
저번 포스팅에서 적은 것처럼 ORM은 SQL없이도 자료에 접근할 수 있도록 도와준다. 그중에서 테이블을 넘나들면서 자료를 가져오는 것은 필수적이다. (SQL적으로는 join의 기능)
그중에서 M:M 자료를 조회하는 방법에 대해서 정리하고자 한다.
우선 바탕이 되는 테이블의 구조는 Ingredinet와 Recipe가 M:M의 관계로 구성되고 intertable은 ingredientrecipe이다.
.png)
ingredient id가 주어졌을 때 그 ingredient가 쓰이는 요리의 정보를 가져오는 코드를 바탕으로 분석을 하고자한다.
일반적으로 자료를 가져오기
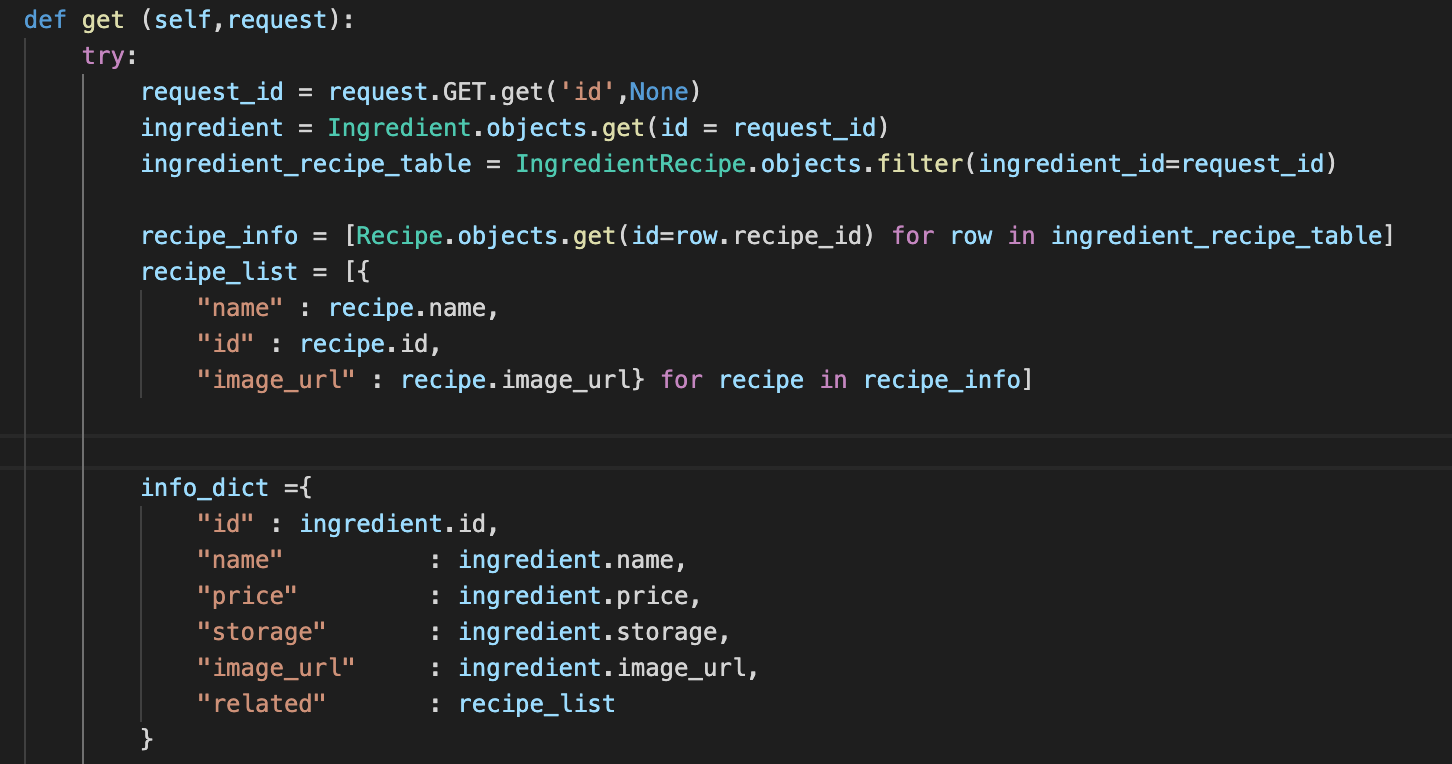
위 코드를 보게 되면 여러단계에 걸쳐서 내가 원하는 정보( ingredient가 쓰이는 요리의 정보)를 가져오는 것을 볼 수 있다. 단계를 정리하면 다음과 같다.
1번째 : parameter로 주어진 ingredient의 id 값을 받아 request_id에 할당한다.
2번째 : ingredient 테이블에서 해당 아이디에 해당하는 ingredient의 객체를 가져온다.
3번째 : 중간테이블인 ingredientrecipe에서 ingredient가 request_id 와 같은 경우만 filter를 이용해서 queryset으로 가져온다.
4번째 : 각각의 쿼리셋의 recipe.id에 해당하는 객체를 Recipe 테이블에서 가져온다.
5번째 : 각 객체에 대해서 필요한 정보만 딕셔너리에 담는다.
6번째 : 최종적으로 ingredient에 대한 정보와 연관된 recipe의 정보를 담은 자료를 json메시지로 전달한다. (스샷에는 제외됌)
일단은 각 단계에서 객체를 가져와서 할당하고 다시 연관된 객체를 가져오는 과정이 여러번 반복되는 것을 볼 수 있다. 이 과정에서 메모리는 메모리대로 연산속도는 연산속도대로 소비가 심한 것을 알 수 있다.
django에서 제공하는 기능 이용하기 -double underscore
장고에서는 m:m자료를 접근할 때 조금 더 쉽게 조회할수 있도록 기능을 제공한다.
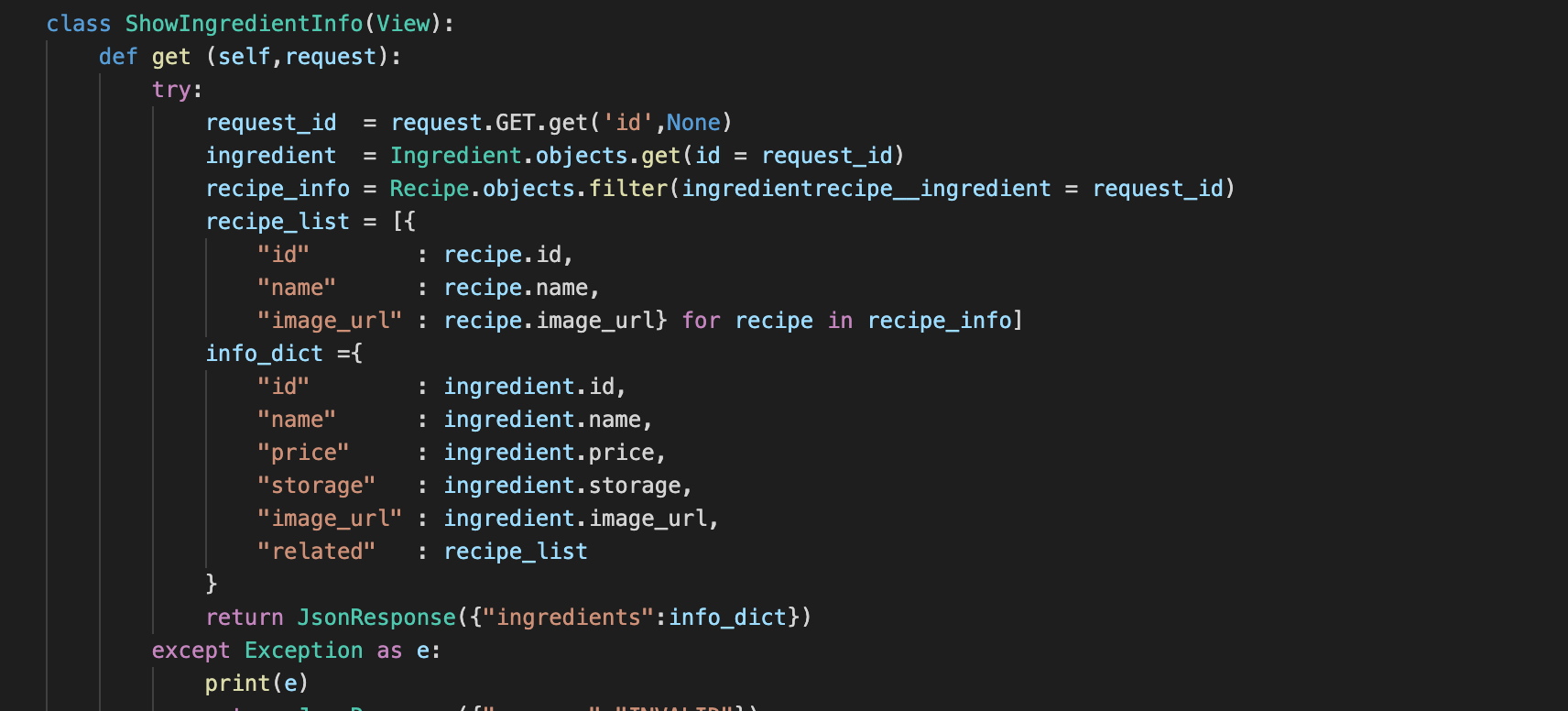
우선 전체적인 코드 구성은 위와 같다. 얼핏보면 비슷한 정도의 코드인 것 같지만 리스트 표현식이 한줄이 사라졌다.

이제 코드를 단순화하게 해준 기능을 살펴보면 위에 나와있는
Recipe.objects.filter(**ingredientrecipe__ ingredient** = request_id) 이 부분이다.
코드를 해석을하면 ingredientrecipe(테이블명)에서 ingredient_id가 request_id와 같은 자료를 찾고 그 객체들을 다시 Recipe 테이블에서 찾아서 queryset으로 반환하는 과정을 거친다.
이 과정을 거치게되면 중간에 id값으로 참조되는 테이블에서 객체를 조회하는 과정이 생략이 되어서 조금 더 효율적이게 자료를 조회해볼 수 있다.
M2. objects.filter ( M1M2__M1 = request_id )
M1 M2가 M:M의 관계를 가지고 있다고 가정하면 M2가 우리가 찾고자 하는 자료가 있는 테이블이고 M1이 우리가 정보를가지고 있는 테이블이다.
이런 방식으로 쉽게 M:M 방식으로 접근을 할 수 있다.
.jpeg)