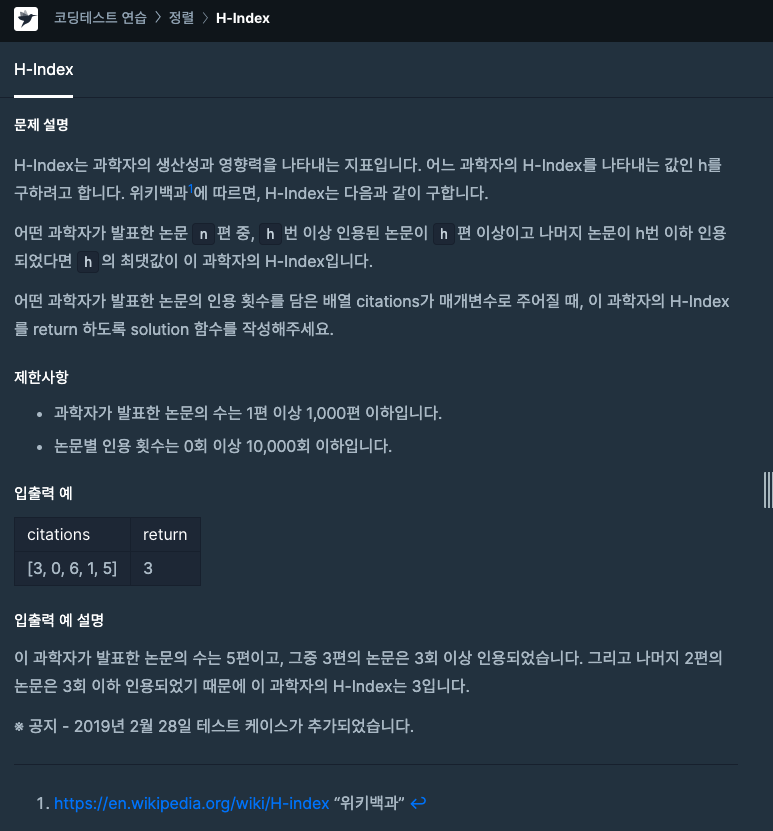
H-index
코드
[ 내 풀이 ]
#include <string> #include <vector> #include <numeric> #include <algorithm> using namespace std; int solution(vector<int> citations) { int answer = 0; int sum=0; vector<int> cnt(10002,0); for(int i=0;i<citations.size();i++) { cnt[citations[i]]++; } sort(citations.begin(), citations.end()); for(int i=citations.size()-1;i>=0;i--){ sum = accumulate(cnt.begin()+(i+1), cnt.end(), 0); if(sum >= i+1){ answer = i+1; break; } } return answer; }
- 직관적으로 생각할 수 있는 풀이 (시간복잡도가 좋지는 않아보임)
1) 계차수열을 이용해서 n번 이용된 논문의 개수를 모두 구한다
2) n번 이상 인용된 논문의 개수가 n보다 크거나 같으면 break!
[ 최적 코드 ]
#include <string> #include <vector> #include <numeric> #include <algorithm> using namespace std; int solution(vector<int> citations) { int answer = 0; // 내림차순으로 정렬 sort(citations.begin(), citations.end(), greater<int>()); for(int i=0;i<citations.size();i++) { if(citations[i] >= i+1){ answer++; }else{ break; } } return answer; }
- h-index를 1씩 증가하는 것이 포인트
- 내림차순하여 확인한 값이 현재 인덱스+1인 (i+1) 보다 크거나 같다면
--> 적어도 (i+1)번 이상 인용된 논문이 있다는 뜻!ex)
[5,3,2,1,0] 일 때 !
( i+1 = 1 / value = 5 ) : h-index증가
( i+1 = 2 / value = 3 ) : h-index증가
( i+1 = 3 / value = 2 ) : break!
즉 , h-index는 2 ! (2번 이상 인용된 논문이 2개 이상이라는 의미)

Developer & PhotoGrapher