 결과적으로
N번의 쿼리가 나가지 않고1번의 쿼리만수행된다
(Batch size에 따라 상이)
- 해결
N+1 문제 부분 해결
:Batch size옵션을 통해서쿼리의 횟수를많이 줄일 수 있음
(1+N+N이1+1+1이 된다)
Trade Off
fetch join을 사용하는 것 보다많은 쿼리가 발생
-->컬렉션 관계에서페이징을 하려면어쩔 수 없음
--> 하지만,정규화된 데이터만 가져오기 때문에 때에 따라서더 효율적이기도 함
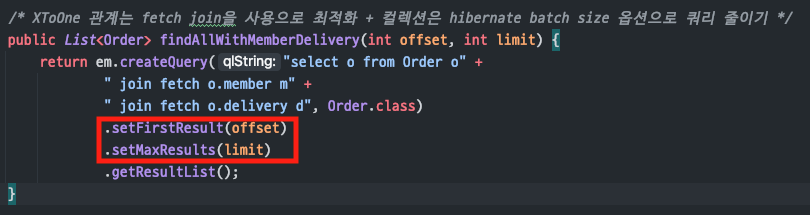
(fetch join 코드 추가 - repository)
Batch size 옵션을켰기 때문에컬렉션이 아닌 Entity 조회시에도SQL IN절이 사용
하지만, 이것보다는fetch join을사용하는 것이 더 효율적
(컬렉션이 아닌 Entity 관계는join을 해도 데이터가 뻥튀기 되지 않기 때문에안전함)
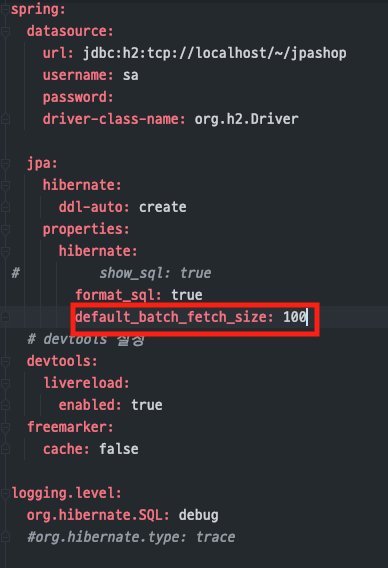
(Batch size 글로벌 옵션 추가 - application.yml)
Batch size를 지정하는 방법
- 글로벌 옵션
:jpa.properties.hibernate.default_batch_fetch_size옵션 지정
(보통글로벌 옵션으로지정해서 많이 사용함)- 개별 옵션
:@BatchSize어노테이션으로 개별 지정
Batch size의적당한 크기 ?
100 ~ 1000 사이가적당
(클수록 성능은 좋으나,순간 부하가 높아서DB성능에 따라서 조절해야 함)- 왜냐하면,
SQL IN 절을 사용할 때DB에 따라 1000건 이상시 오류를 발생할 수 있음
DTO 조회
V4
(API 로직)
- 로직
JPA를 DTO로 조회하는findOrderQueryDtos()메서드 호출OrderQueryDtoDTO를 통해 반환
(OrderQueryRepository - 쿼리 추가)
DTO 조회를 위한별도의 repository(OrderQueryRepository)를 생성
표현 계층에 데이터를 만들기 위한특수한 repository관심사를 분리해서확실하게 유지보수할 수 있다repository를 분리할 경우에DTO도controller에서 정적으로 생성하지 말고따로파일로 분리해야 한다
--> 그렇지 않으면repository가controller를참조하는 역행이 발생
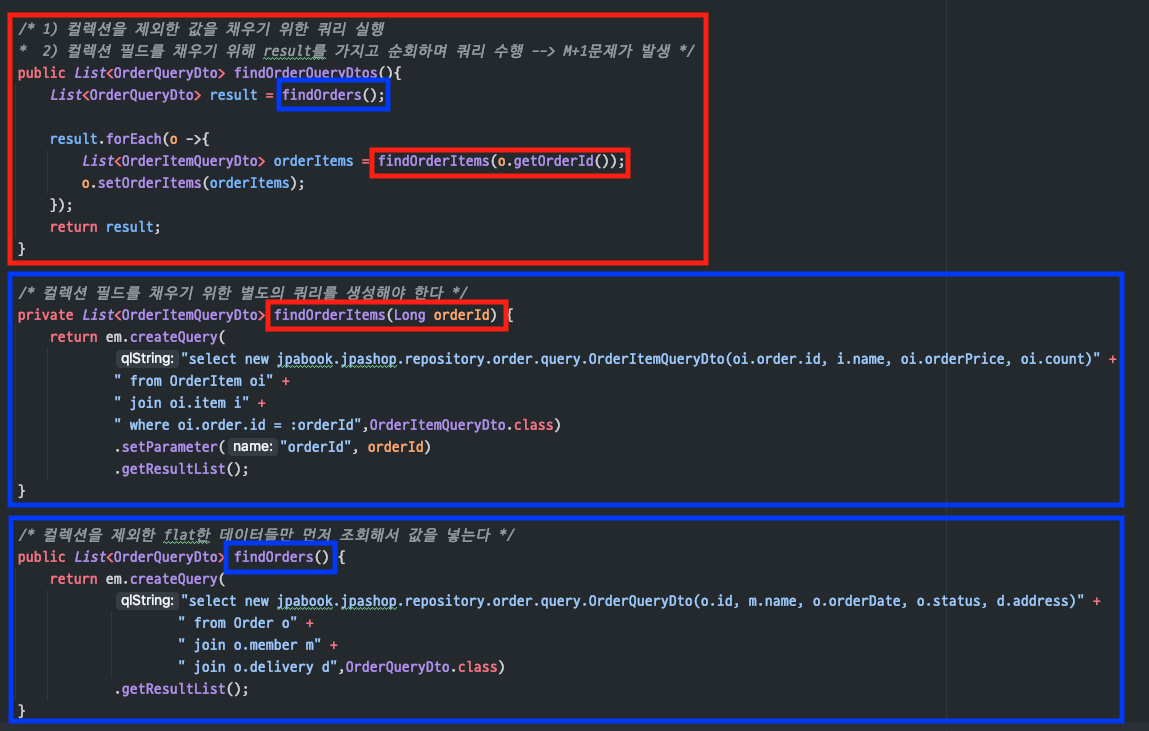
- 로직
컬렉션이 아닌 Entity와데이터는findOrders()라는 쿼리로값을 미리 채움결과를 순회하며orderId에 해당하는 정보를 찾는findOrderItems()호출
(순회하면쿼리가 나가기 때문에N+1 문제 발생)
- 해결
DTO를 통해서원하는 데이터만DB에서 가져올 수 있음
- 문제점
순회하며 쿼리를 수행하기 때문에N+1 문제가 발생
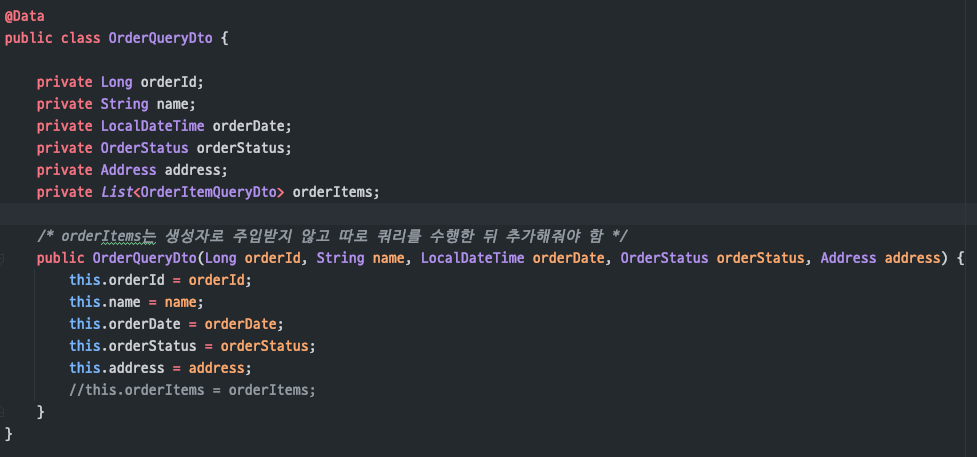
(JPA를 직접 조회하기 위한 DTO)
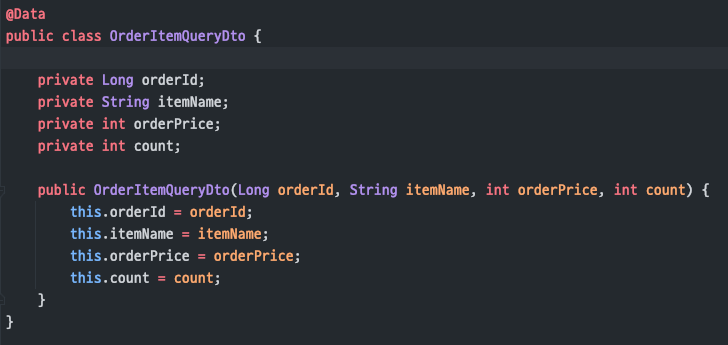
컬렉션 값인orderItems는따로 쿼리를 호출하기 때문에생성자에 주입 X

V5
(API 로직)
- 로직
JPA를 DTO로 조회하는findAllByDto_optimization()메서드 호출OrderQueryDtoDTO를 통해 반환
(OrderQueryRepository - 쿼리 추가)
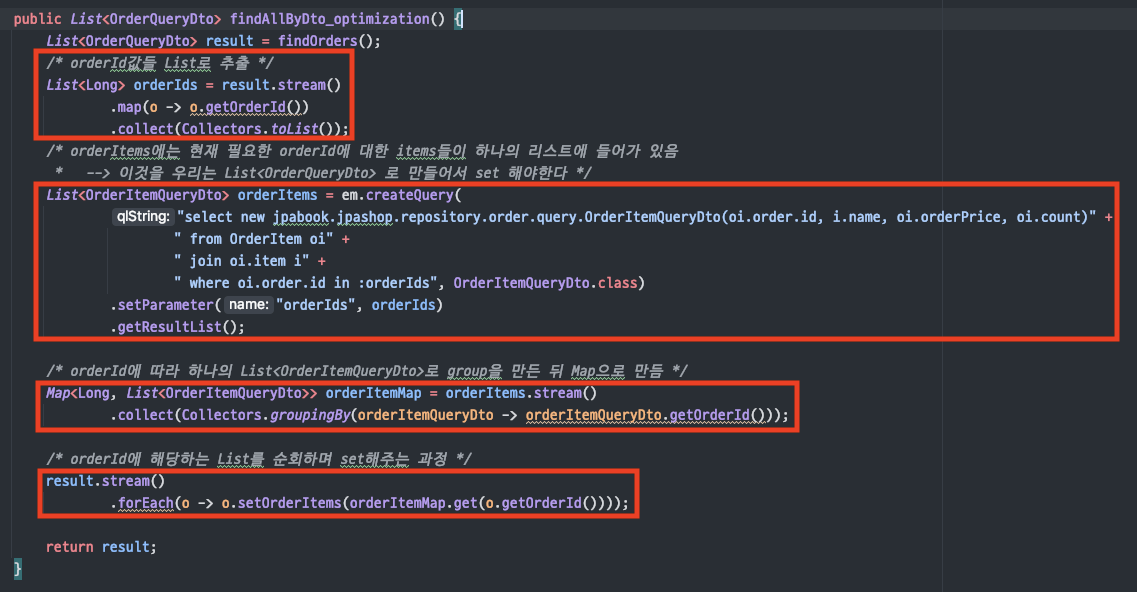
- 로직
컬렉션이 아닌 Entity와데이터는findOrders()라는쿼리로 값을미리 채움결과에서orderId를 모두 추출해서쿼리의 파라미터로 전송(SQL IN 절 사용)쿼리의 결과를orderId에 따르는List<OrderItemQueryDto>로 정리하기 위해Map<Long, List<OrderItemQueryDto>>형태로 변환순회하면서setOrderItems()를 통해 정리한 값 지정
- 해결
N+1 문제 해결
:orderId를 모두 추출해서SQL IN절을 사용하여1번의 쿼리로 해결

V6
(API 로직)
- 로직
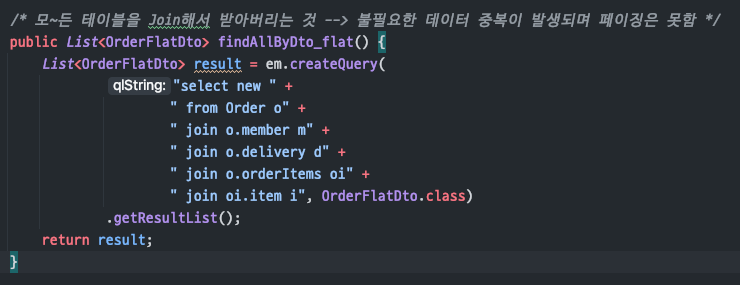
JPA를 DTO로 조회하는findAllByDto_flat()호출
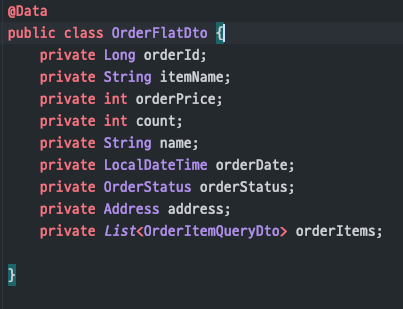
(컬렉션을따로처리하지 않고모든 데이터를 가져오게동작)모든 데이터를 가진OrderFlatDto로 반환
(V1 ~ V5와 결과 스펙이 다르다!이것을 맞춰주려면application에서 값을 일일히 매칭하고 형식을 바꿔주어야 함--> 난 귀찮으니 패스)
(OrderQueryRepository - 쿼리 추가)
컬렉션을 따로처리하지 않고모~두 한꺼번에 join해서 가져옴
-->데이터 중복이 발생할 수 밖에 없으며, 이것은application에서 처리해야함
(모든 데이터를 가진 DTO 추가 생성)

정리
- 엔티티 조회
V1:엔티티를 직접 반환V2:엔티티 조회후DTO로 반환V3:fetch join으로 쿼리 수 최적화/페이징 XV3.1
컬렉션을 제외한 나머지는fetch join으로 조회컬렉션은지연 로딩을 유지하며,Batch size 옵션 지정
-->페이징 가능!
- DTO 직접 조회
V4:JPA에서 DTO로 직접 조회V5:일대다 관계인 컬렉션을SQL IN 절을 통해메모리에 미리 조회해서최적화
(페이징 O)V6:모든 테이블 join결과를application에서 정리해서API스펙에 맞춰 반환
(페이징 X)
엔티티 조회vsDTO 직접 조회
엔티티 조회는JPA에서 제공하는fetch join이나batch size옵션으로N+1 문제 쉽게 해결하지만,DTO 직접 조회에서는추가적으로 해야할 것이많음
--> 이것은변경사항 발생시 그만큼수정해야 할 것이 많음을 의미
-->기본적으로는엔티티 조회를우선적으로 사용하는 것을권장
- 권장 순서
엔티티 조회
- 페이징 없으면 -->
V3- 페이징 있으면 -->
V3.1DTO 직접 조회
V5

Developer & PhotoGrapher