8-bit Matrix Multiplication
발췌 : HF Blog
현재 LLM의 트랜드는 사이즈가 커지는 방향으로 진행되고 있습니다.
그렇기에 PaLM 540B, BLOOM 176B와 같이 대규모 LLM이 등장하였으며,
BLOOM-176B을 Inference하기 위해서는 A100 80GB GPU가 8개가 필요하며 Fine-tuning을 하기 위해서는 무려 72개의 A100 GPU가 필요합니다.
그렇기에 해당 모델들의 요구사항을 줄일 수 있는 방안이 필요했고 이에 Quantization과 Distillation 등의 기술들이 나왔습니다.
(이를 해결하기 위해 친칠라와 같은 논문들도 등장하였고 Meta의 LLaMA도 같은 맥락에서 등장하였습니다.)
이에 BigScience 팀은 예측 성능은 유지하며 memory 사용량은 2x배 줄인 Int8 inference 기술을 만들었고 이를 Hugging Face에 통합하였습니다.
그렇다면 이어지는 내용을 통해 해당 기술을 설명하고자 합니다.
Common data types used in Machine Learning
이를 위해서는 floating point data types에 대한 이해가 필요합니다.
이는 흔히 precision으로 ML 분야에서 사용됩니다.
모델의 크기는 파라미터와 precision을 통해 결정됩니다.
이 때 precision은 주로 float32, float16, bfloat16이 사용됩니다.
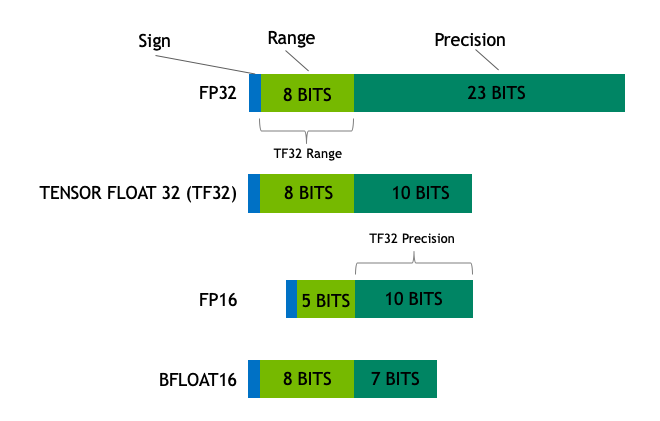
이미지 출처 : nvidia blog
Float32(FP32)는 IEEE 32-bit floating point의 표준으로 사용되며 넓은 범위의 floating numbers를 표현할 수 있습니다.
FP32의 8 bits는 지수부("exponent")에 사용이 되며, 23 bits는 가수부("mantissa")로 사용이 됩니다. 그리고 남은 1 bits는 부호(sign)을 위해 사용합니다.
FP16의 경우 5 bits는 지수부, 10 bits는 가수부, 1 bits는 부호를 위해 사용됩니다.
지수부와 가수부에 사용되는 bits수가 적은 만큼 FP16은 FP32에 비해 나타낼 수 있는 실수 범위가 적습니다.
이에 FP16의 경우 overflowing의 문제에 직면할 수 있습니다.
예로, 10k * 10k의 연산을 통해 100M의 결과가 나왔다면 FP16의 최대 범위는 64K이기에 해당 연산의 결과는 NaN 값으로 변해 기존의 연산 결과까지 망가질 수있습니다.
주로 loss scaling 기법을 통해 이런 문제를 극복하지만, 항상 이러한 문제를 해결하는 것은 아닙니다.
이러한 문제를 해결하기 위해 새로운 format인 bfloat16(BF16)이 등장하였습니다.
BF16의 경우 FP32와 같이 8 bits를 지수부에 사용하고 7 bits를 가수부에 사용합니다.
이는 BF16의 경우 FP32와 같은 동적 범위를 가질 수 있지만 3 bits 만큼의 precision을 FP16에 비해 잃는 다는 것을 알 수 있습니다.
이는 현재 큰 숫자에는 전혀 문제가 없지만 그럼에도 precision은 FP16에 비해 떨어집니다.
NVIDIA는 TensorFloat-32(TF32)라는 precision format을 공개했습니다.
이는 BF16과 같은 동적 범위(8 bits)와 FP16과 같은 precision(10 bits)를 사용하여 총 19 bits를 사용합니다. 이는 현재 내부적으로 특정한 연산을 수행할 때만 사용됩니다.
ML에선 FP32를 full precision(4 bytes), BF16와 FP16을 half-precision(2 bytes)라고 부릅니다.
int8의 경우 8-bit 표현이므로 2^8인 [0,255] 혹은 [-128,127]의 범위를 표현할 수 있습니다.
이상적인 training과 inference를 위해서는 FP32가 사용되어야 합니다.
하지만 이는 BF16 or FP16보다 2배의 시간이 소요됩니다.
그렇기에 mixed precision이라는 방법을 사용합니다.
이는 forward와 backward에는 속도를 늘리기 위해 FP16 or BF16이 사용되며, FP16과 BF16은 FP32 main weights를 update하는데 사용됩니다.
학습 중에 main weights는 항상 FP32 포멧으로 저장되어 있습니다.
하지만 inference에서는 half-precision도 충분히 좋은 퀄리티를 보장합니다.
이는 half precision을 사용하여 half GPU에서도 full precision과 같은 결과를 낼 수 있다는 점을 시사합니다.
앞서 소개한 BLOOM-176B을 bfloat16을 사용하여 학습한다면 176 * 10^9 * 2 bytes 즉, 352GB의 VRAM이 필요합니다.
이는 앞서 소개했듯이 적은 GPU로는 사용하기 힘듭니다.(A100 80GB * 5 이상 요구)
그런데 만약 다른 data type을 사용하여 더 적은 memory를 사용할 수 있다면 어떨가요?
Introduction to model quantization
실험적으로 4-byte FP32와 절반 사이즈인 2-byte BF16/FP16의 inference 성능은 비슷하다는 것을 알 수 있습니다.
이보다 더 줄이면 좋겠지만 그럴 경우에는 inference 결과가 드라마틱하게 나빠지기 시작합니다.
해당 챕터에서는 8-bit quantization 즉, 1/4로 모델 사이즈를 줄이는데 이는 단지 half precision을 반으로 쪼개는 방식으로 수행되지는 않습니다.
Quantization(양자화)는 본질적으로 한 data type을 다른 data type으로 반올림하며 수행됩니다.
예로 들어 [0,9]와 [0,4]의 range를 갖는 data type이 있다고 가정할 때 첫 번째 data type의 4는 두 번째 data type의 2로 반올림 될 수 있습니다.
또한 첫 번째 data type의 3은 두 번째 data type의 1 혹은 2로 변형되는데 주로 2로 변형됩니다. 이렇 듯 4와 3 모두 2로 변경되기에 양자화는 정보 손실로 이어질 수 있는 노이즈가 많은 프로세스입니다.
8-bit 양자화로 주로 사용되는 기술은 zero-point 양자화 그리고 absolute maximum 양자화 입니니다.
두 기술의 경우 floating point values를 int8(1 byte) values로 매핑합니다.
예로 들어 zero-point 양자화에서 [-1.0,1.0]의 range를 [-127,127]의 range로 양자화 할 때 원본 데이터를 복구하기 위해서는 같은 양자화 수치인 127로 나눠야합니다.
예로 0.3은 0.3*127을 통해 38.1이 되며 반올림에 의해 38로 변환됩니다.
이를 복구할 때는 38/127을 통해 0.2992 즉, 0.0008의 양자화 에러가 발생합니다.
이와 같은 오류는 누적되며 역전파되어 모델 성능 저하를 야기합니다.
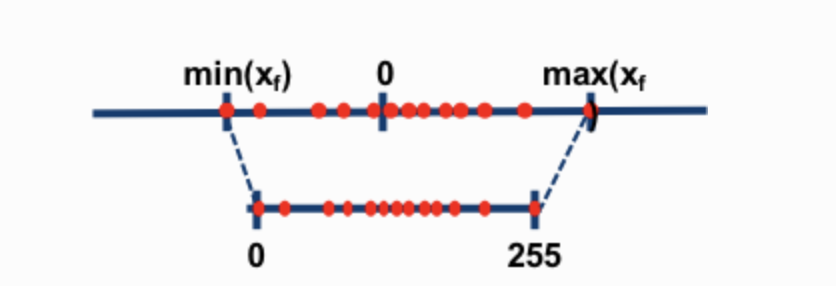
이미지 출처 : blog
그렇다면 absmax 양자화는 어떨까요?
예로 [1.2, -0.5, -4.3, 1.2, -3.1, 0.8, 2.4, 5.4] 다음과 같은 벡터가 존재할 때 절대값이 가장 큰 값은 5.4입니다.
해당 값과 127을 나누면 23.5(127/5.4)라는 값을 얻을 수 있고 해당 값이 scaling factor입니다.
이를 다른 vector에 곱하면 [28, -12, -101, 28, -73, 19, 56, 127] 다음과 같이 양자화된 벡터를 얻을 수 있습니다.
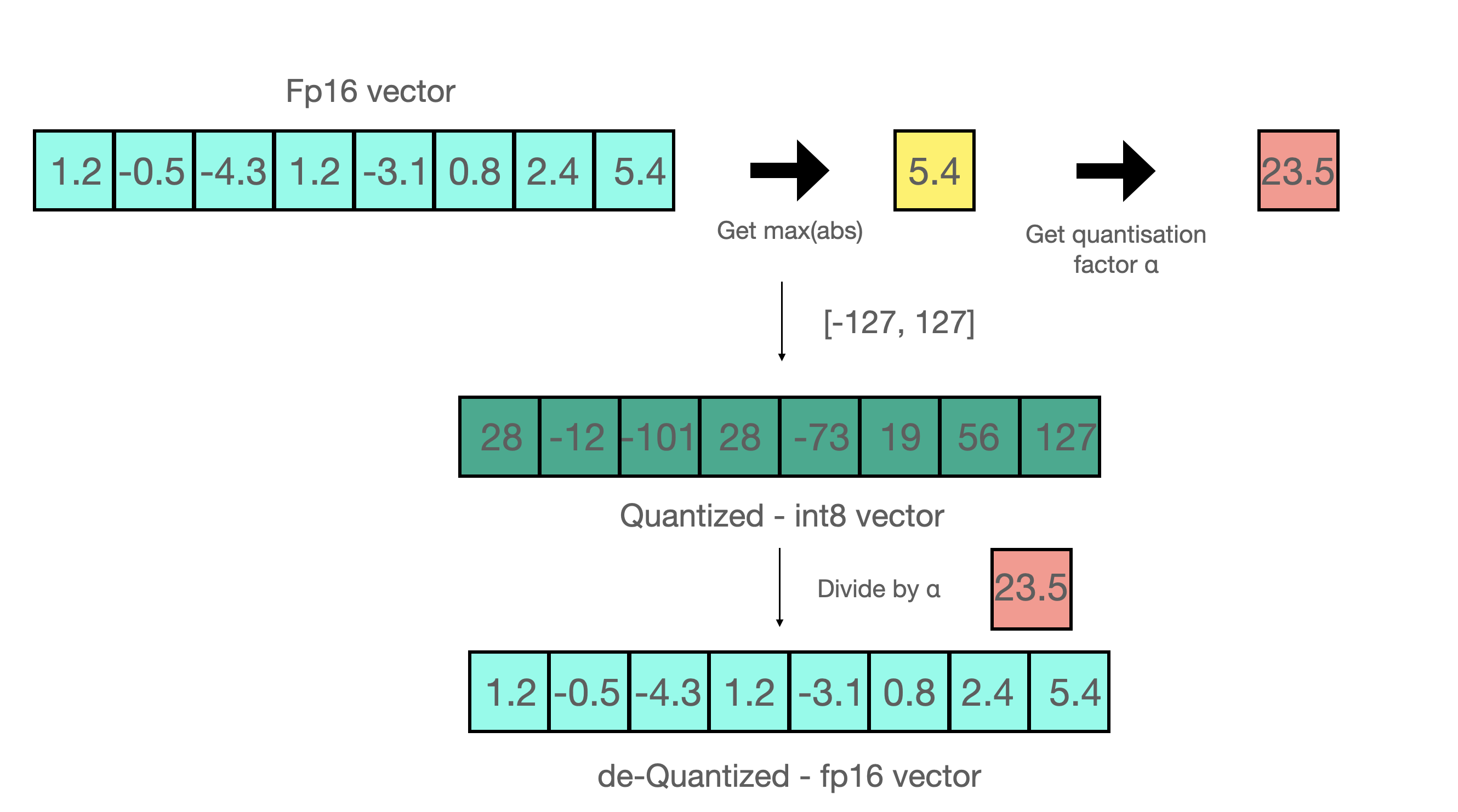
이러한 방식은 row-wise or vector-wise 양자화와 같은 다양한 방법에 적용될 수 있습니다.
예로 들어 A*B=C와 같은 행렬 곱이 있을 때 A의 row들의 최대값 B의 column들의 최대값을 각각 구해 scaling factor를 구하고 이를 적용한 뒤 곱을 하면 C를 얻을 수 있습니다.
또한 FP16으로 돌아갈 때는 A와 B의 외적을 수행하면 됩니다.
이는 A가 hidden states B가 weight일 때 양자화된 값을 얻는데 사용됩니다.
하지만 이러한 int8 양자화는 FP16에 비해 15~23%정도 추론속도가 늦는 걸로 알려져있습니다.
정리
양자화를 하는 목적은 모델의 크기를 줄이기 위해서입니다.
모델의 크기는 파라미터와 precision으로 결정되는데 파라미터는 줄일 수 없기에 precision을 줄여 모델의 크기를 줄이는 방법이 양자화입니다.
이를 위해 FP32 -> Half precision(BF16, FP16) -> int8의 순으로 연구가 진행되었으며 Half precision의 경우 inference의 성능이 full precision과 비슷하기에 그대로 사용되었으며 half precision을 그냥 반으로 나누어 quater precision(8 bits)를 만들 경우 성능이 드라마틱하게 떨어지기에 absmax 양자화 방식을 사용하여 mapping을 통해 int8 양자화를 진행하였습니다.
하지만 아직도 170B 모델을 VRAM에 올리려면 170GB의 VRAM이 필요합니다.
그렇기에 나온 것이 QLoRA입니다.
QLoRA
해당 논문에서는 4-bits 양자화와 LoRA를 활용하여 65B의 모델을 48GB 싱글 GPU로 fine-tuning을 하는 것에 성공했습니다.
일반적으로 65B의 모델을 사용하려면 FP32의 경우 VRAM 260GB+ Half precision의 경우 VRAM 130GB + 가 필요한데 해당 방식을 사용하면 단지 48GB 싱글 GPU로 fine-tuning이 가능합니다.
그렇다면 어떻게 해당 논문은 model size를 줄일 수 있었을까요?
해당 논문에서는 LoRA와 3가지 테크닉을 통해 model size를 줄입니다.
LoRA에 대해서는 앞선 포스트를 보시면 좋을 것 같습니다.
4-bit NormalFloat Quantization(NF4)
먼저 첫 번째 테크닉입니다.
NF4 data type의 경우 Quantile Quantization으로 이루어져있습니다.
이는 각각의 quantization bin이 input tensor로 부터 할당된 값과 같도록 보장하는 정보 이론적으로 최적의 data type입니다.
Quantile quantization은 input tensor의 quantile을 추정하는 경험적 누적 분포 함수로 동작합니다.
쉽게 설명해서 Quantile Quantization은 말 그대로 분위수를 통한 양자화입니다.
분포 함수를 통해 input tensor에 대한 분위를 추정하는 방식으로 동작합니다.
하지만 이러한 양자화 방식은 느리다는 큰 단점을 가지고 있습니다.
이를 위해 SRAM 양자화 방식과 같은 빠른 Quantile Quantization 방법을 사용할 수도 있지만 이 또한 Quantile Quantization 알고리즘의 문제인 outlier에서의 큰 양자화 오류에서는 벗어나지 못합니다.
이러한 비싼 연산비용과 오류는 input tensor가 양자화 상수까지 고정된 분포에서 나온다면 피할 수 있습니다.
그렇기에 학습된 nueral network weights는 주로 zero-centered한 정규분포 형태를 띄므로 주어진 weights를 [-1,1]의 범위에 맞게 표준편차를 이용하여 스케일합니다.
즉 정규분포 형태를 띄도록 양자화를 하여 속도와 error를 줄이는 방식을 선택하였습니다.
Double Quantization
두 번째 테크닉은 Double Quantization입니다.
해당 테크닉은 양자화 상수를 양자화하여 메모리를 줄입니다.
이를 논문의 예를 통해 살펴보겠습니다.
먼저 32-bits의 상수와 blocksize인 64를 통해 양자화 상수를 만든다고 가정하면 파라미터 당 32/64 즉 0.5 bits를 평균적으로 더합니다.
이 때 Double Quantization을 사용하면 첫 번째 양자화 상수를 두 번째 양자화의 input으로 사용합니다.
그렇기에 는 와 로 변합니다.
이를 수로 변환하면 => 8/64, => 32/64 * 256입니다.
여기서 256이 추가된 이유는 으로 한 번 더 양자화 할 때 성능 저하를 줄이기 위해 8-bits quantization에 사용된 256 block size를 사용하기 때문입니다.
그렇기에 기존 32/64 => 0.5 -> 8/64 + 32/64*256 => 0.127로 약 0.373 bit를 줄일 수 있게 됩니다.
Paged Optimizers
마지막 테크닉은 Paged Optimizers입니다.
이는 간단하게 OOM이 발생할 때 CPU RAM or Disk의 메모리를 사용하여 메모리의 한계를 늘리는 방식입니다.
이러한 방식으로 요구되는 메모리를 획기적으로 줄일 수 있었으며 다음 표와 같이 성능까지 준수하게 뽑아내는 것을 알 수 있습니다.
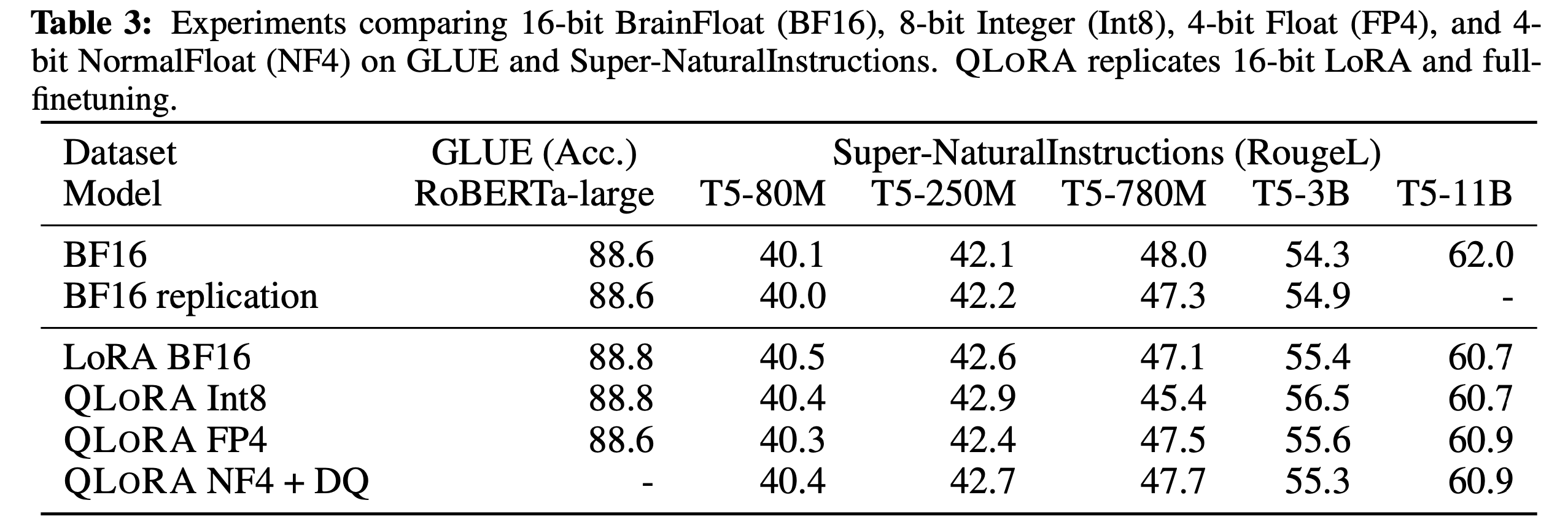
Broader Impacts
해당 연구는 최초로 single consumer GPU를 통해 33B 모델과 65B 모델을 single professional GPU를 통해 fine-tuning하는데 성공했습니다.
이 것은 a big win for the accessibility of state of the art NLP technology이라고 표현하며 추후 모바일 폰에 LLM이 해당 기술을 통해 들어갈 수 있음을 시사합니다.

너무 좋은 글 감사합니다!!