
개념
- You Only Look Once
- 가장 빠른 객체 검출 알고리즘 중 하나
- 256x256 사이즈의 이미지
- 파이썬, 텐서플로 기반 프레임워크가 아닌 C++로 구현된 코드 기준 GPU 사용 시, 초당 170 프레임(170 FPS, frames per second)
- 작은 크기의 물체를 탐지하는데는 어려움
- FPS(Frame per second) : 영상에서 매 초당 보여지는 이미지 장면의 수, 인간의 눈이 1초당 8개의 이미지가 제시 되어야 하나의 자연스런 동작으로 인식
프레임이 높을수록 자연스런 움직임
YOLO 5
- YOLOv4에 비해 낮은 용량과 빠른 속도 (성능은 비슷)
- YOLOv4와 같은 CSPNet 기반의 backbone을 설계하여 사용
- YOLOv3를 PyTorch로 implementation한 GlennJocher가 발표
- Darknet이 아닌 PyTorch 구현이기 때문에, 이전 버전들과 다르다고 할 수 있음
실습
빵형의 개발도상국님의 영상을 응용해서 진행
- 영상에서는 권총 data를 이용해서 진행
- 실습을 할 때는 같은 roboflow사이트에
aquarium데이터셋을 이용해서 진행
데이터 다운로드
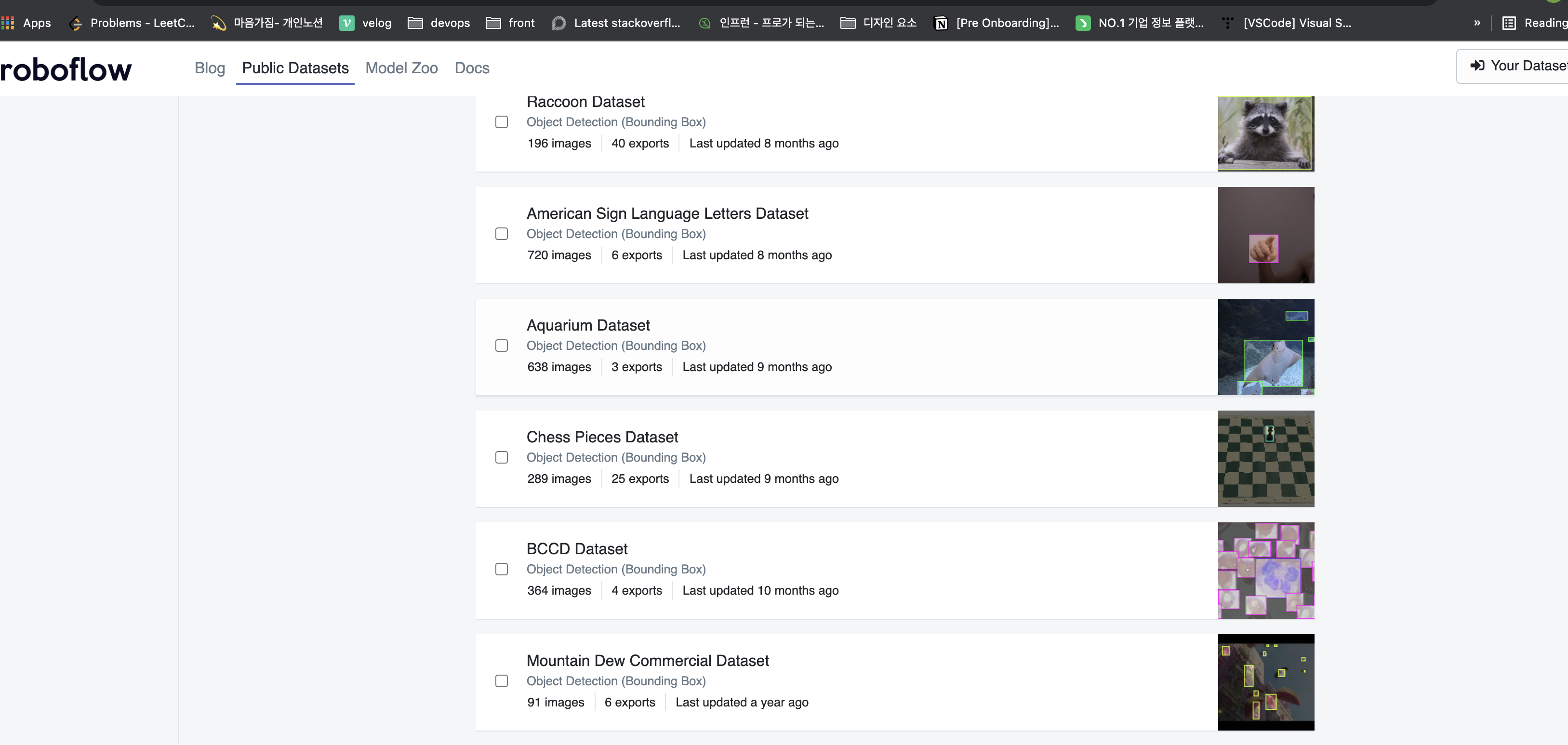
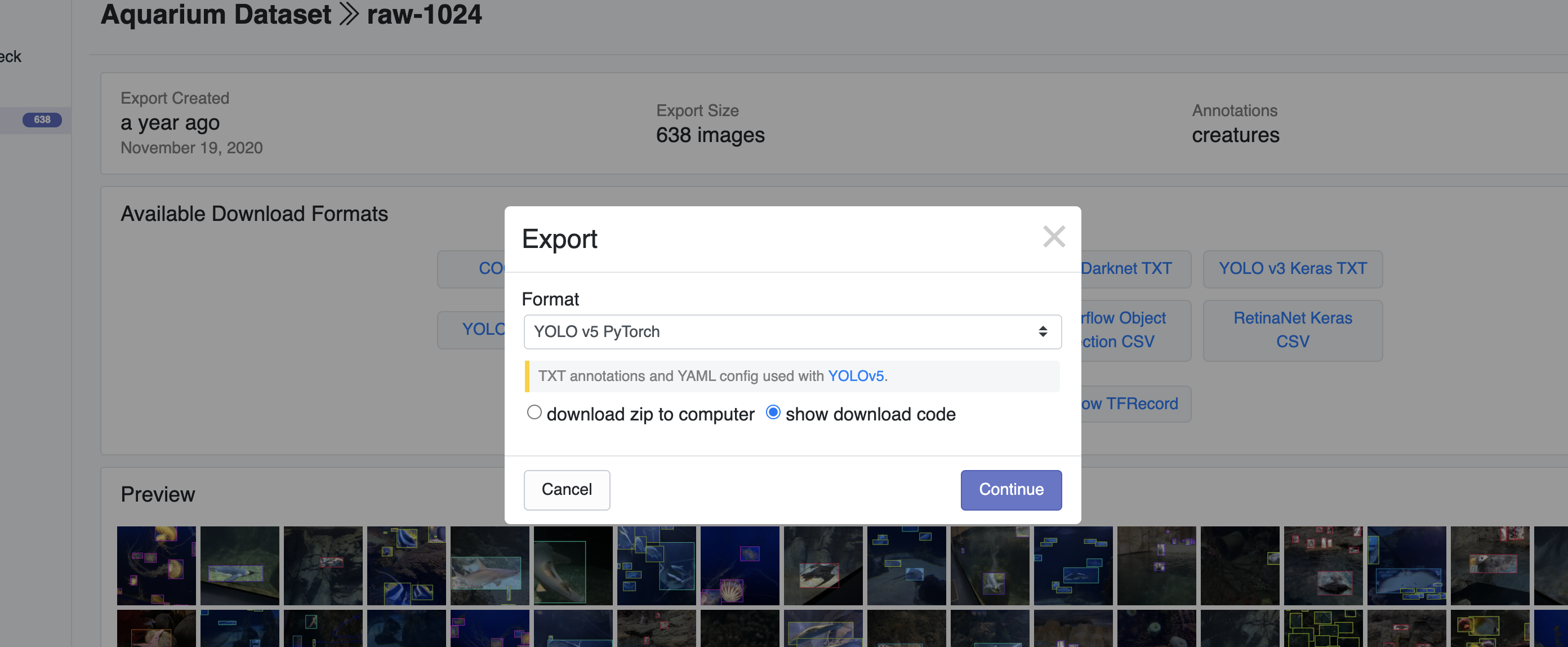 - 해당 데이터셋에 들어가서 다운로드를 누르면 다음과 같이 어떤 모델의 사용할지 선택할 수 있는 화면이 나온다.
- 해당 데이터셋에 들어가서 다운로드를 누르면 다음과 같이 어떤 모델의 사용할지 선택할 수 있는 화면이 나온다.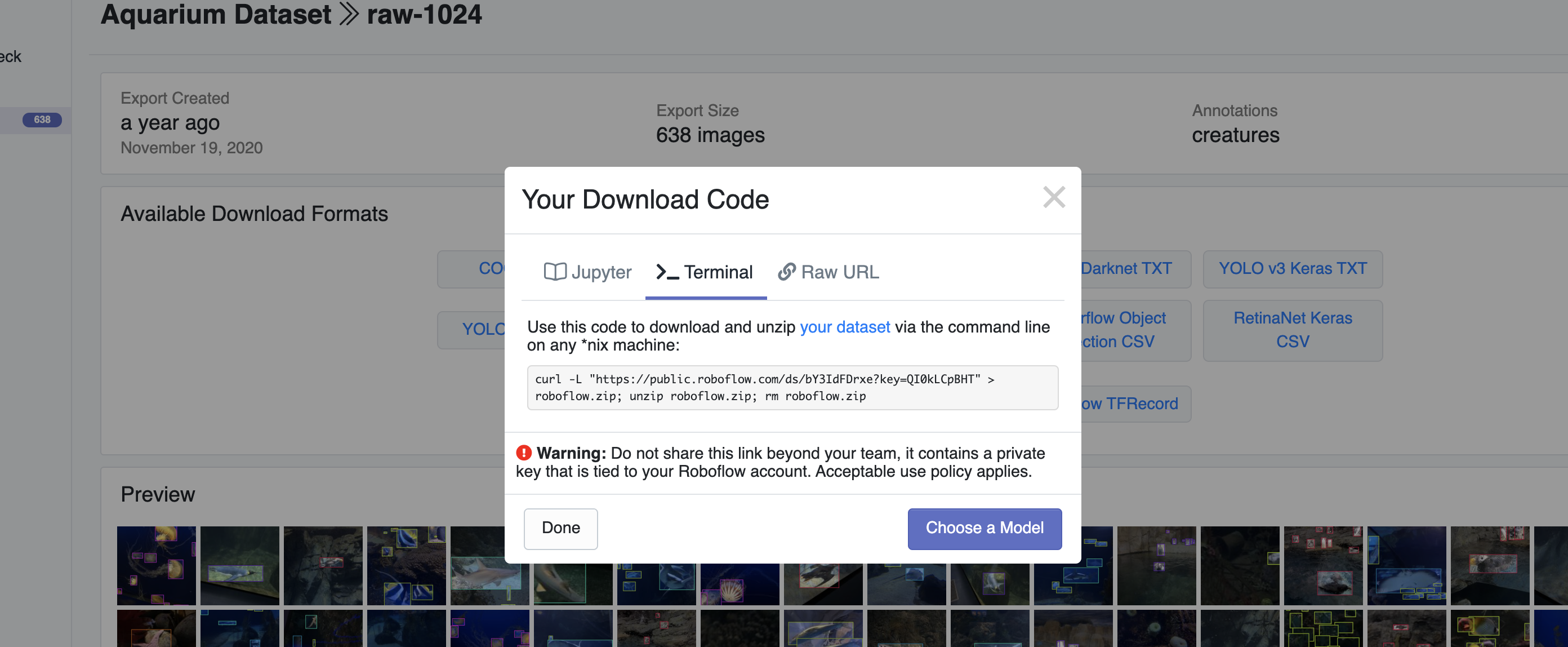 - 주피터 노트북에서 작업을 할 것이기 때문에 terminal code를 받고 복사해준다.
- 주피터 노트북에서 작업을 할 것이기 때문에 terminal code를 받고 복사해준다. 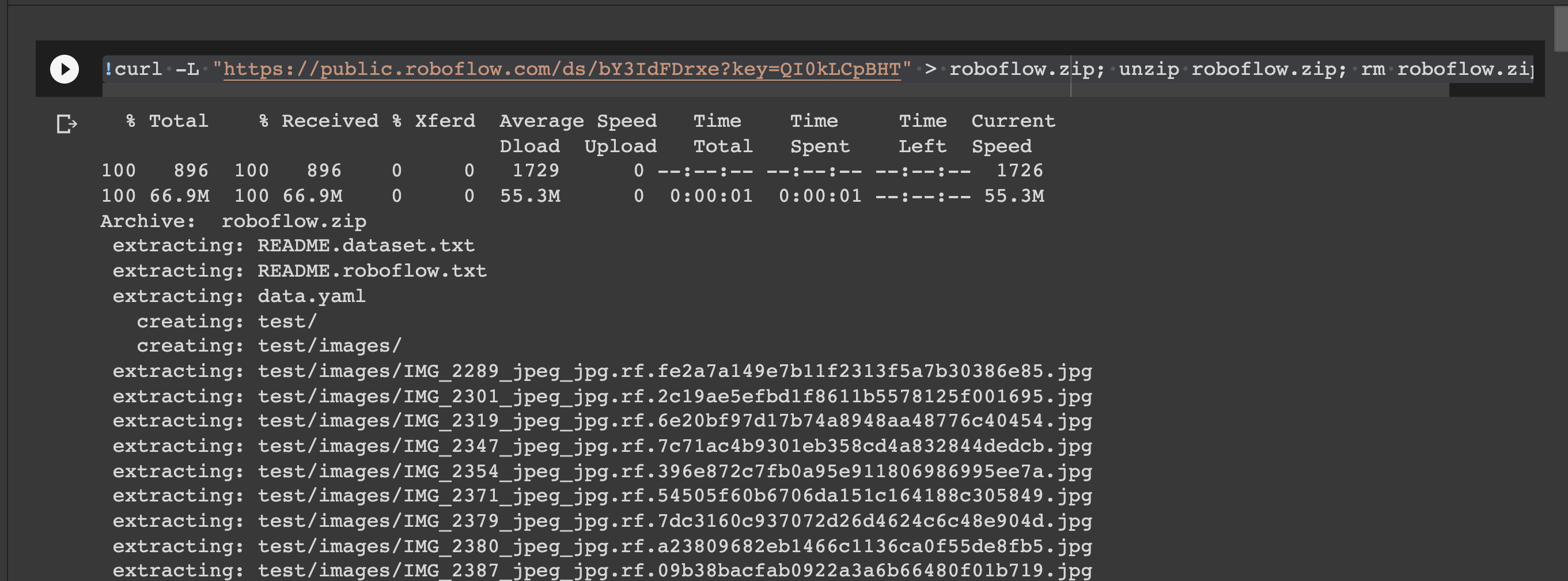 -
- curl로 해당 링크에 자료를 다운로드 받아준다.
환경설정
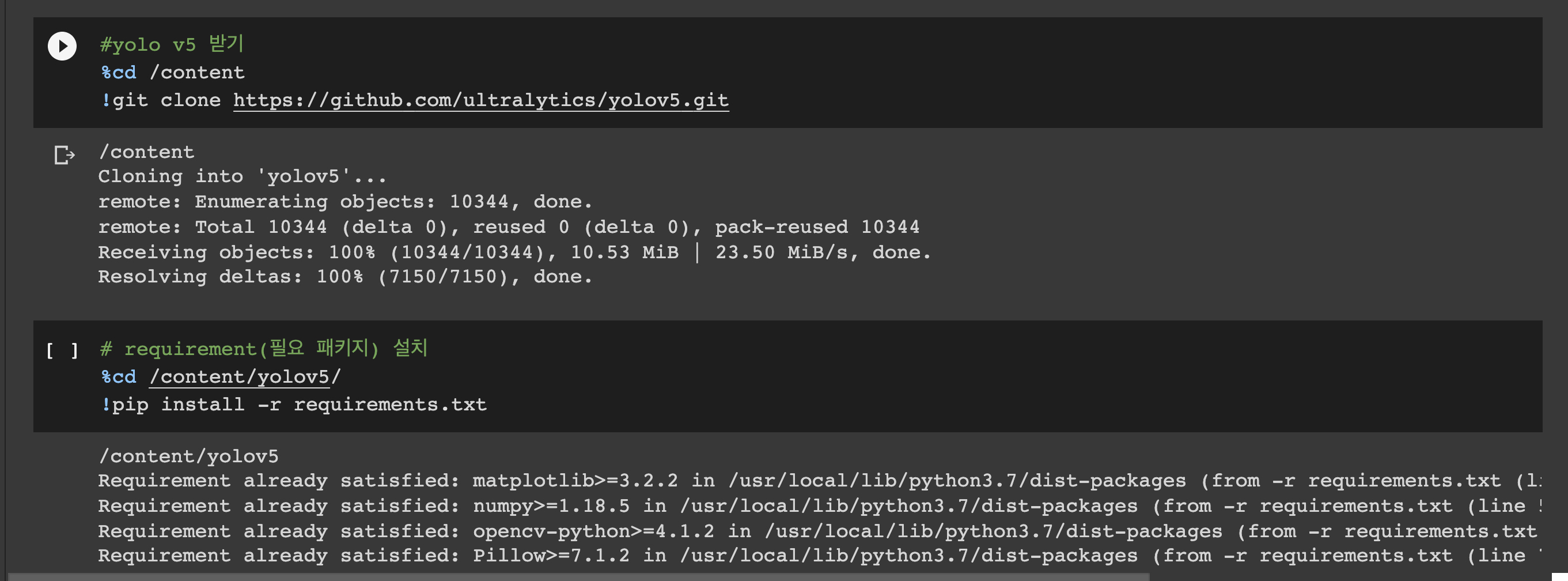
- 우선
yolov5를 git clone으로 다운로드 받아준다. - 그리고 해당 yolov5폴더에 있는 환경세팅 파일인
requirement.txt를 설치해준다.

- glob을 이용해서 해당하는 이미지들을 리스트에 담아둔다.
- 기존 영상실습에서는 train, test가 구분되어있지 않아 나누는 과정이 필요했지만 Aquarium 데이터셋은 구분이 되어있어서 불필요했다.
학습
%cd /content/yolov5/
!python train.py --img 416 --batch 16 --epochs 100 --data /content/dataset/data.yaml --cfg ./models/yolov5s.yaml --weights yolov5s.pt --name aquarium_yolov5s_resultsdirectory를 train.py가 들어있는 폴더로 이동한다음에 학습을 진행한다. 학습 조건은 yolov5 공식문서 train custom data에 나와있는 조건으로 진행했다. (epoch은 100으로 변경)
- cfg : 작은 사물에 대해서 측정하는
yolov5s로 진행 - weights : yolov5s.pt로 기존에 미리 학습된 모델
- name : 결과물이 들어갈 폴더
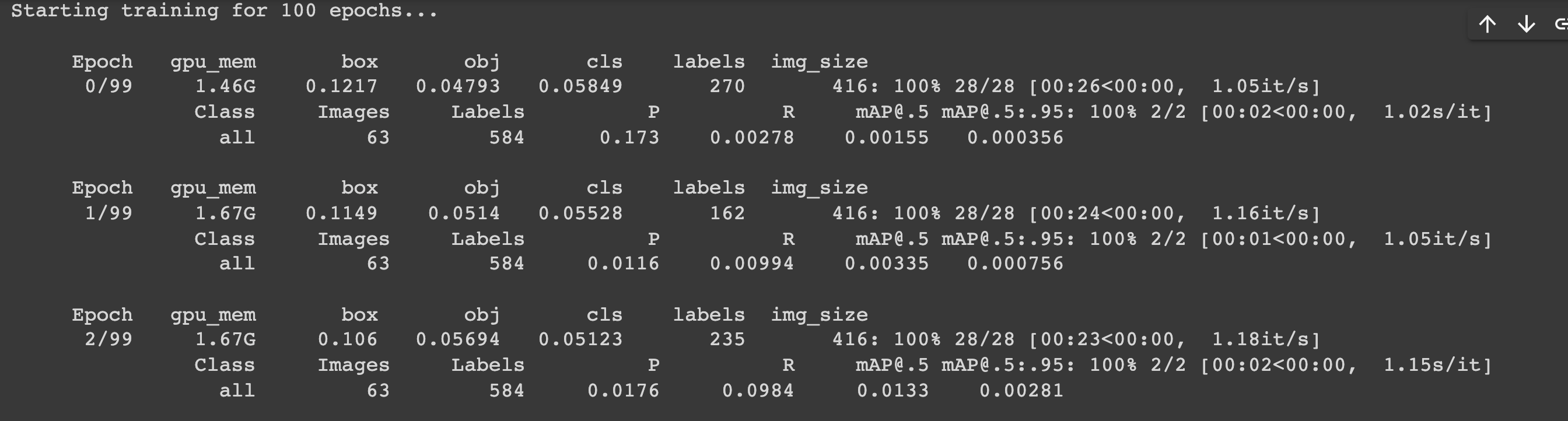
- 처음 학습을 시작할 때는
P : 0.173,R: 0.00278mAP: 0.00155정도로 낮았다.
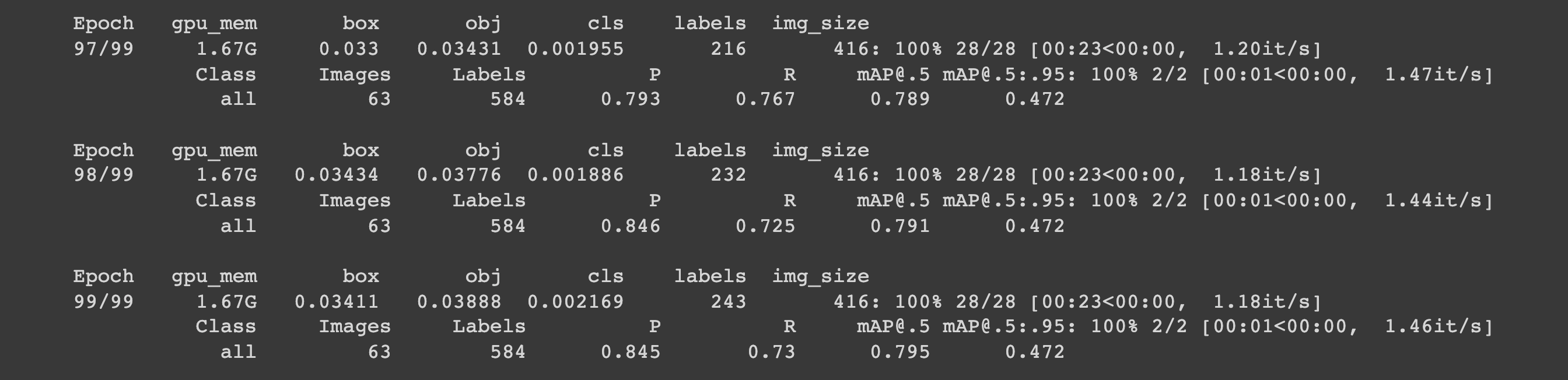
- 이후 마지막 100번쨰 학습 결과
P : 0.845,R: 0.73mAP: 0.795로 모델 성능이 향상된 것을 파악할 수 있다.
텐서 보드로 시각화
%load_ext tensorboard
%tensorboard --logdir /content/yolov5/runs/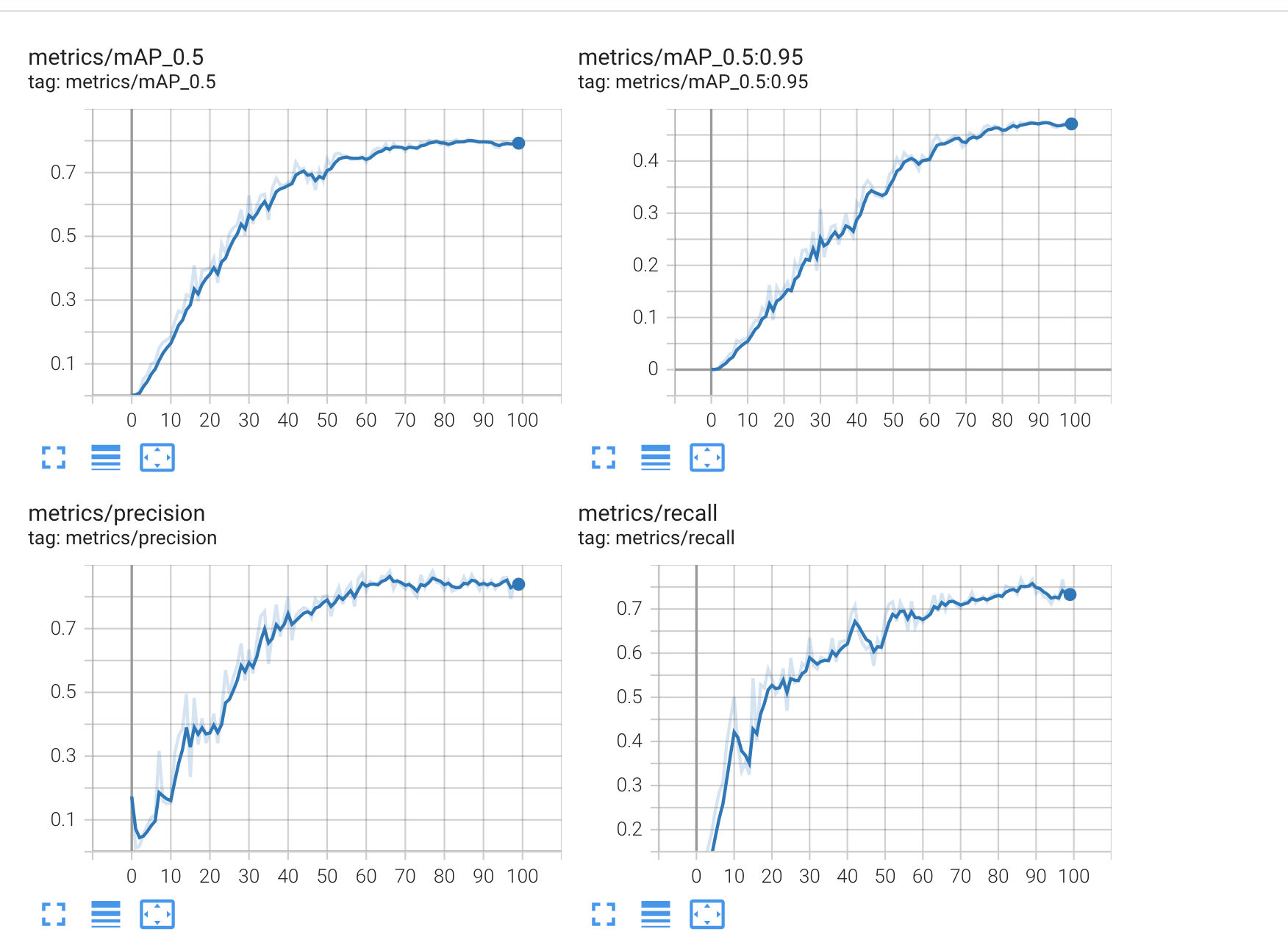
- mAP, Precision, Recall이 향상된 것을 볼 수 있다.
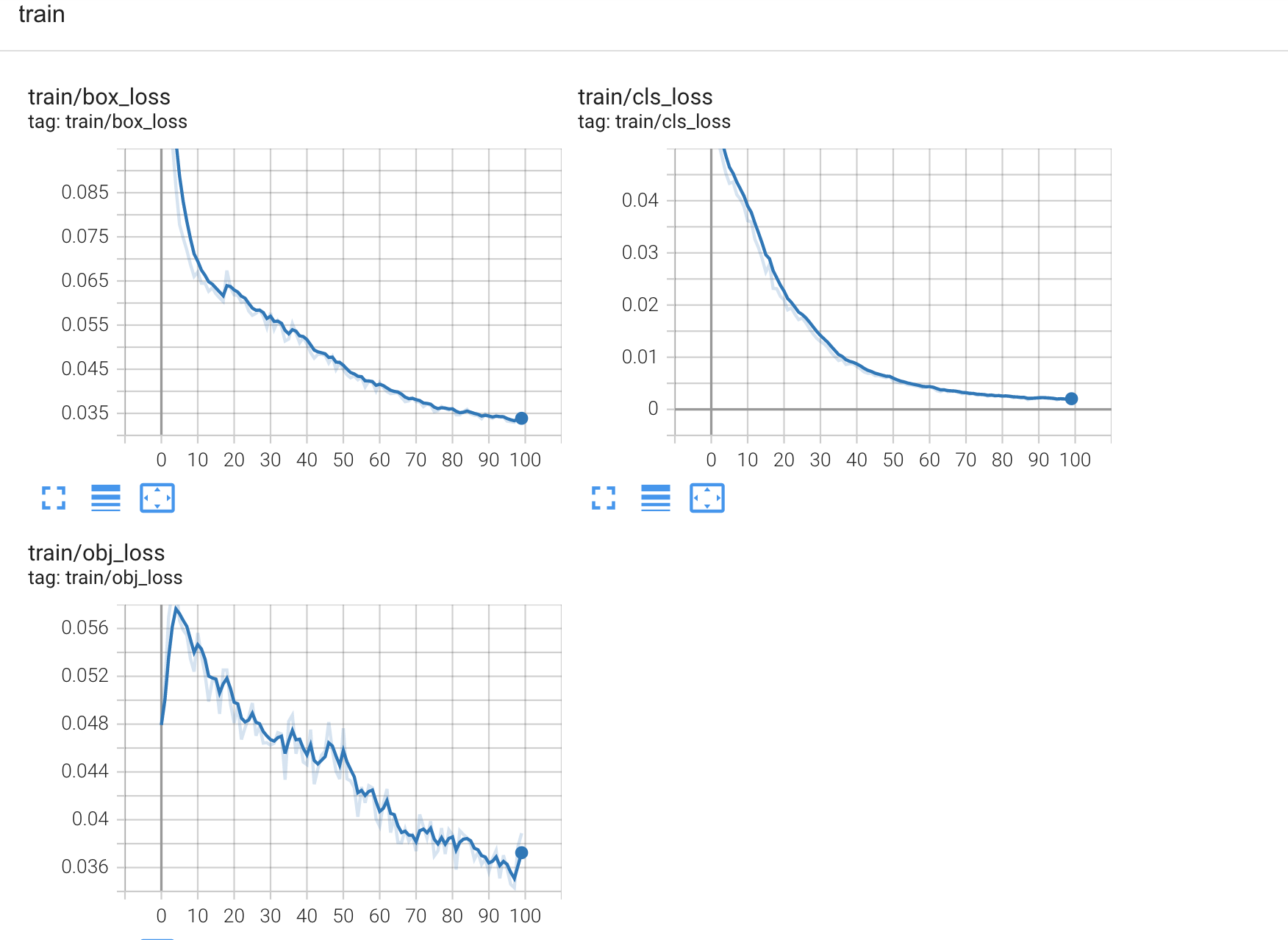
- 모델이 학습함에 따라 loss도 줄어든 것을 확인할 수 있다.
영상에 모델 적용해보기
위 지정한 폴더에 보면 weights 폴더에 학습된 결과가 있다. 이 학습된 모델로 이제 짧은 영상에 적용을 해보기로 했다.
따로 로컬에서 작업을 해도 되지만 이왕 코랩에서 하는 거 일치하기로 했다.
위에 버튼을 클릭해서 영상을 업로드를 하게 되면 해당 영상에 대한 주소를 가져올 수 있다.

!python detect.py --weights /content/yolov5/runs/train/aquarium_yolov5s_results2/weights/best.pt --source "{video_src}"
해당 영상에 대해서 경로를 변수에 지정을 하고 그 변수를 detect.py를 이용하여 객체 탐지를 진행해주면 된다.
결과

- 처음 한 결과 물고기는 대부분 인식이 되었는데 가오리가 인식이 안되었다.
.jpeg)
- 왜 가오리를 puffin이라고 하는지 이미지를 찾아보니 그럴 수도 있겠다 생각이 들었다.

- 가오리만 단독으로 있는 영상을 진행했는데 짧은 순간을 제외하고 대부분 fish, shark로 판단을 하였다.
- 이건 아무래도 yolov5s로 진행을 했는데 대상이 커버려서 그런 건 아닌가 싶기도 하다.
이미지를 학습할 때 라벨링된 데이터가 600장정도로 많지 않았고 그 중에 많은 경우 물고기였기 때문에 판단을 정확히 못한 것 같다.
.jpeg)
기록을 통해 한 걸음씩 성장ing!
재미있게 봤습니다!!ㅎㅎ