Fine-Tuning Stable Diffusion
앞선 글에서 Stable Diffusion을 fine-tuning하는 다음과 같은 방법들을 소개하였다.
- Textual Inversion : text encoder에 새로운 words를 적은 데이터셋으로 학습할 수 있다.
- Dreambooth : UNet을 fine-tunes 할 수 있는 방법이다.
- Full Stable Diffusion fine-tuning : 충분한 데이터셋이 있다면 Full fine-tuning도 가능하다.
이번 글에서는 해당 방법들에 대한 소개와 적용 방법을 알아보고자 한다.
하지만 해당 방법을 알아보기 앞서 이를 쉽게 도와주는 Huggingface의 Accelerate에 대해 알아보고자 한다.
Accelerate
🤗 Accelerate is a library that enables the same PyTorch code to be run across any distributed configuration by adding just four lines of code! In short, training and inference at scale made simple, efficient and adaptable.
즉, Accelerate는 Multi-GPUs/TPU/fp16 등 세팅이 복잡한 환경 세팅을 단순히 코드 몇 줄 추가함으로 해결해준다.
Diffusers의 예시들이 Accelerate로 구성되어있기에 추가적인 정보는 accelerate 페이지에서 확인할 수 있다.
Full Stable Diffusion fine-tuning
Accelerate와 Diffusers를 통해 간편하게 Stable Diffusion 모델을 fine tuning 할 수 있다.
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export TRAIN_DIR="path_to_your_dataset"
accelerate launch --mixed_precision="fp16" train_text_to_image.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$TRAIN_DIR \
--use_ema \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--lr_scheduler="constant" --lr_warmup_steps=0 \
--output_dir="sd-pokemon-model"이 때 single 24GB GPU로 학습이 가능하지만 batch_size를 높이려면 30GB 이상의 GPU를 추천한다고 한다.
Inference도 간단하게 가능하다.
from diffusers import StableDiffusionPipeline
model_path = "path_to_saved_model"
pipe = StableDiffusionPipeline.from_pretrained(model_path, torch_dtype=torch.float16)
pipe.to("cuda")
image = pipe(prompt="yoda").images[0]
image.save("yoda-pokemon.png")DreamBooth

DreamBooth란 구글리서치에서 발표한 text-to-image 모델이다.
해당 모델의 메인 컨셉은 개인화가 가능한 text-to-image 모델이라는 것이다.
해당 모델을 설명하기 앞서 DreamBooth는 다음과 같은 성과를 얻었다.

해당 그림을 보면 DALL-E2는 새로운 contexts를 생성하지 못하며 숫자 3의 위치 또한 표현하지 못했다.
Imagen은 새로운 contexts를 생성하였지만 숫자 3의 위치를 표현하지는 못하였다.
즉 이는 다음과 같은 문제로 정의할 수 있다.
key visual features에 대한 높은 fidelity를 유지하면서 새로운 맥락의 사진을 생성하는 것은 어렵다.
하지만 DreamBooth는 이러한 문제를 해결하였다.
또한 단 몇 장의 이미지로 fine-tuning이 가능하면서, 기존 모델의 semantic knowledge를 보존할 수 있었다.
그렇다면 어떻게 이를 해결하였을까?
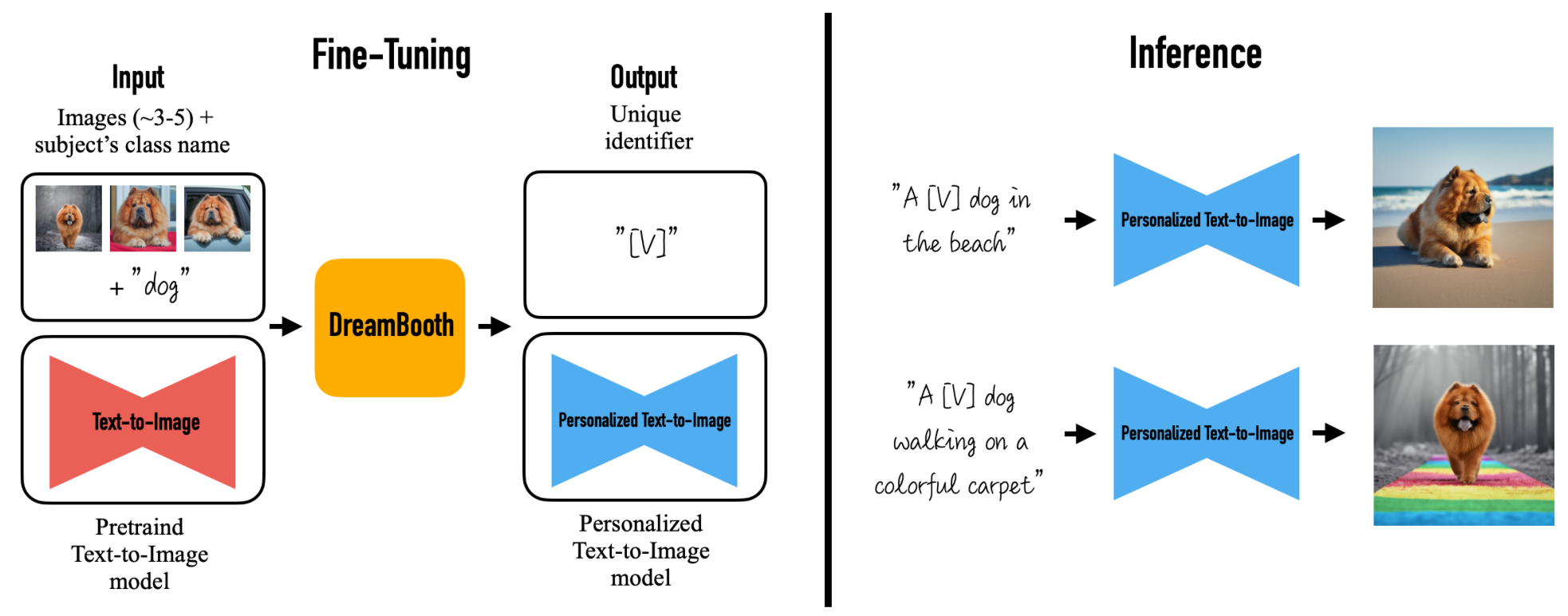
DreamBooth의 개인화는 Unique identifier 즉 "고유 식별자"([V])를 통해 가능하였다.
이는 인풋으로 몇장의 이미지와 class를 입력 정보로 사용하며 이를 DreamBooth를 통해 Fine-tuning을 하면, [V]에 대해 학습된 개인화 text-to-image 모델을 얻게된다.
먼저 키우고 있는 강아지 사진을 얻고자 할 때 [V]는 키우는 강아지이다.
그렇기에 학습 이미지는 키우는 개의 사진이며, Class는 dog이다.
이 때 주의해야하는 점은 class의 name이 [V]의 "상위 개념" 이여야 한다는 점이다.
그렇기에 개의 종이 아닌 dog으로 class의 name을 넣어줘야한다.
해당 이유는 모델의 원리를 이야기할 때 마저 설명하려고 한다.
그렇다면 상위 개념을 덮어씌우면서 앞서 언급한 문제 "기존 모델의 semantic knowledge를 보존"은 어떻게 이루어 질 수 있을까?
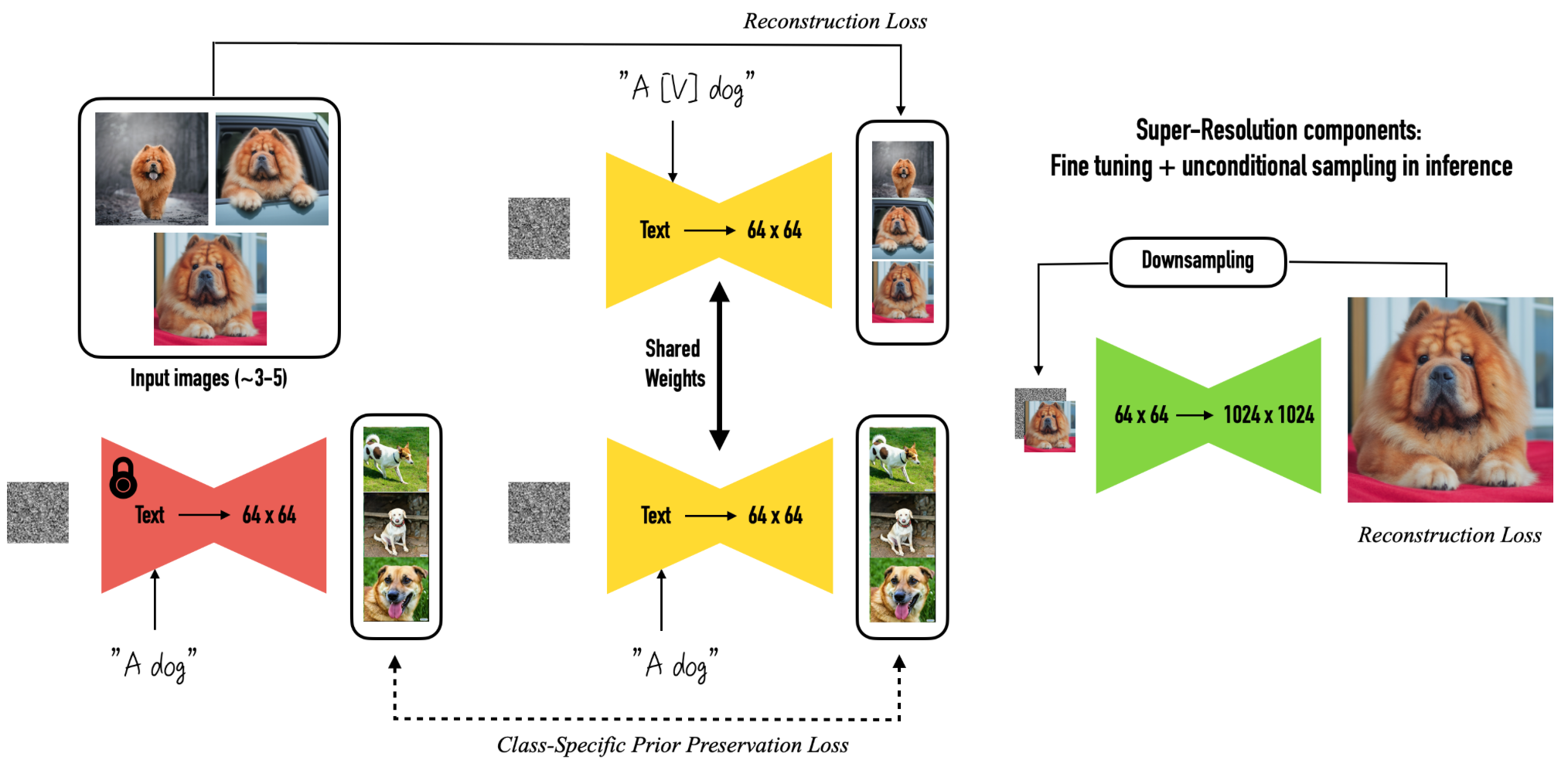
DreamBooth는 이를 class image(정규화 이미지)를 통하여 해결하였다.
학습하고자 하는 이미지인 "A [V] dog"에 대한 학습을 진행하며 동시에 기존 모델을 이용하여 "A dog" 이미지를 같이 학습하기에 기존 모델이 가진 class name에 대한 지식을 잊지 않도록 하는 것이다.
그렇기에 [V]의 상위 개념을 class name으로 사용한다.
정리하자면 DreamBooth는 "고유 식별자"와 기존 학습된 [V]의 상위 개념의 지식을 함께 사용함으로써 적은 이미지 수로 fine tuning을 가능케 하였고, 높은 Fidelity와 기존 모델의 정보의 왜곡을 줄일 수 있었다.

그렇기에 다음과 같은 다양한 상황을 만들 수 있다.
하지만 단점도 존재한다.

DreamBooth가 기존의 개념을 함께 활용하는만큼 학습 데이터가 적은 프롬프트에 대해서는 이미지를 잘 생성하지 못한다.
또한 입력한 이미지의 class와 프롬프트의 내용이 얽혀(entanglement) 개체의 모양이 변경될 수 있으며 프롬프트가 실제 이미지와 유사할 경우 과적합 현상이 발생하기도 한다.
DreamBooth with Diffusers
The train_dreambooth.py script shows how to implement the training procedure and adapt it for stable diffusion.
Diffusers는 간편하게 Stable Diffusion 모델에 DreamBooth를 적용할 수 있는 기능을 제공한다.
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export INSTANCE_DIR="path-to-instance-images"
export OUTPUT_DIR="path-to-save-model"
accelerate launch train_dreambooth.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--instance_data_dir=$INSTANCE_DIR \
--output_dir=$OUTPUT_DIR \
--instance_prompt="a photo of sks dog" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=1 \
--learning_rate=5e-6 \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=400또한 다음과 같은 코드로 간편하게 Inference 할 수 있다.
from diffusers import StableDiffusionPipeline
import torch
model_id = "path-to-your-trained-model"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
prompt = "A photo of sks dog in a bucket"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
image.save("dog-bucket.png")Textual Inversion
Textual Inversion이란 적은 수의 이미지로 novel concepts를 capturing하는 기술이다.
이는 텍스트 인코더에 새로운 "words"를 학습시킨다는 의미로 볼 수 있다.
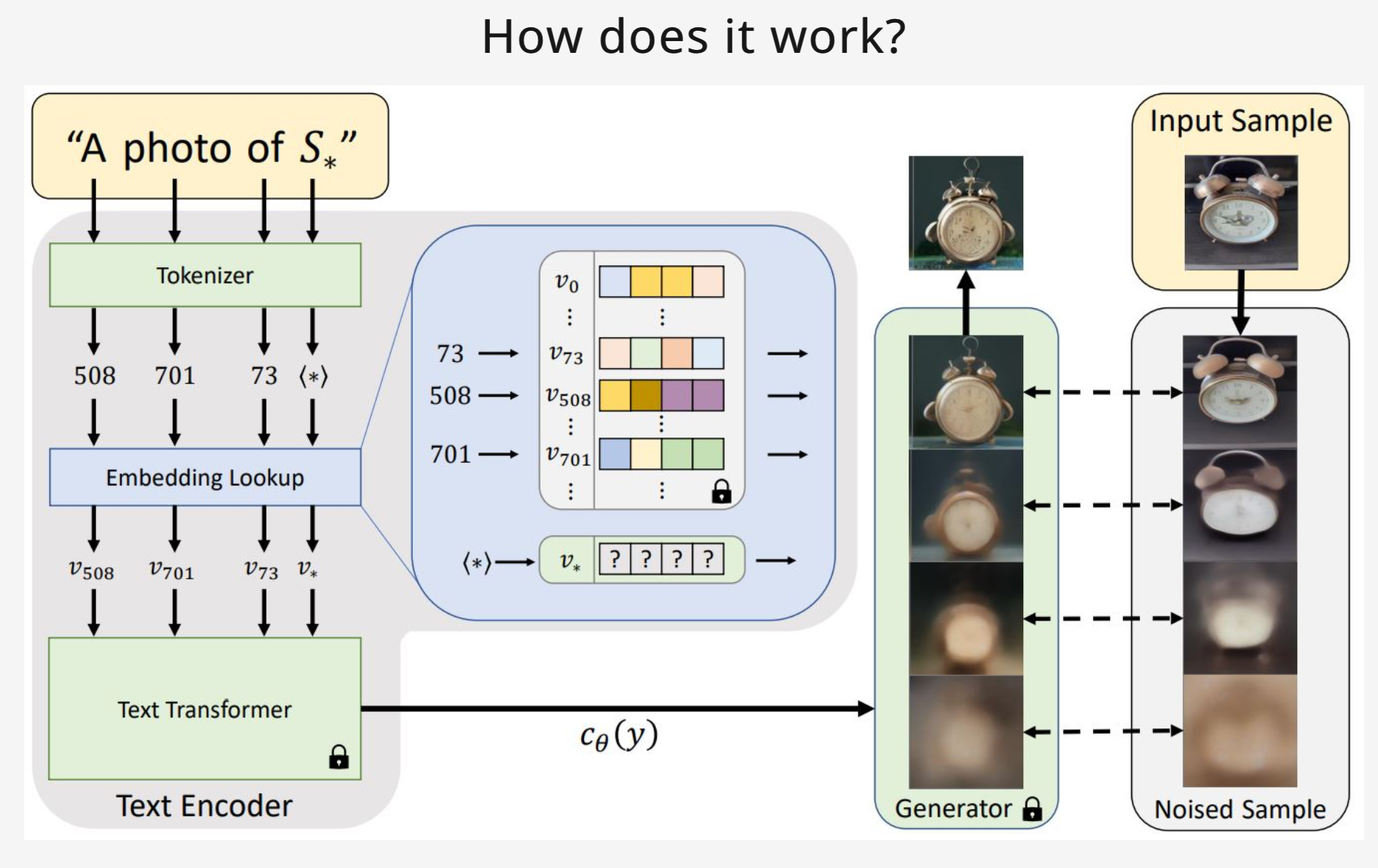
해당 매커니즘을 간단하게 설명하자면 text prompt가 Encoder에 들어가면 임베딩되는데 이 때 해당 저자들은 represent specific(이미지를 잘 설명하는)한 새로운 임베딩을 찾았고 이를 pseudo-words(입력된 모르는 단어)와 연결하여 frozen model에 새로운 단어를 추가하였다.
이에 저자들은 frozen model의 text-embedding space에서 inversion(적절한 latent vector를 찾는 과정)을 수행하였고, 이를 Textual Inversion이라고 칭했다.
Textual Inversion with Diffusers
Textual Inversion 또한 Accelerate와 Diffusers을 통해 간편하게 사용할 수 있다.
export MODEL_NAME="runwayml/stable-diffusion-v1-5"
export DATA_DIR="path-to-dir-containing-images"
accelerate launch textual_inversion.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$DATA_DIR \
--learnable_property="object" \
--placeholder_token="<cat-toy>" --initializer_token="toy" \
--resolution=512 \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--max_train_steps=3000 \
--learning_rate=5.0e-04 --scale_lr \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--output_dir="textual_inversion_cat"이는 V100 GPU 기준으로 1시간 이내의 시간이 소요된다고 한다.
Inference는 다음과 같다.
from diffusers import StableDiffusionPipeline
model_id = "path-to-your-trained-model"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to("cuda")
prompt = "A <cat-toy> backpack"
image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0]
image.save("cat-backpack.png")LoRA
LoRA에 대한 설명은 LoRA 논문 리뷰를 통해 볼 수 있다.
LoRA with Diffusers
LoRA는 LLM을 위해 고안되었지만 다양한 분야에 활용 가능했다.
이는 Stable Diffusion 모델의 UNet의 cross-attention layer에도 적용이 가능하였다.
이를 적용하면 다음과 같은 장점을 얻을 수 있다.
발췌 : huggingface blog
- 학습 속도가 상당히 빨라진다.
- 계산 요구 사항이 낮아진다. 기존 24GB VRAM을 요구했지만 이를 활용하면 11GB의 2080 Ti로도 학습이 가능하다.
- 학습된 파일 용량이 가볍다. 약 3MB
- 기학습된 가중치가 얼기에 망각을 학습에 의한 망각을 방지할 수 있다.
- Rank-decomposition matrices는 가볍기에(약 3MB) 옮기거나 공유하기 좋다.
- LoRA attention layers는 학습 정도를 scale 파라미터를 통해 조절할 수 있다.
학습 또한 간편하게 진행할 수 있다.
accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME --caption_column="text" \
--resolution=512 --random_flip \
--train_batch_size=1 \
--num_train_epochs=100 --checkpointing_steps=5000 \
--learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \
--seed=42 \
--output_dir="sd-pokemon-model-lora" \
--validation_prompt="cute dragon creature" --report_to="wandb"메모리의 효율성을 높여주는 xFormers 또한 다음 한 줄을 추가함으로써 적용할 수 있다.
--enable_xformers_memory_efficient_attention
Inference는 다음과 같다.
from diffusers import StableDiffusionPipeline
import torch
model_path = "sayakpaul/sd-model-finetuned-lora-t4"
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
pipe.unet.load_attn_procs(model_path)
pipe.to("cuda")
prompt = "A pokemon with green eyes and red legs."
image = pipe(prompt, num_inference_steps=30, guidance_scale=7.5).images[0]
image.save("pokemon.png")UNet의 cross-attention layers들을 학습했기에 해당 코드를 통해 unet에 학습된 LoRA layer를 붙여준다.
pipe.unet.load_attn_procs(model_path)
Riffusion은 StableDiffusionPipeline을 사용하지 않기에 RiffusionPipeline을 직접 수정해야한다.
해당 방법은 최종프로젝트 포스트를 통해 얘기할 예정이다.
출처 : dreambooth
발췌 : [논문 리뷰] Dreambooth의 원리와 기본적 이해
출처 : accelerate
출처 : textual-inversion
