
ref : 남궁성님의 자바의 정석 유튜브를 참조합니다
https://www.youtube.com/watch?v=z9GpUGoYCw4&list=PLW2UjW795-f6xWA2_MUhEVgPauhGl3xIp&index=118
https://www.youtube.com/watch?v=RscGmop2Bzo&list=PLW2UjW795-f6xWA2_MUhEVgPauhGl3xIp&index=119
https://www.youtube.com/watch?v=u0pJGFyvrqc&list=PLW2UjW795-f6xWA2_MUhEVgPauhGl3xIp&index=133
https://gangnam-americano.tistory.com/41
컬렉션 프레임워크
[ 설명 ]
컬렉션 프레임워크(Collection Framework)
컬렉션(다수의 객체)을 다루기 위한표준화된 프로그래밍 방식컬렉션을쉽고 편리하게 다룰 수 있는다양한 클래스제공
(저장삭제검색정렬등)
컬렉션 클래스
다수의 데이터를저장할 수 있는클래스- ex)
Vector,ArrayList,HashSet등
[ 핵심 인터페이스 ]

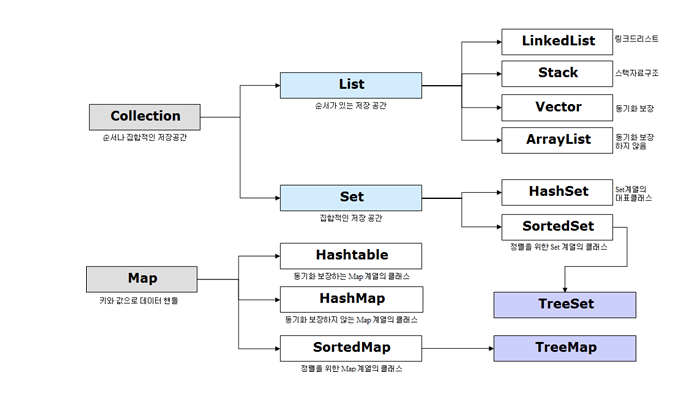
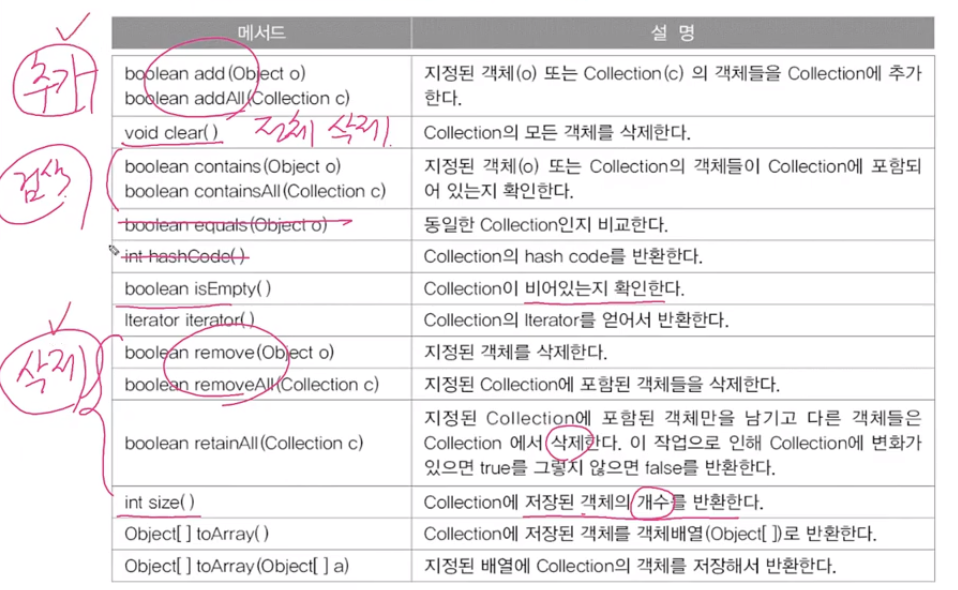
[ Collection 인터페이스 메서드 ]
List 인터페이스
[ 정보 ]
설명
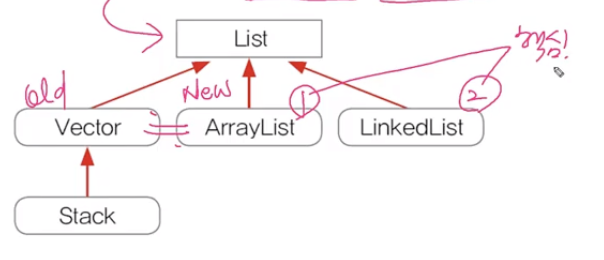
순서가있으며,데이터의 중복을허용Collection 인터페이스의자손ArrayList/LinkedList/Stack/Vector등ArrayList와LinkedList가 핵심- ex) 대기자 명단
구조
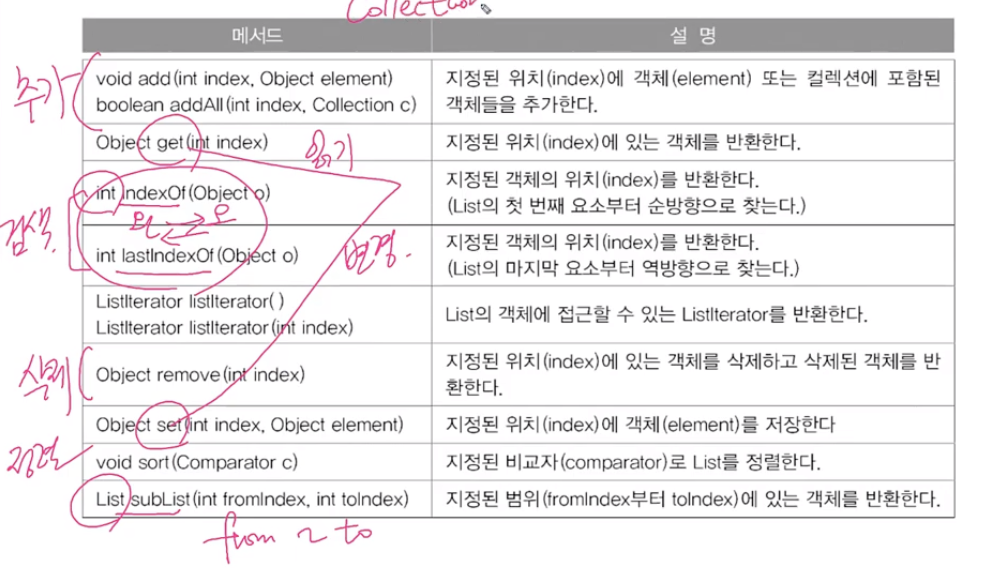
주요 메서드
[ ArrayList ]
설명
- 기존의
Vector를개선한 것으로구현원리와기능적으로동일Vector는동기화 처리 O/ArrayList는동기화 처리 XList 인터페이스를 구현 -->순서 O/중복 O데이터 저장공간으로배열을 사용(배열 기반)데이터는Object만 가능 --> 즉,객체만가능
기본형(primitive type)을 넣어도 되긴함 -->컴파일러가오토박싱을 해주기 때문정렬을 할때에는Collections라는유틸 클래스를 통해 수행
- 오름차순 :
Collections.sort(list)- 내림차순 :
Collections.sort(list, Collections.reverseOrder())- 모든 객체 삭제시 유의
- 첫번째 요소부터 삭제 :
배열 복사 발생 O-->비효율적- 마지막 요소부터 삭제 :
배열 복사 발생 X-->훨씬 효율적
생성자
- ArrayList() :
기본 생성자- ArrayList(Collection c) :
컬렉션으로초기화- ArrayLis(int initialCapacity) :
배열의 길이 지정
추가
- boolean add(Object o) :
맨 뒤에 삽입- void add(int index, Object element) :
특정 위치에삽입- boolean addAll(Collection c)
- boolean addAll(int index, Collection c)
삭제
- boolean remove(Object o) :
해당 객체 삭제- Object remove(int index) :
특정 위치에 있는 객체삭제- boolean removeAll(Collection c) :
collection에 있는 객체들삭제- void clear() :
모든 객체 삭제
검색
- int indexOf(Object o)
- int lastIndexOf(Object o)
- boolean contains(Object o)
- Object get(int index) :
index에 있는 객체읽기
그 외
- Object set(int index, Object element) :
index에 있는 객체변경- List subList(int fromIndex, int toIndex)
- Object[] toArray() :
ArrayList의객체 배열을반환- Object[] toArray(Object a)
- boolean isEmpty()
- void trimToSize() :
빈 공간 제거- int size()
[ LinkedList ]
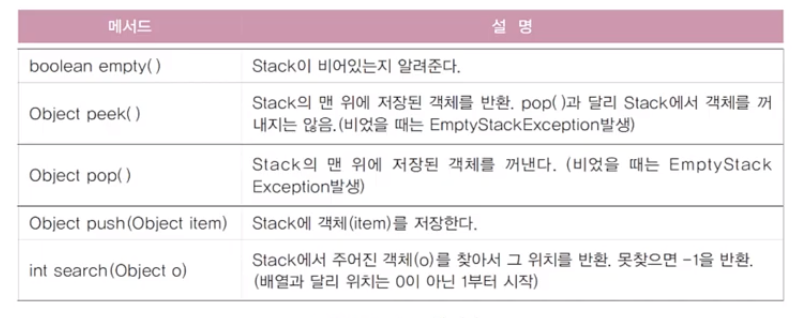
[ Stack ]
설명
LIFO구조Java에서Stack은클래스라서바로 생성해서 사용 가능Stack s = new Stack(); s.push(1); s.push(2); s.pop();
메서드
- peek() :
맨 위 객체읽기- search() :
특정 객체의 위치를반환/없으면 -1반환
[ Queue ]
설명
FIFO구조Java에서Queue는인터페이스라서직접 생성할 수 없음
- 직접 구현 -->
실제로는 잘 사용하지 X- Queue를 구현한 클래스를 사용
- LinkedList :
주로 Queue를 사용할 때LinkedList로 자주사용- PriorityQueue
- 등 매우 많음
Queue q = new LinkedList(); q.offer(1); q.offer(2); q.poll();
메서드
- 똑같은
추가/삭제 기능이지만예외 발생 여부로나뉜다- 보통
예외 없이poll()/offer()로사용

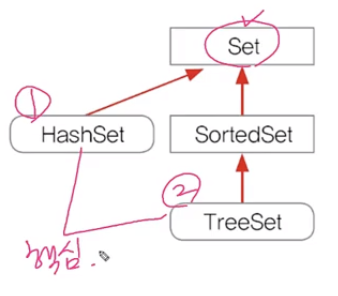
Set 인터페이스
[ 정보 ]
설명
순서가없으며,데이터의 중복을허용하지 않음Collection 인터페이스의자손- ex) 양의 정수 집합
- 구조
HashSet/TreeSet이 핵심
메서드
Collection과동일하며아래 특징을 기억하면 좋음
:합집합/부분집합/차집합/교집합

[ HashSet ]
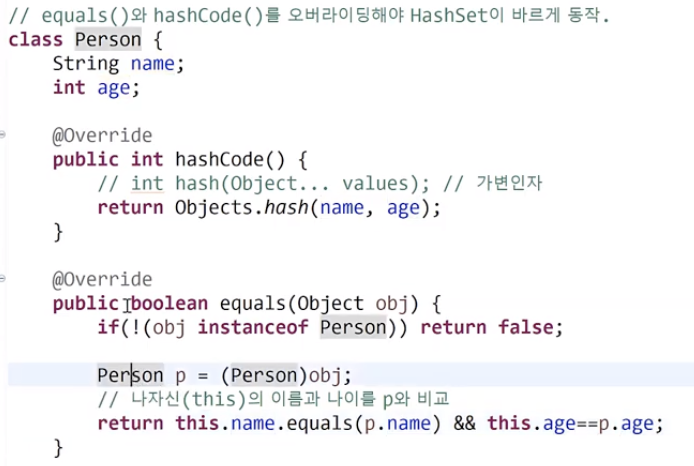
설명
Set 인터페이스를구현한대표적인 컬렉션 클래스
- 순서 X
순서가 없기 때문에정렬 불가능-->정렬하려면List로 옮겨서정렬수행- 중복 X
중복이 없어야 하기 때문에내가 만든 객체를 저장할 때에는
euqlas()/hashCode()를오버라이딩해야정상 동작함순서를 유지하려면,LinkedHashSet 클래스사용하면 됨TreeSet은범위 검색과정렬에유리하지만,데이터 추가/삭제에불리
생성자
- HashSet()
- HashSet(Collection c)
- HashSet(int initialCapacity)
- HashSet(int initialCapacity, float loadFactor)
:loadFactor 이 0.8이면80%가 되었을 때capacity를 늘리도록 설정
추가
- boolean add(Object o) :
추가- boolean addAll(Collection c) :
합집합
삭제
- boolean remove(Object o)
- boolean removeAll(Collection c) :
교집합(공통된 것 삭제)- boolean retainAll(Collection c) :
차집합(포함되는 것 삭제)- void clear() :
모두 삭제
그 외
- boolean contains(Object o)
- boolean containsAll(Collection c) :
모두 포함되어있는지확인- Iterator iterator()
- boolean isEmpty()
- int size()
- Object[] toArray() :
set에 저장되어 있는 객체를객체 배열로반환- Object[] ToArray(Object[] a)
[ TreeSet / LinkedHashSet ]
TreeSet
이진 검색 트리자료구조의형태로데이터를 저장하는컬렉션 클래스추가와 삭제에는시간이 더 걸리지만,정렬, 검색에높은 성능을 가짐Red-Black 트리로구현되어 있다- 필요시
관련 메서드를 찾아보자
LinkedHashSet
HashSet과동일한 구조데이터 요소들이순서를 가짐- 필요시
관련 메서드를 찾아보자
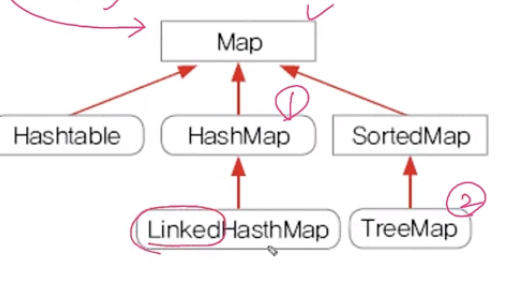
Map 인터페이스
[ 정보 ]
설명
키(key)와값(value)의쌍(pair)으로 이루어진데이터의 집합순서가없으며,키는중복을 허용하지 않고,값은중복을 허용HashMap/TreeMap/Hashtable/Properties등- ex) 아이디-비밀번호
- 구조
HashMap/TreeMap이 핵심Hashtable과HashMap은매우 유사하며,HashMap이개선된 것
메서드
[ HashMap ]
설명
Hashtable의개선버전배열과링크드 리스트가조합된 형태해싱(hashing) 기법으로데이터 저장해서검색이 빠르다key와value로 이루어진하나의 쌍(pair)로 저장 /하나의 쌍을entry라고 함- List 인터페이스를 구현한 대표적인 클래스
순서 Xvalue만중복O순서를유지하려면,LinkedHashMap 클래스를 사용TreeMap은범위검색과정렬에유리/데이터 추가,삭제는불리
생성자
- HashMap()
- HashMap(int initialCapacity)
- HashMap(int initialCapacity, float loadFactor)
- HashMap(Map m)
추가
- Object put(Object key, Object value)
:이미 있는 key값을 넣으면변경이 수행됨- void putAll(Map m)
삭제
- Object remove(Object key)
변경
- Object replace(Object key, Object value) :
key에 저장된value를새로운 value로수정- boolean replace(Object key, Object oldValue, Object newValue)
그 외
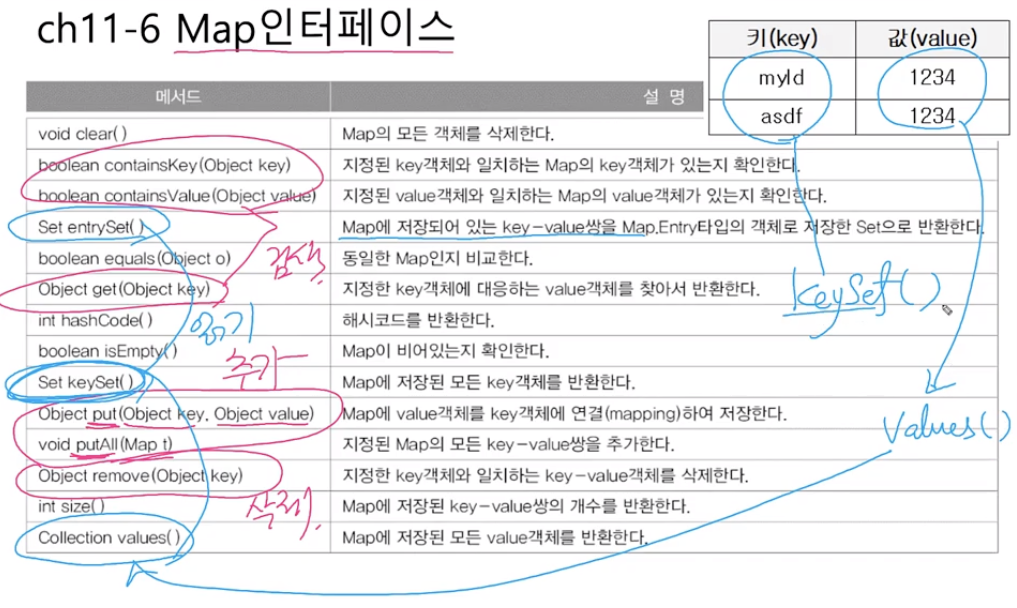
- Set entrySet() :
entry들 조회- Set keySet() :
key들 조회- Collection values() :
value들 조회- Object get(Object key)
- Object getOrDefault(Object key, Obejct defaultValue)
:key의value를조회하는데,없는 key면defaultValue를반환- boolean containsKey(Object key)
- boolean containsValue(Object value)
- int size()
- boolean isEmpty()
- void clear()
- object clone()
[ TreeMap / LinkedHashMap ]
TreeMap
이진트리를기반으로 한Map 컬렉션 클래스TreeSet과 유사하지만key뿐만 아니라value도 저장정렬된 상태에서데이터를 조회해야 하는범위 검색에성능이 좋음- 역시
Red-Black 트리로구현- 필요시
관련 메서드를 찾아보자
LinkedHashMap
HashMap을확장하는 클래스데이터 요소들 간순서를 가짐- 필요시
관련 메서드를 찾아보자
Iterator & Enumeration & ListIterator
[ 정보 ]
Iterator
컬렉션에 저장된 요소를읽어오는 방법을표준화한 것각 컬렉션마다읽어오는 방법이 달라서표준화해서 사용하면편함
Enumeration & ListIterator
Enumeration은Iterator의 구버전-->Iterator를 쓰면 됨ListIterator는List에서 사용하는 Iterator로previous도 있지만잘 사용하지는 않음
(양방향)
핵심 메서드
- 종류
- boolean hasNext() :
읽어올 요소가남아있는지 확인- Object next() :
다음 요소를읽어옴
- 사용
Collection 인터페이스에 있는iterator() 메소드를 통해서받아올 수 있음iter.hashNext()로다음 요소가 존재하는지 확인한 뒤iter.next()로값에 접근ArrayList<Integer> list = new ArrayList(); list.add(1); list.add(2); list.add(3); /* iterator는 1회용이라서 다시 순회하려면 다시 iterator를 생성해야 한다 */ Iterator<Integer> it = list.iterator(); while(it.hasNext()){ System.out.println(it.next()); }
[ Map과 Iterator ]
Map은Collection 인터페이스의자손이 아님Map에는iterator가 없다keySet()/entySet()/values()를 통해서요소에 접근해야 한다Map<String, String> cities = new HashMap<>(); cities.put("Tokyo", "Japan"); cities.put("Seoul", "Korea"); cities.put("Beijing", "China"); /* iterator 사용 */ for(Map.Entry<String, String> enty : cities.entySet()){ System.out.println(entry.getKey() + entry.getValue()); } /* java 8의 forEach + Lambda 사용 */ cities.forEach((k, v) -> System.out.println(k + v));
유틸 클래스(Util Class)
[ Arrays ]
설명
배열을 다루기 위한메서드(static) 제공하는유틸 클래스- 배열의 출력 :
toString()- 배열의 복사 :
copyOf()/copyOfRange()- 배열 채우기 :
fill()/setAll()- 배열의 정렬과 검색 :
sort()/binarySearch()
다차원 배열
- 출력 :
deepToString()- 비교 :
deepEquals()
(2차월 배열에기본적인 equals()는정상 동작하지 X)
배열 --> List 변환
asList()반환 값은읽기 전용이기 때문에변경을 하려면새로 할당필요
사용 예시
/* toString() */ int[] arr = {1, 2, 3, 4, 5}; Arrays.toString(arr); // [1, 2, 3, 4, 5] 로 출력 /* copyOf() copyOfRange() */ int[] arr = {0,1,2,3,4}; int[] arr2 = Arrays.copyOf(arr, arr.length); // arr의 전체를 복사 int[] arr3 = Arrays.copyOfRange(arr, 2, 4) // arr의 2~3인덱스 까지 복사 /* fill() setAll() */ int[] arr = new int[5]; Arrays.fill(arr, 9); // 9로 채우기 Arrays.setAll(arr, (i) -> (int)(Math.random()*5+1)); // 1~5의 랜덤값으로 채우기 /* sort() binarySearch() */ int[] arr = {3, 2, 0, 1, 4}; Arrays.sort(arr); // 오름차순 정렬 Arrays.binarySearch(arr, 2); // 이진탐색은 정렬 후에 정상 동작함 --> idx=2 결과 /* deepToString() deepEquals() */ String[][] str2D = new String[][]{{"abc", "def"}, {"ABC", "DEF"}}; String[][] str2D2 = new String[][]{{"abc", "def"}, {"ABC", "DEF"}}; Arrays.deepToString(arr2D); // [["abc", "def"], ["ABC", "DEF"]] Arrays.deepEquals(std2D, str2D2); // true /* asList() */ List list = Array.asList(new Integer[]{1,2,3,4,5}); list.add(6); // 예외 발생 --> 읽기전용이기 때문 // 아래처럼 값을 가진 새로운 List를 할당해야 변경 가능 List list = new ArrayList(Arrays.asList(new Integer[]{1,2,3,4,5}));
[ Collections ]
설명
컬렉션을 다루기 위한메서드(static)제공하는유틸 클래스내림차순 정렬시Collections.reverseOrder()를 통해Comparator을 사용- 컬렉션 채우기 :
fill()- 컬렉션 복사 :
copy()- 컬렉션 정렬 :
sort()- 컬렉션 탐색 :
binarySearch()
컬렉션 동기화 - synchronizedXXX()
기존에는항상 동기화를 수행했으나, 이제는default로 동기화를 수행하지 않고,필요할 때 사용하는 방식
-->Vector대신ArrayList처럼synchronizedList(List list)synchronizedSet(Set s)synchronizedMap(Map m)- 등
변경 불가 컬렉션 만들기 - unmodifiableXXX()
반환값으로읽기 전용 객체가 만들어짐unmodifiableList(List list)unmodifiableSet(Set s)unmodifiableMap(Map m)- 등
싱글톤 컬렉션 만들기 - singletonXXX()
1개의 인스턴스만만들어짐singletonList(List list)singletonSet(Set s)singletonMap(Map m)- 등
한 종류의 객체만 저장하는 컬렉션 만들기 - checkedXXX()
- 사실
Java 8부터는제네릭스(Generics)가 있어서사용할 일은 없음존재 여부만 확인
기타
rotate()swap()shffle()- 등등
컬렉션 클래스 정리 & 요약
[ 전체 흐름 ]
Collection Framework의주요 인터페이스로List / Set / Map이 존재- 그 중
List / Set 인터페이스는Collection 인터페이스를상속받음
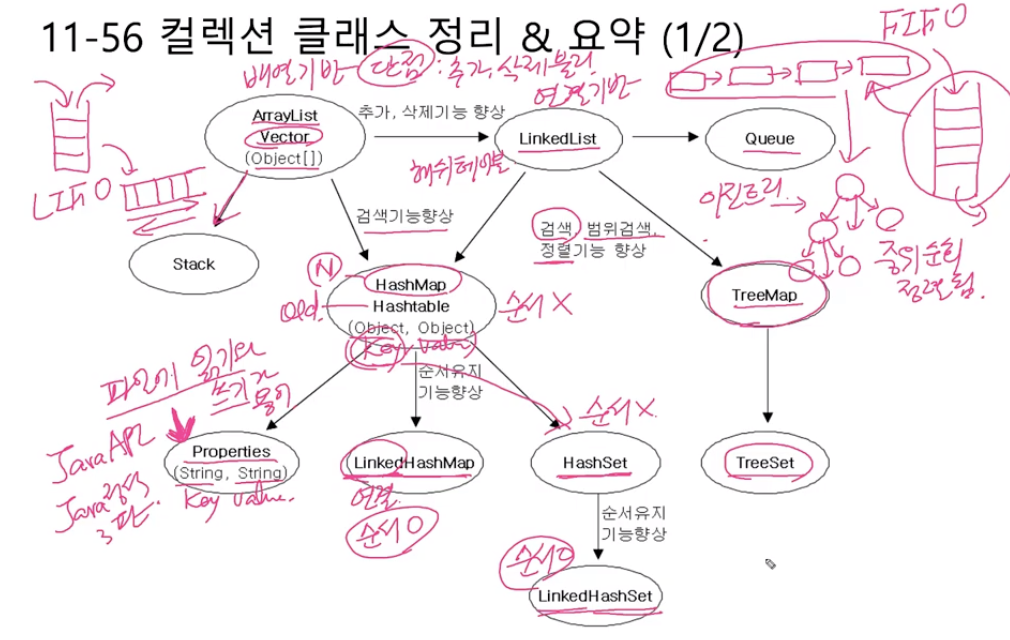
[ List ]
- ArrayList
배열 기반의리스트Vector와 다르게동기화를 자동으로 하지 X-->효율적- Vector
표준화 되기 전 사용되던 것 --> 지금은ArrayList 사용자동으로 동기화 기능이 존재 -->비효율적- Stack
LIFO 구조의stack을 구현한클래스- Vector를 이용해 구현됨
- LinkedList
ArrayList의단점을 극복삽입 / 삭제는유용하지만,탐색은ArrayList에 비해불리- Queue
queue 자료구조를 의미하는인터페이스LinkedList를구현체로 자주사용
[ Set ]
- HashSet
HashMap을 가지고 만들었으며,key만 있는 HashMap이라고 볼 수 있음- TreeSet
TreeMap을 가지고 만들었으며,key만 있는 TreeMap이라고 볼 수 있음- LinkedHashSet
순서가 필요한HashSet
[ Map ]
- HashMap
배열+링크드 리스트의구조(key, value)로 이루어진entry를 가짐- Hashtable
HashMap의과거 버전- TreeMap
이진트리 구조를 가짐범위검색/정렬 기능측면에서용이데이터 삽입/삭제는HashMap이더 용이- Properties
(String, String)만 가지는HashMap파일 읽기 / 쓰기에용이- LinkedHashMap
순서가 필요한HashMap

Developer & PhotoGrapher