
종류
[ 시간복잡도 O(N^2) ]
1) 버블 정렬(제일 비효율)
2) 선택 정렬
3) 삽입 정렬(O(N^2)중에서는 제일 효율적)
[ 시간복잡도 O(N*logN) ]
1) 퀵 정렬(피벗에 따라 최악시 O(N^2))
2) 병합 정렬
3) 힙 정렬(메모리를 추가로 필요 X / 항상 O(N*logN)을 보장해서 제일 효율적임)[ 시간복잡도 O(N) ]
1) 계수정렬(데이터의 범위가 정해져 있는 경우에 O(N)의 시간복잡도를 갖는다)
: 크기를 기준으로 갯수를 세어주는 것!
선택정렬(Selection Sort)
제일 작은 값을 선택해서 차례 차례 앞으로 보내는 정렬
1) N개의 정수를 모두 돌면서 가장 작은 값을 찾는다(min)
2) 해당 값과 제일 앞 인덱스 값과 교환한다.
3) 1~2 과정을 반복한다
[ 시간 복잡도 ] - O(N^2)
#include <iostream> using namespace std; int main(){ int N = 10, min, arr[10]={10,6,7,5,3,1,4,6,8,9},index; for(int i=0;i<N-1;i++) { min = 9999; for(int j=i;j<N;j++) { if(arr[j] < min){ min = arr[j]; index = j; } } int tmp = arr[i]; arr[i] = arr[index]; arr[index] = tmp; } for(auto a : arr){ cout << a << endl; } }
버블 정렬(Bubble Sort)
옆에 있는 값과 계속 비교하며 작은 값을 점점 앞으로 보내며 정렬하는 방법
(1 Cycle이 지나면 가장 큰 값이 맨 뒤에 위치됨)1) N개의 원소를 앞에서 차례로 바로 옆 원소와 비교하며 작은값을 앞으로 보냄
2) 1 Cycle이 돌면 가장 큰 값이 뒤에 위치 된다[ 시간복잡도 ] - O(N^2)
: 효율이 안좋은 정렬 선택보다도 더 비효율적인 방법이다.
(시간 복잡도는 같지만, 실제 수행 시간을 분석 하면 매번 교환하기 때문에 매우 비효율적!)
#include <iostream> using namespace std; int main(){ int N = 10, arr[10]={10,6,7,5,3,1,4,6,8,9}; for(int i=N-1;i>0;i--) { for(int j=0;j<i;j++) { if(arr[j] > arr[j+1]){ int tmp = arr[j]; arr[j] = arr[j+1]; arr[j+1] = tmp; } } } for (auto a : arr){ cout << a << endl; } }
삽입 정렬(Insertion Sort)
정렬된 값들에 대해 현재 원소가 어떤 위치에 들어갈 지 찾아 삽입하는 정렬
1) 배열의 2번째 요소부터 시작
2) 바로 앞 요소와 비교하여 클 때 까지 교환
3) Cycle이 돌 수록 앞 원소는 이미 정렬된 상태
4) 1~3 과정을 반복[ 시간 복잡도 ] - O(N^2)
: O(N^2)의 시간복잡도를 가지는 정렬 중에 가장 효율적
(모두 비교하지 않아도 괜찮기 때문)
#include <iostream> using namespace std; int main(){ int N = 10, arr[10]={10,6,7,5,3,1,4,6,8,9},j; for(int i=1;i<N;i++) { j = i; while(arr[j] < arr[j-1]) { int tmp = arr[j]; arr[j] = arr[j-1]; arr[j-1] = tmp; j--; } } for (auto a : arr){ cout << a << endl; } }
퀵 정렬(Quick Sort)
피봇을 기준으로 2개의 집합으로 분할하여 정렬을 하는 방법
[ 시간 복잡도 ] - O(N*logN)
피봇의 위치에 따라 최악의 경우인 경우 O(N^2)의 복잡도를 갖는다(최고 단점)
(평균적인 복잡도는 O(N*logN))
(최악의 경우 => 이미 정렬이 된 상태)
(이미 정렬이 된 상태인 경우 앞서 배운 '삽입 정렬'이 더 효율적이다!)
#include <iostream> using namespace std; void quickSort(int* data, int start, int end){ if(start >= end){ return; } int key = start; // 피봇 값 int i = start + 1; int j = end; int tmp; while(i <= j){ // i와 j값이 엇갈릴 때 까지 수행 while(data[key] >= data[i]){ // 피봇보다 작은값을 찾을 때 까지 i++; } while(data[key] <= data[j] && j > start){ // 피봇보다 큰 값을 찾을 때 까지 j--; } if(i <= j){ // 엇갈리지 않았다면 그냥 교환 tmp = data[i]; data[i] = data[j]; data[j] = tmp; }else{ // 엇갈렸다면 key값과 j와 교환 tmp = data[key]; data[key] = data[j]; data[j] = tmp; } } quickSort(data, start, j-1); quickSort(data,j+1, end); } int main(){ int N = 10, arr[10]={10,6,7,5,3,1,4,6,8,9}; quickSort(arr, 0, N-1); for (auto a : arr){ cout << a << endl; } }
병합 정렬(Merge Sort)
일단 반으로 계속 나누고 합치면서 정렬하는 방법
(이미 정렬이 된 두 집합을 합치는 과정은 O(N)만큼만 소요된다!)
[ 시간 복잡도 ] - O(N*logN)
#include <iostream> using namespace std; int N = 10, sorted[10]; // 두 묶음을 하나로 합치는 과정 void merge(int data[], int m, int middle, int n){ int i=m; int j=middle+1; int k=m; // 두 집합의 값을 비교하며 차례대로 넣는 과정 while(i <= middle && j <= n){ if(data[i] <= data[j]){ sorted[k] = data[i]; i++; }else{ sorted[k] = data[j]; j++; } k++; } // 둘 중 남은 한 집합을 마저 더해주는 과정 if(i > middle){ for(int t=j; t<=n; t++){ sorted[k] = data[t]; k++; } }else{ for(int t=i; t<=middle; t++){ sorted[k] = data[t]; k++; } } // 정려된 데이터를 실제 배열에 삽입! (실제 배열을 바로 바꾸면 안된다!) for(int t=m; t<=n; t++){ data[t] = sorted[t]; } } void mergeSort(int data[], int m, int n){ // 크기가 1보다 큰 경우 if(m < n){ int middle = (m+n) /2; /* 일단 둘로 계속 나누는 mergeSort를 진행 */ mergeSort(data, m, middle); mergeSort(data, middle+1, n); /* 합치는 과정! */ merge(data, m, middle, n); } } int main(){ int N = 10, array[10]={10,6,7,5,3,1,4,6,8,9}; mergeSort(array, 0, N-1); for (auto a : array){ cout << a << endl; } }
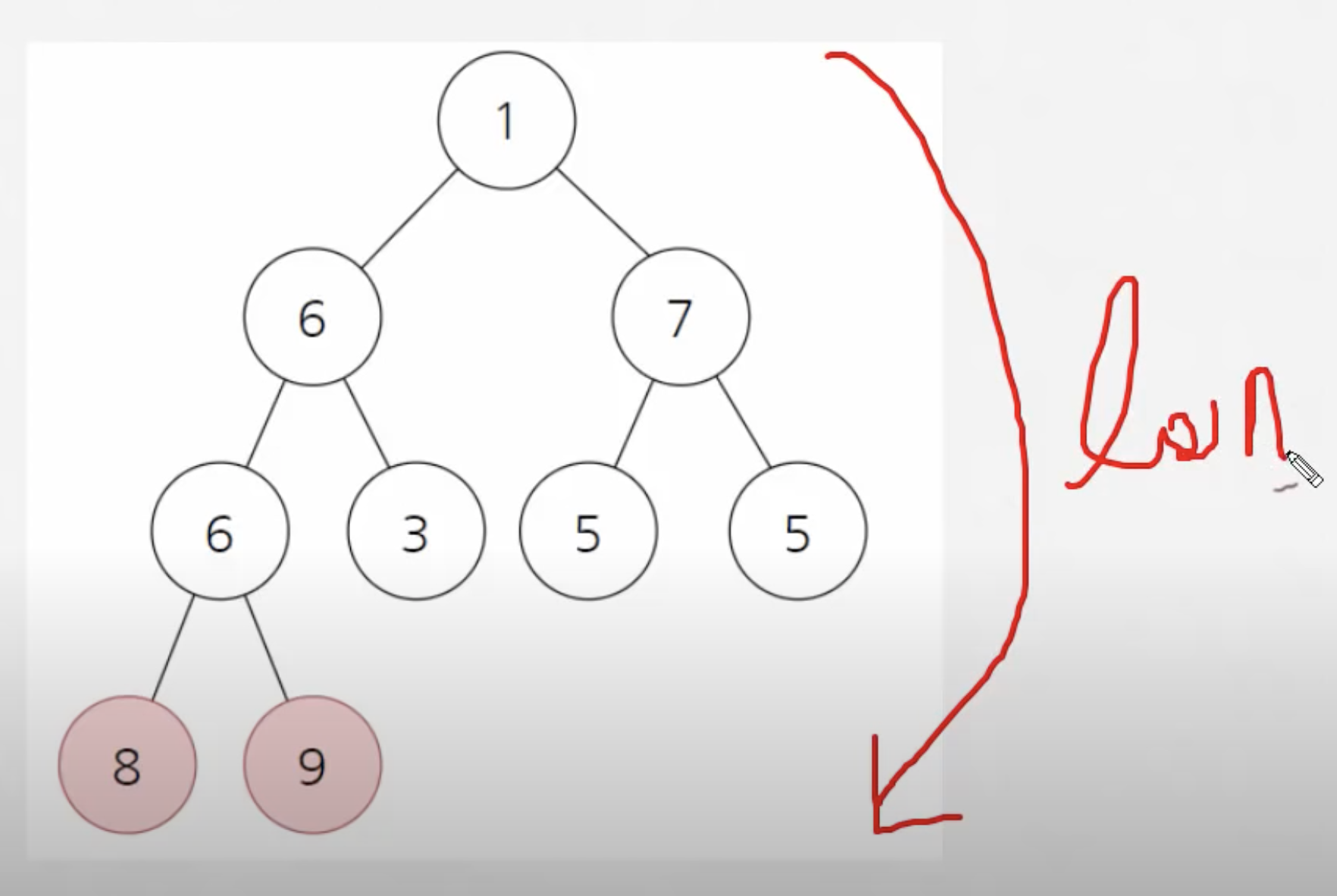
힙 정렬(Heap Sort)
힙 트리 구조(Heap Tree Structure)를 이용한 정렬 방법
[ 설명 ]
다양한 트리가 존재하지만 우리는 '이진 트리', 그 중에서도 값이 비지 않고
빽빽한 구조를 유지하는 '완전 이진 트리'를 이용하는 구조가 '힙 트리 구조' 이다.[ 최대 힙 ] : 부모 노드가 자식 노드 보다 큰 힙!
[ 최소 힙 ] : 부모 노드가 자식 노드 보다 작은 힙![ 힙 생성 알고리즘 ]
: Heapify 알고리즘으로 불리며, 힙 구조를 만들기 위해 사용되는 알고리즘
( O(logN)의 시간복잡도가 걸린다 --> N/2개의 원소에 대해 실행 --> O(N*logN)의 시간복잡도 )
(상향식 힙구조 만들기 / 하향식 힙구조 만들기 --> 방향의 차이!(결과 힙 구조는 달라질 수 있음))
[ 원리 ]
1. 정렬할 원소를 배열을 사용해 이진트리로 표현
2. 힙 구조를 만든다(Heapify 알고리즘 사용)
3. root와 가장 마지막 원소를 change
4. 2 ~ 3 과정을 반복하여 마지막에 가장 큰 값을 하나씩 채워나간다
[ 코드 ]
#include <iostream> #include <algorithm> #include <vector> using namespace std; int N = 9; int heap[9] = {7,6,5,8,3,5,9,1,6}; int main(){ // 최초 최대 Heap 구조로 만들기 위한 Heapify 알고리즘 for(int i=1; i<N ; i++){ int c=i; do{ int root = (c-1)/2; if(heap[root] < heap[c]){ int temp = heap[root]; heap[root] = heap[c]; heap[c] = temp; } c = root; }while(c != 0); } // 크기를 줄여가며 반복적으로 heap을 구성! for(int i=N-1;i>=0;i--){ int temp = heap[0]; heap[0] = heap[i]; heap[i] = temp; // 다시 최대 heap구조를 만들기 위한 Heapify 알고리즘 int root = 0; int c = 1; do{ c = 2*root + 1; // 자식 중 더 큰 값을 찾기 if(heap[c] < heap[c+1] && c < i-1){ c++; } // 루트보다 자식이 더 크다면 교환 if(heap[root] < heap[c] && c < i){ int temp = heap[root]; heap[root] = heap[c]; heap[c] = temp; } root = c; }while(c < i); } for(auto a : heap){ cout << a << ' '; } }
계수 정렬(Counting Sort)
데이터의 크기가 정해져 있는 경우 O(N)의 시간복잡도를 가지는 정렬 방법
(데이터의 최대 크기 만큼 메모리가 필요하기 때문에 비효율 적일 수도 있음)
[ 코드 ]
#include <iostream> using namespace std; int N = 9; int heap[9] = {7,6,5,8,3,5,9,1,6}; int main(){ int count[5]; int array[30] = { 1,3,2,4,3,2,5,3,1,2, 3,4,4,3,5,1,2,3,4,2, 3,1,4,3,5,1,2,1,1,1 }; fill(count, count+5, 0); for(int i=0;i<30;i++){ count[array[i]-1]++; } for(int i=0; i<5; i++){ if(count[i] != 0){ for(int j=0; j<count[i];j++) { cout << i+1; } } } }
