스타벅스 음료탭에 있는 음료에 관한 모델링을 해보기로 했습니다.
우선은 저희 조는 웹사이트 구성방식에 집중했습니다. 스타벅스 웹사이트는 다음과 같이 구성이 되어있습니다.

우선 음료탭을 클릭하면 위 이미지처럼 음료 카테고리를 고를 수 있습니다.
카테고리를 표현하는 카테고리 테이블은 다음과 같습니다. 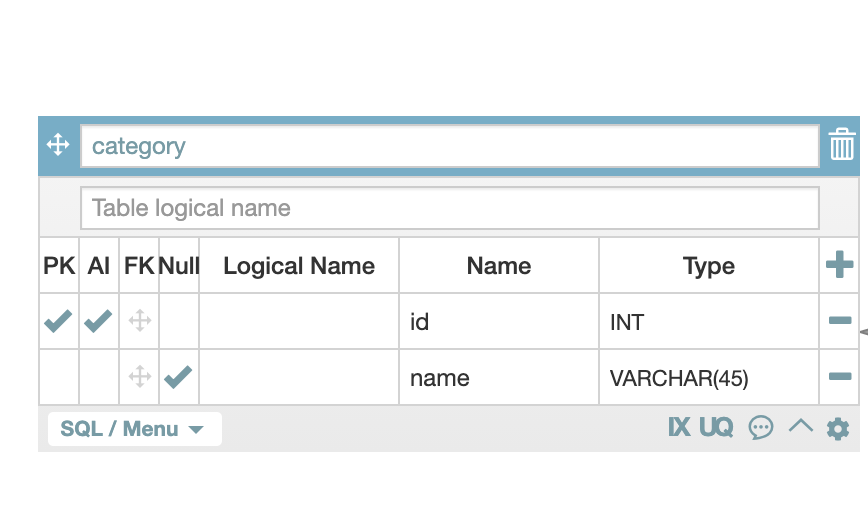
카테고리 테이블은 고유값인 id와 카테고리의 이름이 들어있습니다.
실제 테이블에 들어가는 값은 다음과 같습니다.
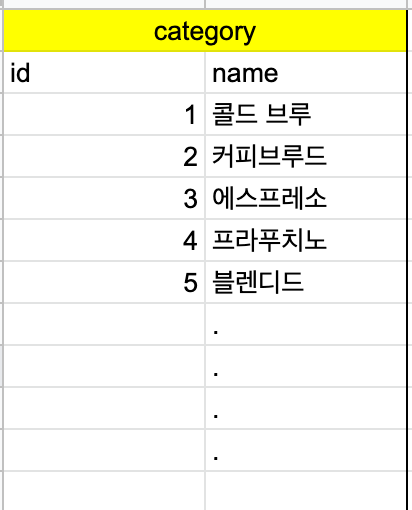
다음으로 한 음료의 카테고리를 고르면 이렇게 해당하는 음료만 모여서 확인이 가능한데 이 부분은 카테고리가 해당 id인 (예를 들면 콜드브루커피는 id=1인 경우)를 체크해서 결과를 표출하면 되기 때문에 처음에는 별도에 테이블을 구성했지만 중복되어서 별도의 테이블을 만들지 않았습니다.
다음으로 음료 상세페이지입니다. 각 커피를 눌러서 이미지를 확인해보면 이름,영양수치,상세설명,알레르기,상품이미지 등을 확인할 수 있습니다.
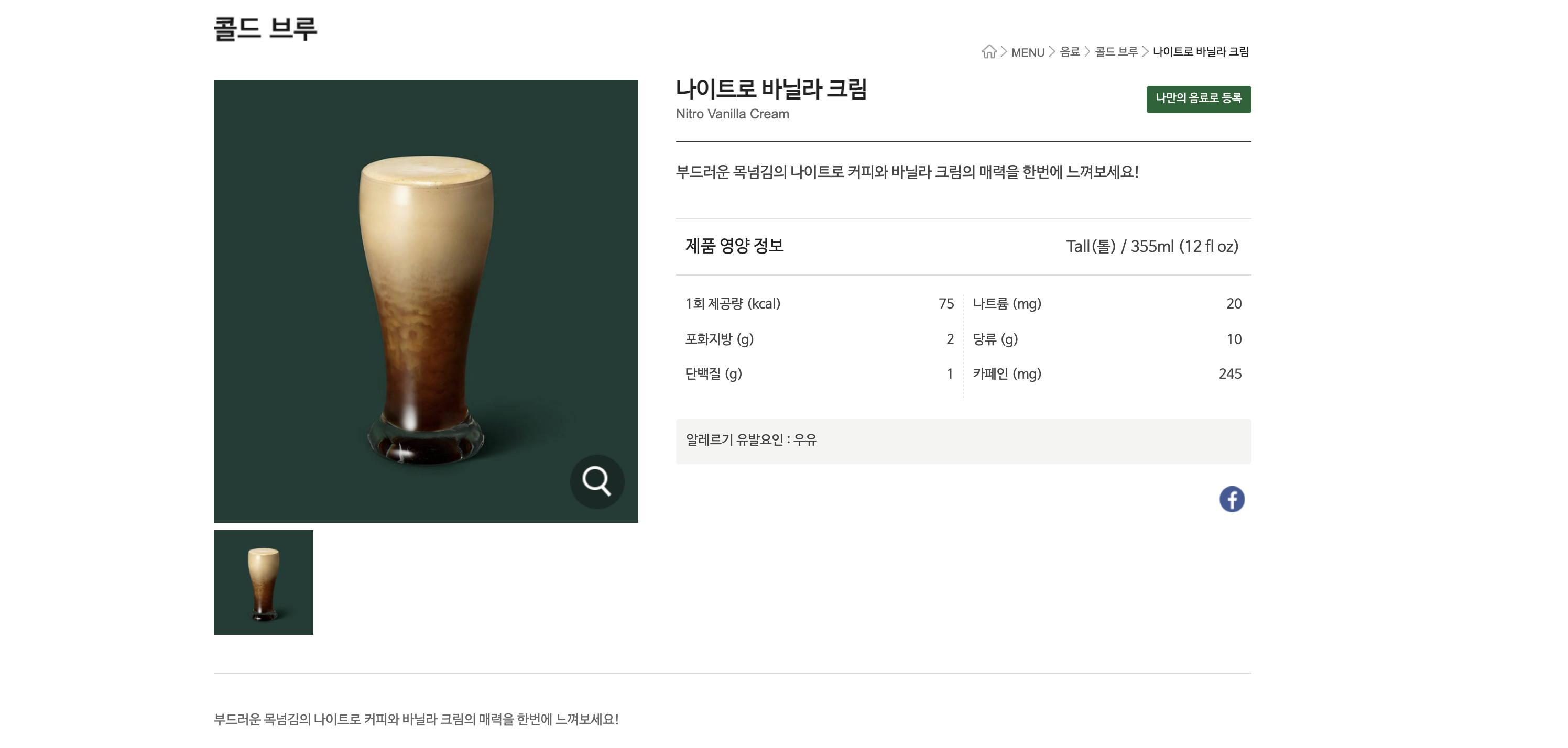
필드를 어떻게 구성을 할까 상의를 하다가 개발자 도구에 네트워크 탭에서 확인할 수 있는 자료가 있는지 확인을 해보았습니다. 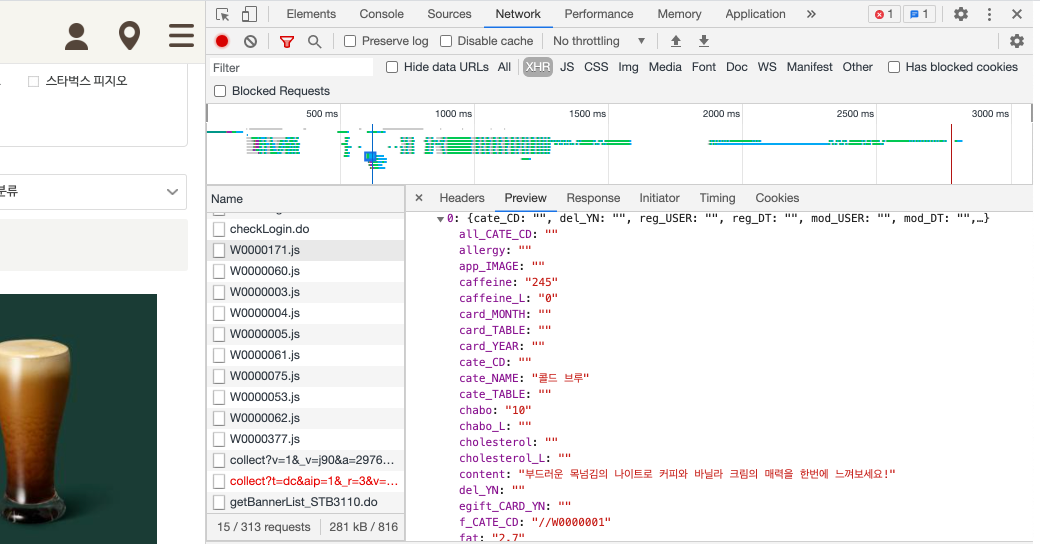
실제 여러가지 필드(caffein_L,chabo_L,cholestrol_L 등)가 있지만 실제 자료가 확인이 가능한 것 중심으로 데이터 테이블을 구성했습니다.
그렇게 구성을 한 결과 다음과 같은 테이블이 나왔습니다. 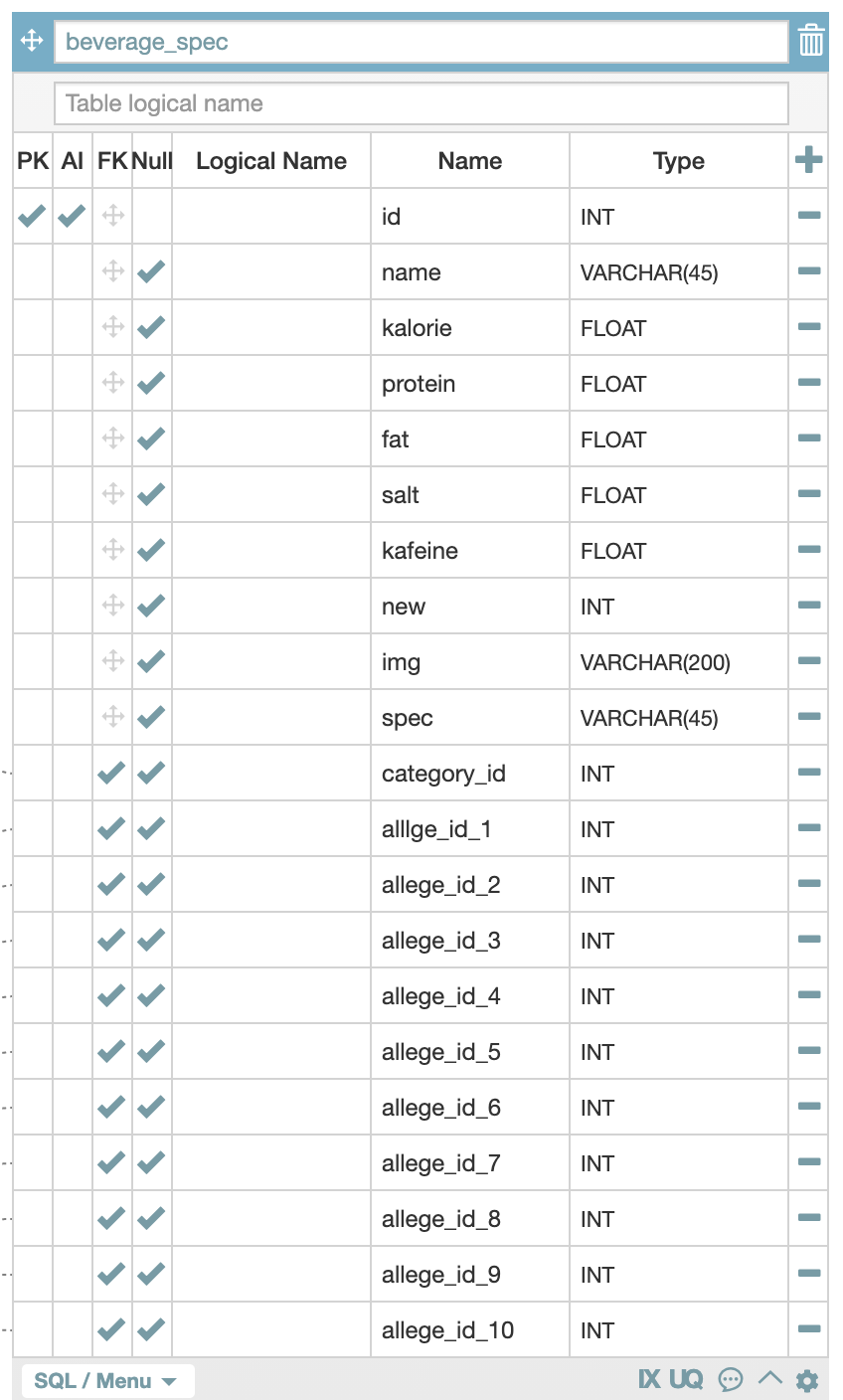
영양소 부분
영양소에 속하는 karolie,protein,fat,salt,kafeine을 따로 영양소라는 테이블로 떼어낼지 하나에 합칠지에 대해서 이야기를 나눴습니다. 그 결론은 하나로 합치기로 했습니다. 이유는 각 영양소 정보가 옵션에서 선택하는 것이 아닌 구체적인 수치로 구성이 됐기 때문에 고유값을 만들어 테이블을 대응해도 큰 의미는 없을 것이라 생각했습니다.
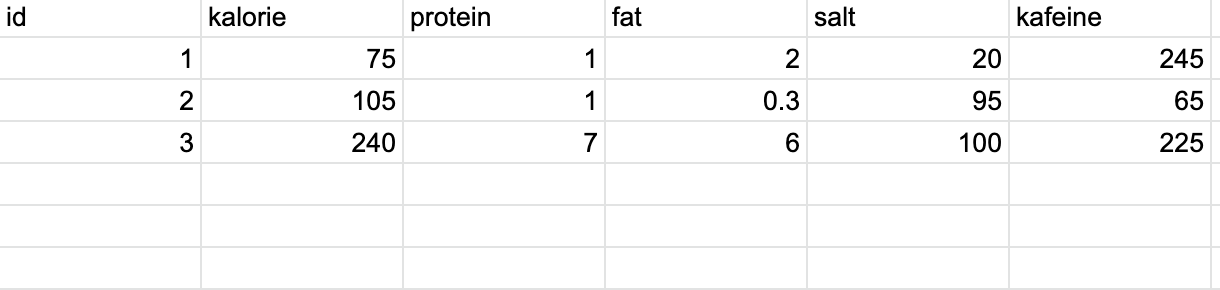
좀 더 자세히 이야기하면 위 3개의 행은 만일 별도의 영양소 테이블을 만들경우의 예입니다. id 1번에 해당하는 것은 나이트로 바닐라크림음료인데 이 1번이 원래 음료 테이블에 들어간다하더라도 직관적으로 정보를 확인하기가 어렵습니다. (각 정보가 표시되지 않고 nutri_id 1로만 표현되기 때문에)
그래서 별도의 테이블로 구성하기 보다는 합치는 것이 좋다고 생각했습니다.
(만일 영양소 정보만 별도로 관리하고자 하고 -새로 추가된 영양소 정보가 많아질때 - 이것을 테이블로 만든다면 이름을 넣어 다음과 같이 구성해도 될 것 같습니다.- 과제에서 영양소를 활용하는 별다른 언급(저 고칼로리 구분 등)은 없어서 배제했습니다.)

- 하나의 데이터베이스 테이블에 자료를 다 기록을 한다면 조회가 빠르지만 새로운 자료 추가될 때 열이 추가됌( 데이터베이스 구조가 다름)
- 별도의 데이터베이스 테이블에 자료를 기록을 한다면 별도로 관리가 유용하지만 쿼리를 짤떄 추가적으로 고려해야 할 사항이 생긴다.
알러지부분
알러지부분이 꽤 복잡하고 지저분해보이는데 이렇게 구성을 한 이유는 한 음료가 한가지의 알러지만 가지는 것이 아니다" 이 부분 때문입니다.
예를 들어서 가장 충격적이었던 음료는 제주 까망 라떼입니다. 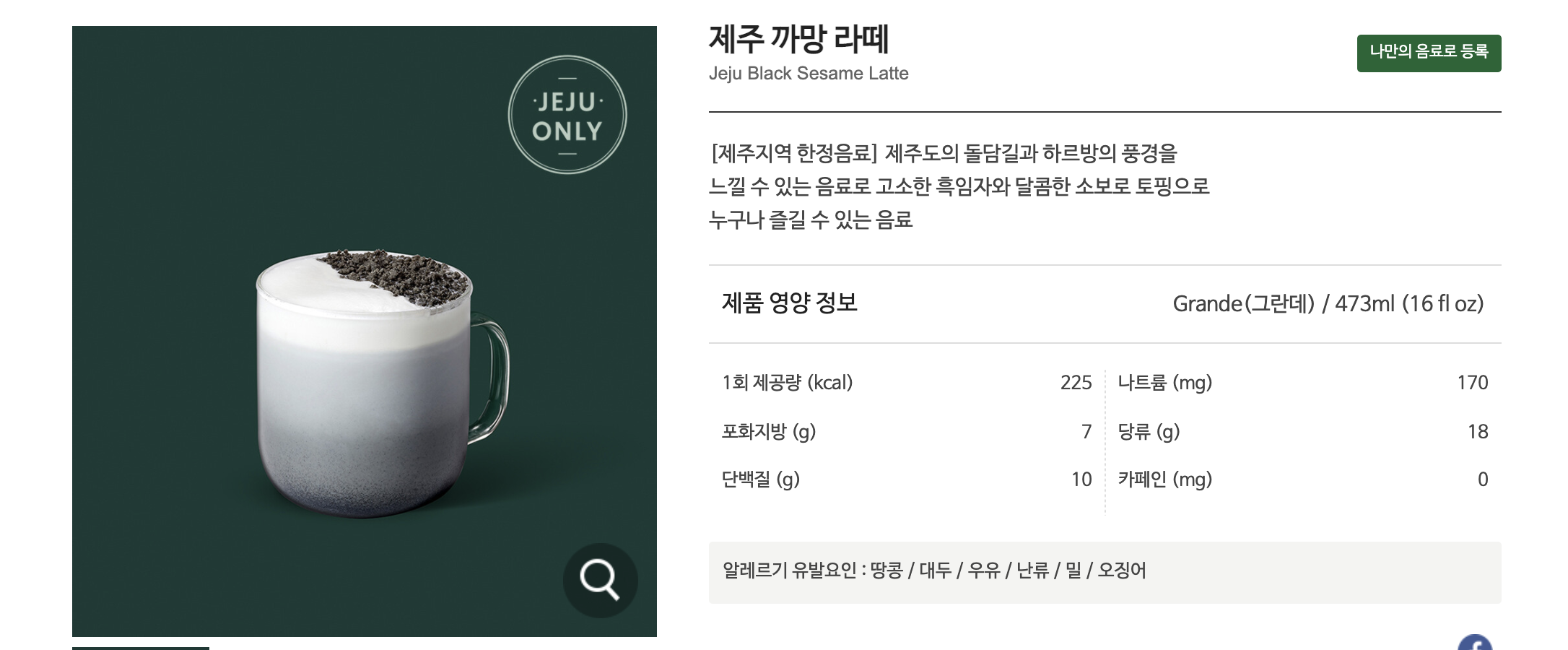
이 음료에는 보시다시피 총 5가지의 알러지 원이 포함되어 있습니다. (오징어 알레르기가 있다는 사실도 첨 알았...)
처음에는 텍스트로 "땅콩 / 대두 / 우유 /난류/밀/ 오징어" 를 한번에 넣을까 생각을 해봤습니다. (allergy : varchar(200)) 이런식으로요.
하지만 이렇게 구성을 하게 되면 한글을 읽는 사람은 어떤 알레르기가 있는지 알지만 컴퓨터는 이 음료에 어떤 알레르기가 있는지 알지 못합니다. 그저 텍스트 한 덩어리로 인식하기 때문이죠. ("우유"와 "우유 / 대두" 는 모두 우유가 포함되어있지만 컴퓨터는 각각 다른 텍스트로 인식)
그래서 각 알레르기 유발원들을 여러개 가지고 있는 경우 해당 알레르기 원을 모두 표시해주고 알레르기가 없는 음료는 1번값으로 채워주는 방식으로 진행을 하기로 했습니다. (+정규화 가능- 제1정규형 한 열에 한 개의 정보 기입)
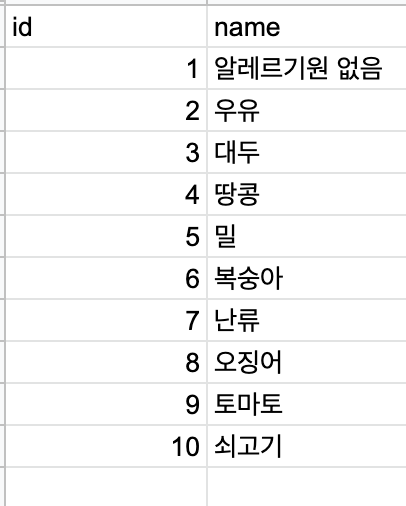
스타벅스의 음료와 음식들을 확인해본 결과 알레르기 원은 다음과 같이 구분이 되었습니다.
이를 원 테이블에 적용을 해보면

제주 까망라떼가 가지고 있는 알레르기 원들의 5개의 id값이 순서대로 들어가고 나머지는 알레르기원 없음으로 채우는 식으로 진행을 하기로 했습니다.
다만 이렇게 했을 때 참조관계를 일일히 해줘야 하기 때문에 보기가 좋지 않습니다. 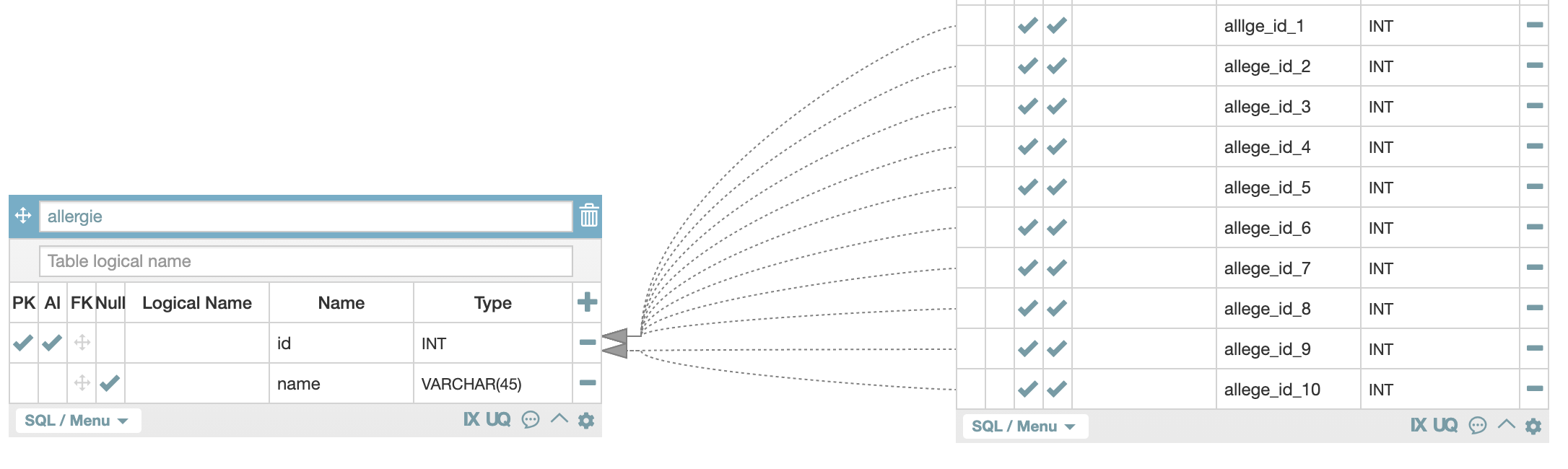
중간에 생각을 했던 것은 오징어 쇠고기 등은 많지 않기 때문에 기타로 묶어서 필드를 줄여보려했습니다.하지만 이렇게하면 행은 줄어들지 모르겠지만 원래의 의도인 알레르기가 있는 분에게 해당 알레르기 있는 정보를 전달하려는 의도가 조금은 흐려지게 됩니다. 그리고 어디까지를 기타에 포함할지에 대해서도 주관적판단이 들어가게 됩니다.
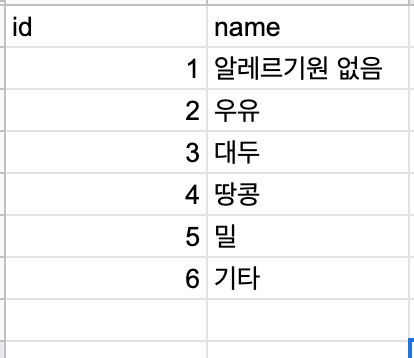
그래서 최종적으로 생각한 것은 해당음료에 어떤 알레르기원이 있는지 먼저 판단을 하는 테이블을 만들고 그 테이블이 알레르기 테이블을 참조하여 구체적으로 알레르기 원을 기록해주는 방식으로 확인을 하는 것이 좋겠다 생각했습니다.
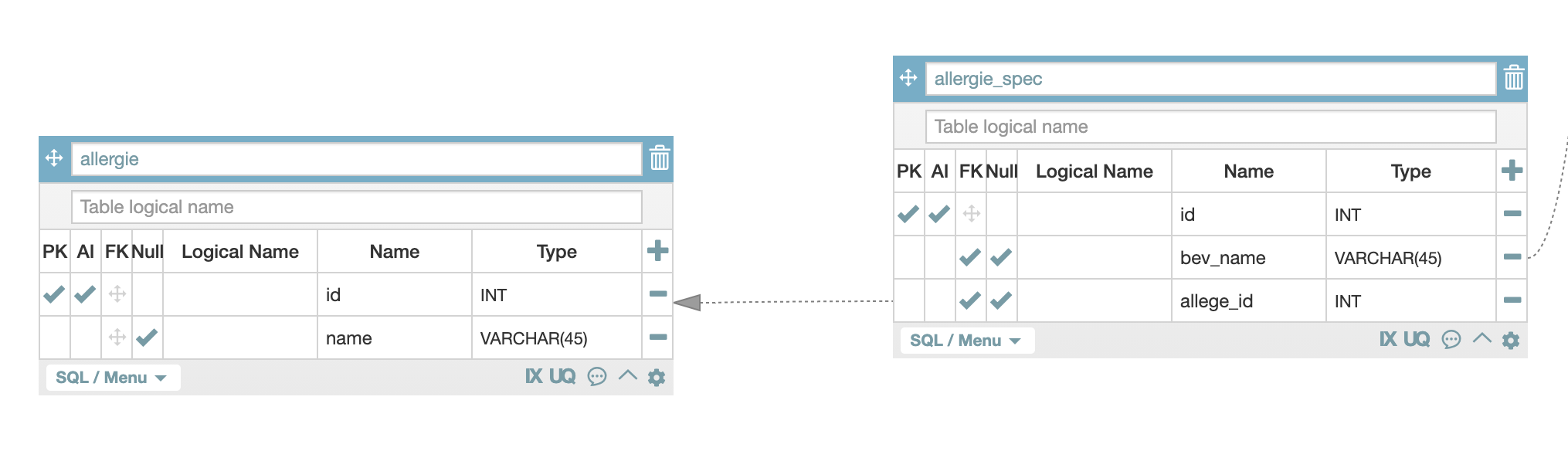
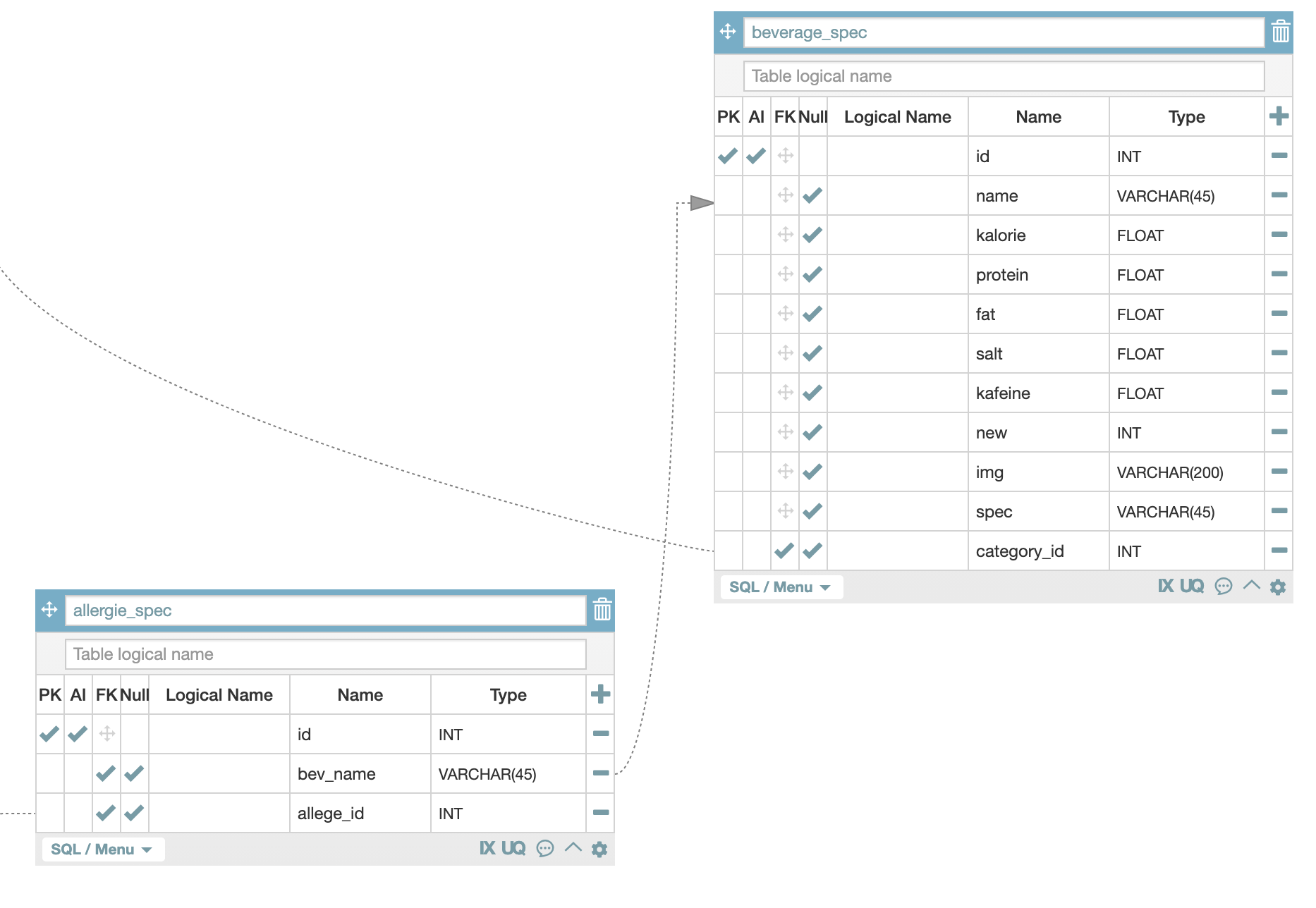
이를 구체적인 값을 넣은 표로 확인을 해보면 다음과 같습니다.

제주 까망라떼를 선택하게 되면 제주 까망라떼의 이름을 가진 행들(bev_name = "제주 까망 라떼")을 조회하게 되고 그 행들의 값은 각 알러지의 id(allege_id)를 allergie 테이블에서 조회해서 해당 id에 해당하는 알러지가 무엇인지 파악합니다.
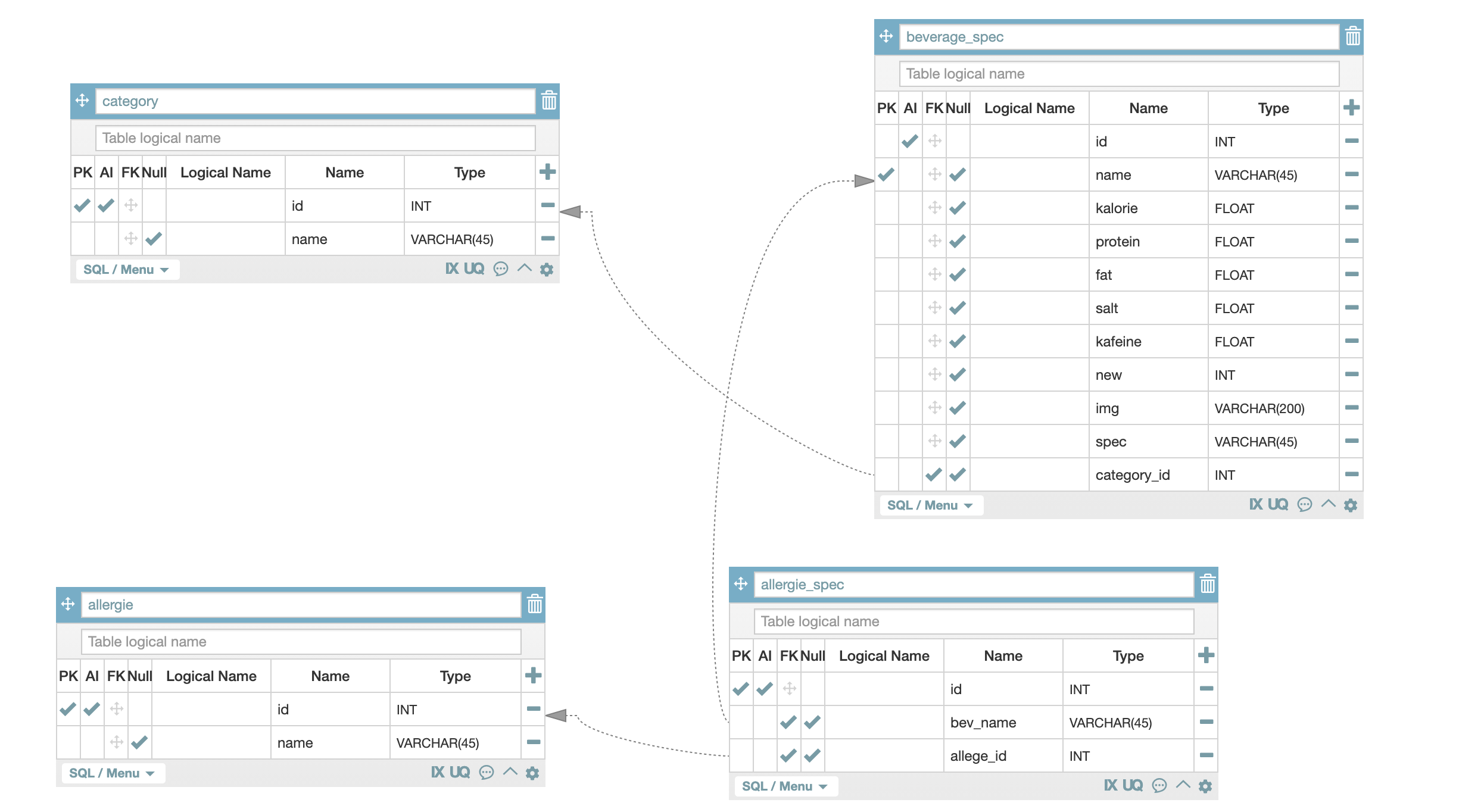
이렇게 구성을 하게 되면 전체적으로 다음과 같은 형태로 구성할 수 있습니다. 최대한 1:다 형태로 구성을 하고자 해서 실제 사용하는 데이터베이스와는 괴리가 클 것 같습니다 ㅠ
<리뷰 후에 반영하면 좋은 내용들>
스타벅스 전체적으로 봤을 때 메뉴 안에 {음료, 푸드, 상품, 카드 }로 구성이 되어있어서 메뉴라는 별도의 테이블을 만들어 주는 것이 좋습니다.
제품명이 한글만 있는 것이 아니라 영어도 있어서 korean_name, english_name을 추가해주는 것이 좋습니다.
이미지가 여러개인 음료가 있습니다.--> 이미지 링크1 ,링크2 이런식으로 필드를 추가해도 되지만 링크가 많아지면 열이 많아지기 때문에 별도로 image 테이블을 구성하는 것이 좋습니다.
테이블을 별도로 구성하거나 합치는 기준?? --> 앞 선 정보중복 + 한 열만 달라진다면 별도의 테이블로 추가해주는 것이 좋다.
.jpeg)