
스우파가 다끝나고 이제는 스우파 출연하신 분들이 마스터(!!)로 등장하고 있는 스걸파에 빠져살고 있는 와중에 갈수록 나를 빠지게 하는 분이 있었다
그 분은 바로 가비!!! 특유의 뽐의 매력에서 허우적 되고 있는 중이다.
스우파를 중간부터 우연히 보다가 빠져버렸기 때문에 가비에 대해서 부정적인 반응이 있었다는 것은 나중에 알게 되었다. 지금은 모두 가비에 대해서 칭찬인데 과거와 어떻게 달라졌는지 너무 궁금했다. (참을 수 없지!)

그러면 Let's Go~
📎 분석 포인트
-
가비에 대한 평가가 시간이 지날수록긍정적으로 바뀌는 것을 느낌 -시계열 데이터로 확인 -
아이키에 대한 평가는 늘긍정적이었는데 실제 그런지 확인 -
높은
좋아요수를 기록한 댓글 정보 확인
📎 데이터 가져오기
데이터 대상 영상
데이터 대상은 스우파 1회 아이키 vs 가비 배틀영상의 댓글들로 했다. 아무래도 제일 노이즈마케팅이 이루어기도 했기 때문에 좀 더 극명하게 반응 차이가 있을 것 같았다. 자료가 별로 없을 줄 알았는데 50만 조회수가량 되어 댓글도 700개 가량 있었다.

약자 지목 배틀) 끼가 뿜어져 나오는 가비 VS 아이키 배틀에 후끈 달아오른 파이트 존! '이번만큼은 꼭 이길 겁니다'
✚ 추가된 내용
분석을 진행을 해보니 데이터셋의 두가지 문제가 있었다.
댓글이 비디오 업로드 시점에만 집중
아무래도 유튜브가 화제성에 기반을 하다보니 처음 업로드된 날짜 기준으로 댓글들이 몰려있었다. 그래서 날짜별로 균등한 데이터 분포를 보이지 않았다.
편향적인 비디오 편집
이 영상 자체가 아무래도 엠넷(a.k.a 암넷)의 편파적인 편집이 들어가 있다 보니 가비에 대한 부정적인 댓글들이 시간이 지나서도 여전히 많았다. 이 영상을 처음 보고 댓글을 다는 사람들은 아무래도 새로운 가비의 이미지를 알 수 없기 때문에 편향적으로 댓글이 구성되었다고 생각한다.
그래서 한가지 영상을 합해서 분석을 하기로 했다. 아이키와 가비가 스우파 갈라토크쇼에서 합동무대를 한 영상이다. 이 영상을 추가로 고려한 이유는 다음과 같다.

[스우파 갈라토크쇼/2회 선공개] 아이키♡가비, 강렬했던 그때의 첫 만남을 라라랜드 'Another Day Of Sun' 무대로..
조회수와 댓글 수가 비슷
배틀영상
- 조회수 : 55만여회
- 댓글 : 740개
- 업로드 날짜 : 10.02.16
콜라보영상
- 조회수 : 44만회
- 댓글 : 590개
- 업로드 날짜 : 11.16.2021
둘의 자료갯수는 차이가 있지만 다른 영상과 비교해봤을때는 두개의 영상만을 대조한다고 했을때는 제일 자료의 구성이 비슷했다.
실제 전처리를 진행하고 나서의 자료개수는 배틀영상이 55개 정도 많았다.

가비 - 아이키 합동공연
기존의 배틀영상에서는 아무래도 한쪽의 입장을 응원(?)하는 경우의 댓글이 많았다. 합동공연 같은 경우 두 주인공을 긍정하는 경우가 훨씬 많아서 향후 중립을 고려한 점수도 계산을 해보았다.
평판이 바뀐 조금 더 나중 시점
- 두번째 영상 같은 경우 스우파가 끝나고 열린 갈라쇼에 대한 영상이기 때문에 긍정적인 댓글이 조금 더 달렸을 것이라 생각을 했다. 이전 배틀영상에서 부정적이었던 평가가 많이 바뀌었을 것이라 생각했다.
데이터 -> DataFrame 함수 만들기
이부분은 설명할 내용이 많아서 별도의 게시글로 작성을 했다.
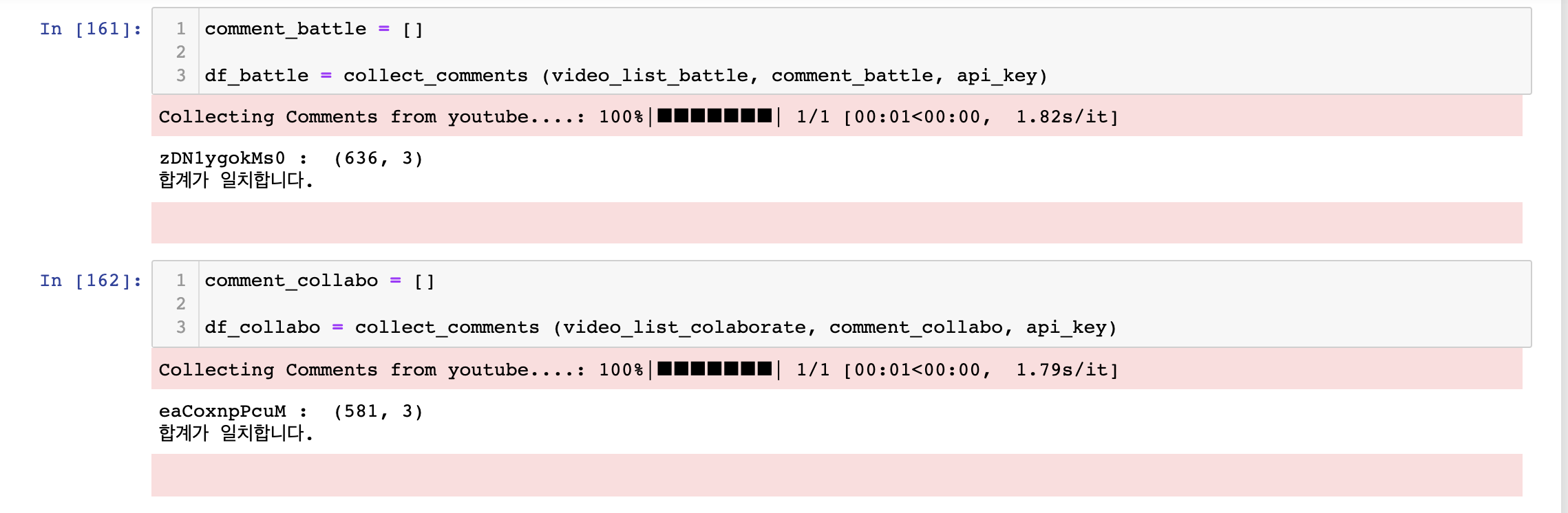
Youtube API를 이용해서 특정 영상의 댓글(comment) 작성날짜(datetime) 좋아요수(like_count)를 가져와서 데이터프레임으로 만들었다.
📎 데이터 전처리
날짜 기준으로 정렬
날짜별로 각 라벨의 갯수를 취합할 것이라서 df.sort_values를 사용해서 정렬을 해주었다. 행에 대해서 정렬을 할 것이기 때문에 axis=0으로 지정했다.
한글 & 숫자만 남기기
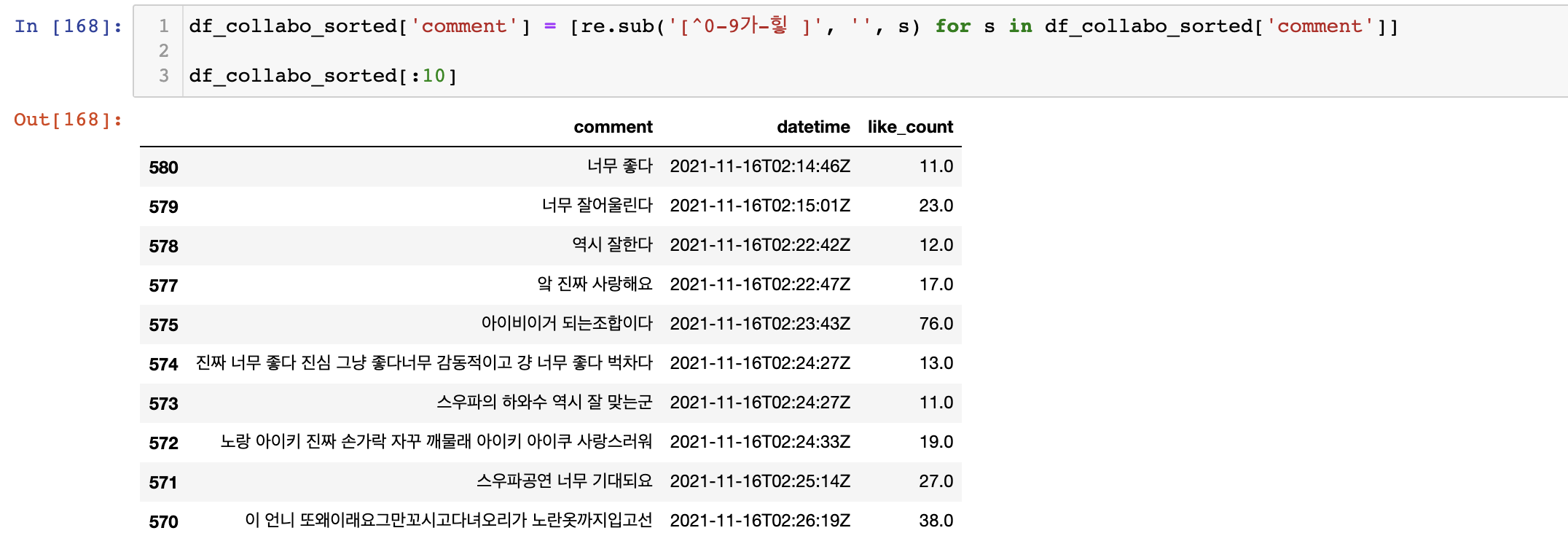
위에 데이터프레임 head자료를 보면 html태그와 링크들이 섞여있는 것을 확인할 수 있다. 이 자료에서 한글과 숫자만 남기고 분석을 하기 위해서 정규표현식(RegEx)을 이용하기로 했다.
각 comment행마다 정규표현식을 적용하고 대체를 해주어야 하기 때문에 루프를 두번 돌아야 한다. 그래서 조금이라도 속도 향상을 위해 리스트 표현식을 사용해서 진행을 했다.
[^0-9가-힣 ] 같은 경우 모든 숫자 + 모든 한글 (단음절 제외 ex. ㅋㅋㅋ, ㅎㅎㅎ) + 공백만을 포함한 자료만 가져온다. 그리고 이것을 re.sub를 통해서 기존 자료에 대체해준다. (re를 사용하려면 파이썬 내장함수를 가져와야 한다- import re )
중복 & null데이터 제거
혹시 모를 중복자료를 없애기 위해서 df.drop_cupicates()를 진행해주었다.
그다음으로 빈값이 존재하는 자료를 없애주기 위해서 df.dropna()를 진행해주었다.
📎 데이터 라벨링
처음 시도 ...
사실 이 프로젝트가 처음이 아니었다. 진행중인 프로젝트는 래퍼 조광일에 대한 평가의 변화를 파악하는 것이었다. 그래서 쇼미더머니 조광일과 관련된 유튜브 댓글을 다 모아서 진행을 하려고 했었다. (진성 엠넷 빠돌이...) 어찌저찌 데이터는 다모았는데 전체데이터가 4만개가 넘어갔다. 이걸 일일이 라벨링을 하려니 쇼미더머니 11을 볼 날이 올 것 같았다. (과장 100% ㅎㅎ) 그래서 여러 방법을 찾아서 적용을 해보았다.
토큰화부터 말썽
적용한 방법 중에 첫번째는 감성사전을 이용해서 해당 단어에 대해서 감성점수를 메기는 것이었다. 찾아본 몇몇 논문에서 방법은 찾았지만 문제에 직면했다. 신조어도 너무 많고 약어도 너무 많았다. 이런 것들에 대해서 토큰화부터 감성사전에 따로 등록하는 과정까지 신경써야 될 것이 너무 많았고 아직은 실력이 부족했다.
그래서 간단한 분석부터 시작하기로 했다. (이 프로젝트는 계속 몰두해서 문제를 해결해서 블로그 올려보도록 해야겠다.)
작은 접근부터
그래서 다음 관심사였던 가비에 대한 평판의 변화가 궁금했다. 이전 분석에서는 너무 데이터가 커지고 자연어분석에만 욕심이 있었다면 이제는 데이터 분석에 집중을 해서 대상 데이터의 갯수를 줄이고 실제 결과를 확인할 수 있는 것부터 시작하기로 했다. 그리고 직접 라벨링을 하기로 했다. 배틀영상과 콜라보영상의 자료를 취합을 해보니 대략 1200행 정도 되었다. 라벨링은 총 2시간 정도 걸린 것 같았다.
기준
가비 : 0? 아이키 : 1?
처음에는 가비와 아이키에 대해서 긍정적인 댓글로만 분류를 하려고 했다. 그렇게 하다보니 여러 데이터가 이 분류에 벗어나는 것을 느꼈다. 대표적으로 심사위원들에 대한 평가나 두 댄서를 모두 칭찬하는 댓글이 그러했다.
그래서 이왕 라벨링 하는 김에 조금 더 다양한 경우를 분석해보고 싶었다.
1 / 2 / 3 / 4/ 5 / 6
1 : 가비 긍정
2 : 가비 부정
3 : 아이키 긍정
4 : 아이키 부정
5 : 중립
6: 가비 & 아이키 관련 X
- 긍정/부정 : 긍/부정의 경우 단어 자체는 큰 의미를 지니고 있지 않지만
해당 영상을 봤으면 판단할 수 있는 부분도 포함하였다. (EX : 터치 마이 바디 최고다 -> 아이키 긍정) - 물론 데이터 학습 측면에서는 별도로 사용자 사전을 등록하지 않았다면 OOV로 빠질 데이터라 별로인 접근인 것 같기는 하다. 실제 데이터가 수가 적고 해당 영상에 대한 도메인지식(?)을 반영할 수 있으면 좋을 것이라 생각해서 포함시켰다. (유사 예 : 뽐- 가비 등)
- 5 -중립 : 아이키 가비 둘에 대해서 긍정/ 긍정& 부정/부정 감정을 동시에 보인 경우 (
EX: 와 둘 다 찢었다)가 포함되었다.
부정/부정이 전체 중립에서 차지하는 비율
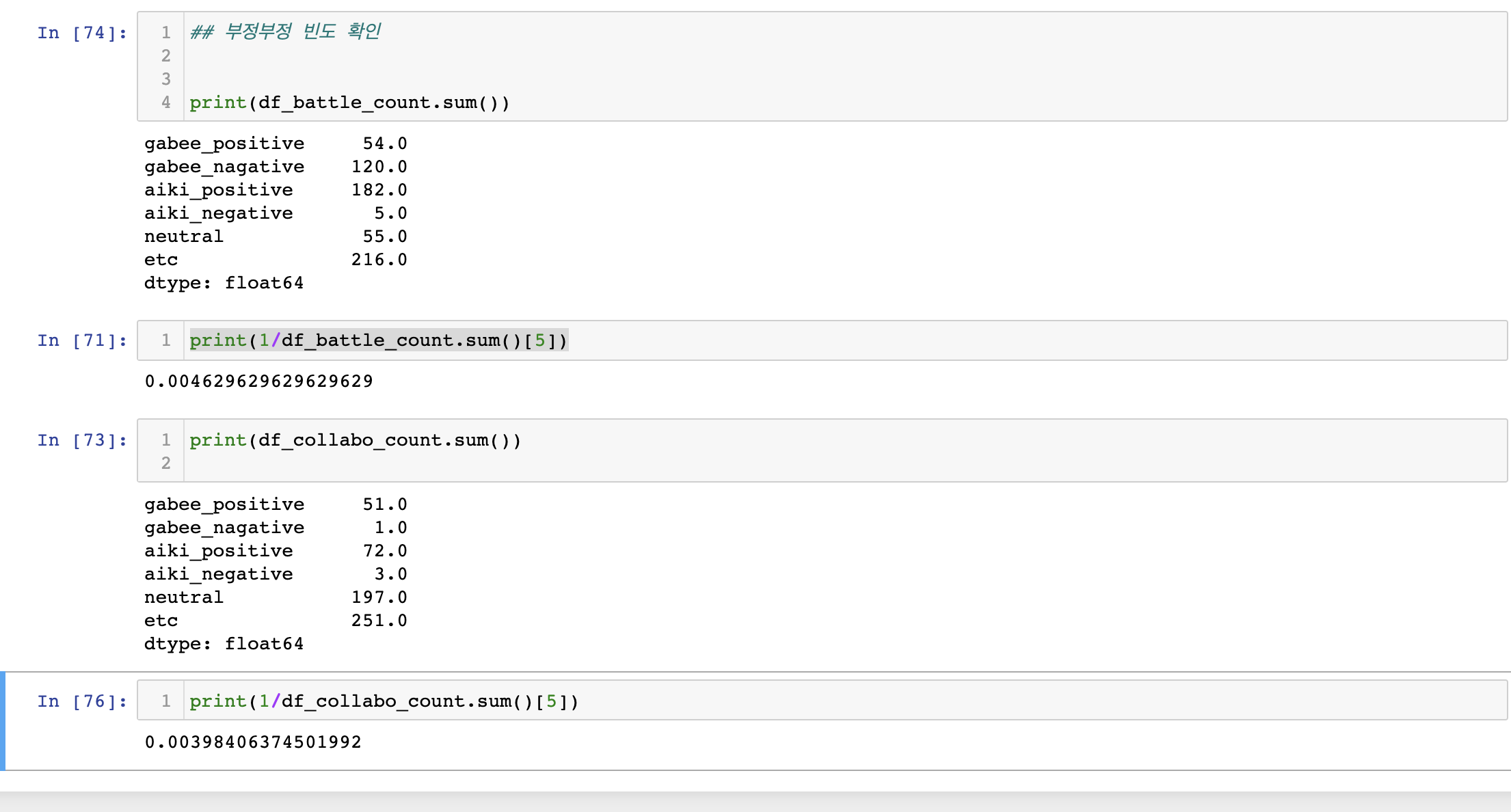 - 전체 데이터에서
- 전체 데이터에서 부정/부정의 경우1개의 자료만 각각 있어서 그 비율이 미비했다. (배틀영상에 경우 0.004, 콜라보영상의 경우 0.0039) 따라서 향후 중립을 긍정/긍정으로 간주해도 그 영향은 미비할 것으로 판단할 수 있다.
- 6- 관계 X : 가비와 아이키에 관계없는 내용
EX: 순위를 메기는 댓글(1빠),엠넷, 심사위원에 관한 내용등
라벨링 과정에서 힘들었던 점 + 애매한 점
- 모호한 입장 : 영상에 주인공이 2명이라서 감성에 대한 경우의수가 4가지(중립까지 고려하면 +a)가 나왔다. 기존에 한상품에 대한리뷰를 이야기할 때는 부정:0 긍정:1 이렇게 표현이 가능하다. 주인공이 여러명인 경우 한 댓글에서도 한명을 긍정하면서 다른 사람을 부정하는 경우가 있었다.
작위적일 수 있지만부정적인 표현이 사용되었다면 해당 대상에 대한부정적인 의견으로 라벨링을 하였다. 단순긍정이 아닌비교의 부정표현은 의도가 있을 것이라 생각했기 떄문이다. 이 부분은 조금 더 자료를 찾아봐야 할 것 같다.
-
대댓글 - 대댓글 구조상
mother댓글의 id값이 댓글에 같이 포함되어서 나왔다. 정규표현식으로 숫자를 제거해도 되지만1일 5반복같은 문장이 의미가 없게되는 경우가 있어서 숫자는 유지하기로 했다. -
타임스탬프 -댓글에 대상에 대한 언급없이 영상나오는 주인공에 대한 이야기라 댓글만 보고 판단할 수 없었다.
주어가 없거나,단순 형용사,감탄사를 나열한 경우는기타: 6번으로 구분했다. -
중립자료 - 중립인 경우 대부분 긍정/긍정인 경우가 대부분이었다. 각 1개의 자료를 별도로 6번으로 뺴는 것이 많을까에 대해서 생각은 한 결과 라벨링은 그대로 두고 결과를 해석함에 있어서
중립을중립 긍정으로 해석해도 차지하는 비율이 미비하기 때문에 큰 무리가 없을 것으로 생각했다.
라벨링을 하며 발견한 추가적인 인사이트
- 첫번째 영상 :
판정결과에 대한 비판(키워드 : 심사, 무승부, 엠넷 , 프로듀서)이 많이 있었다.

전체에서 9퍼센트나 되는 사람들이 판정에 대해서 불만을 가지고 있음을 확인할 수 있었다.
- 두번째 영상 : 두 참가자 외에
다른 참가자에 대한 언급이 있었다 .(노제- 노제, 노제여보 , 허니제이 - 허제,꿀정,허니제이,꿀언니)에 대한 언급이 많았다.- 노제 -
아이키와의 관계성- (질투, 안절부절 등) - 허니제이 -
리액션(파닥파닥)
- 노제 -

전체에서 26퍼센트 정도로 많은 자료를 차지하고 있었다.
📎 일별 라벨 갯수 집계
라벨링 기준으로 집계를 하려고 했는데 집계를 일별, 라벨별로 진행을 해야하니 df.groupby같은 함수로는 제약이 있었다. 검색을 하다보니 resample로 집계를 하면 가능성이 보였고. 그래서 df.resample을 이용하는 별도의 함수를 만들어서 집계를 하였다.
함수 설명 링크 : Datetime 자료 + 범주형 데이터 집계
최종결과는 아래와 같다. 이 데이터를 기반으로 시각화를 진행해서 분석결과를 확인해보려고 한다.
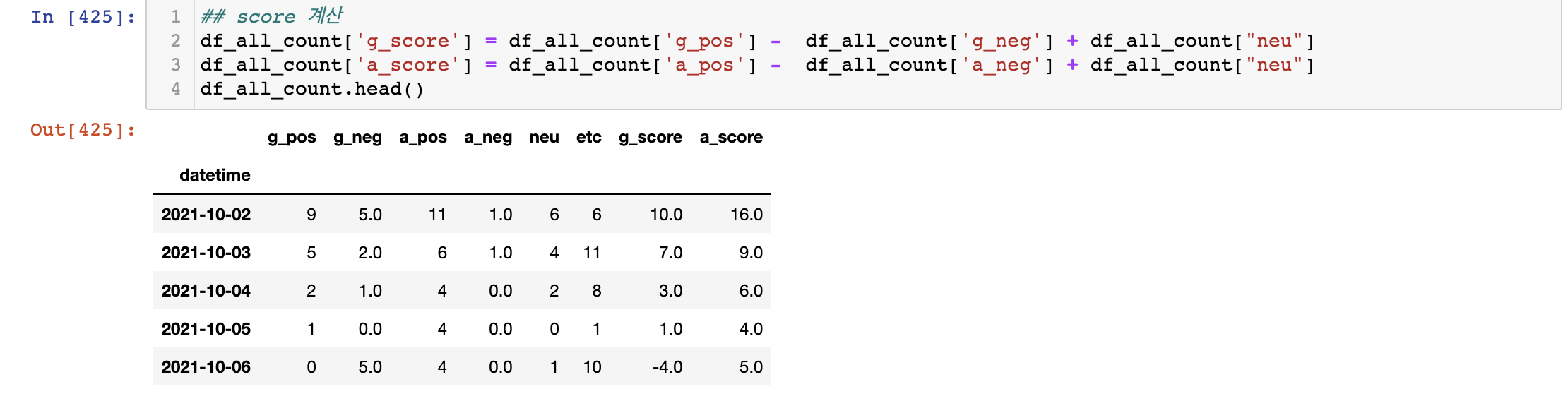
📎 데이터 시각화
데이터 시각화는 matplotlib,seaborn으로 진행을 해보았지만 조금 더 한 눈에 자료를 볼 수있도록 대시보드를 만들고 싶었다. (subplot으로 가능하기는 함) 그래서 tableau를 이용해서 시각화를 진행했다. (태블로가 라벨을 조금 더 쉽게 넣을 수 있다. + 더 이쁨 ......🌝)
time graph
그래프
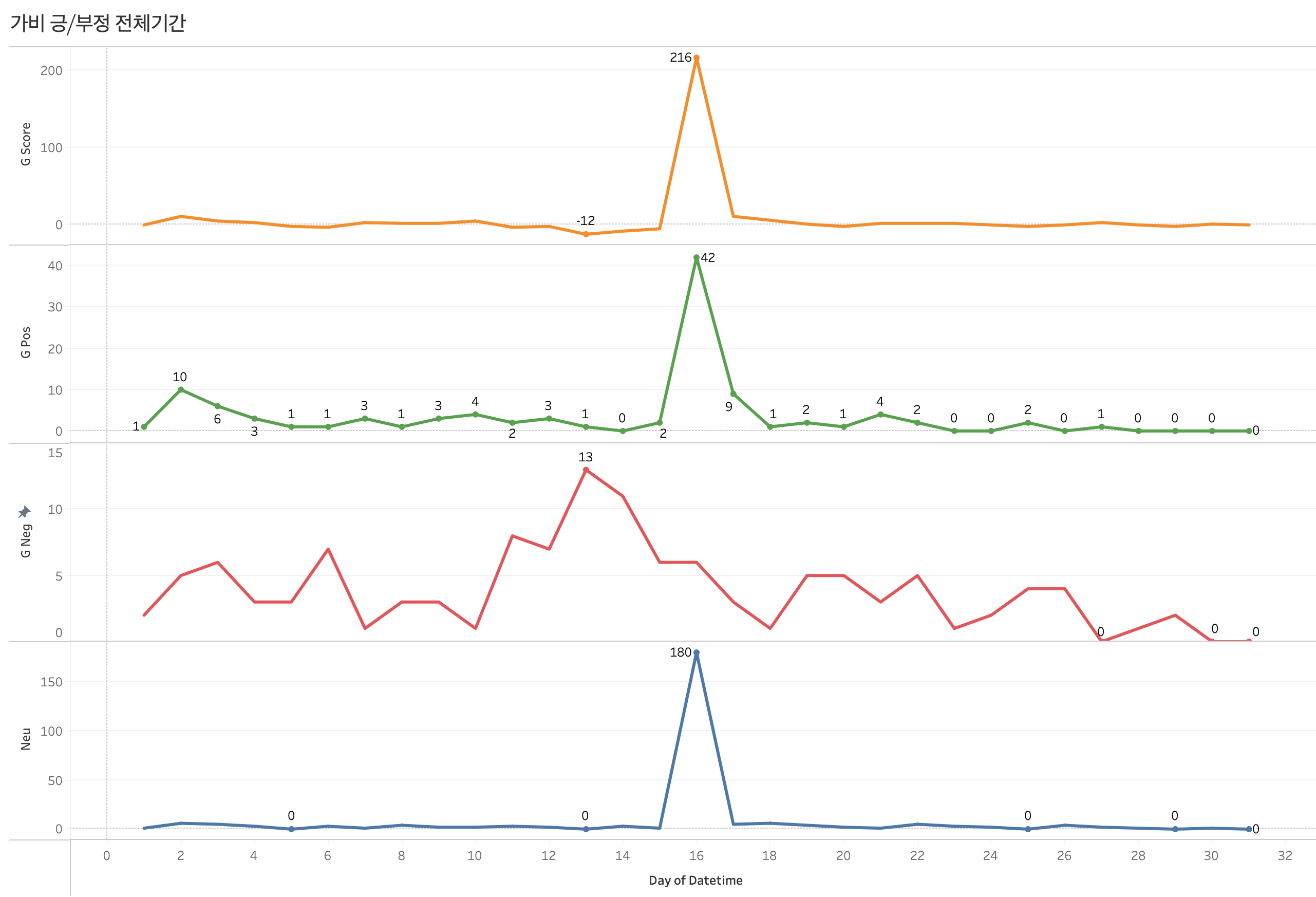
가비(아이키)와 관련된 자료 그래프는 총 4가지로 구성이 된다.
G_score = g_pos - g_neg + g_neu
가비 긍정 반응 - 가비 부정반응 + 가비 중립반응 (중립긍정이 압도적으로 많기 때문에)
G_pos
가비에 대한 긍정 반응을 집계한 그래프
G_neg
가비에 대한 긍정 반응을 집계한 그래프
Neu
가비에 대한 중립 (중립 긍정)을 집계한 그래프
배틀영상 같은 경우 각 댄서들에 대한 반응을 표현하는 댓글이 많았다. 콜라보 영상 같은 경우에는 각각 댄서에 대한 칭찬보다는 둘의 합동공연을 칭찬하는 댓글이 훨씬 많았었다.
분석결과
유튜브 업로드 시점이란 변수
댓글이라는 자료의 특성상 대부분 영상이 업로드된 시점에 집중되어 자료가 생성되는 경향이 있다. 향후 지속적인 댓글이 생성되지 않아서 시간변화만으로 긍/부정을 판단하기에 부족한 시계열 자료가 되어버린다.
콜라보 영상에 중립자료 이상치
언급한 것처럼 콜라보영상같은 경우 중립 긍정의 자료가 많다보니중립자료가 영상이 올라온 시점(2021-11-16)에 많은 수가 몰렸있음을 알 수 있다. 그렇다보니 축 scale이 그에 맞춰서 바뀌게 되고 다른 자료들은 0에 수렴하는 것처럼 보이는 결과를 보이게 되었다.
그래서 이 날 해당하는 수치를 이상치로 간주해서 제거한 후에 그래프를 다시 그려보았다.
✚ 이상치 제거 수정 그래프
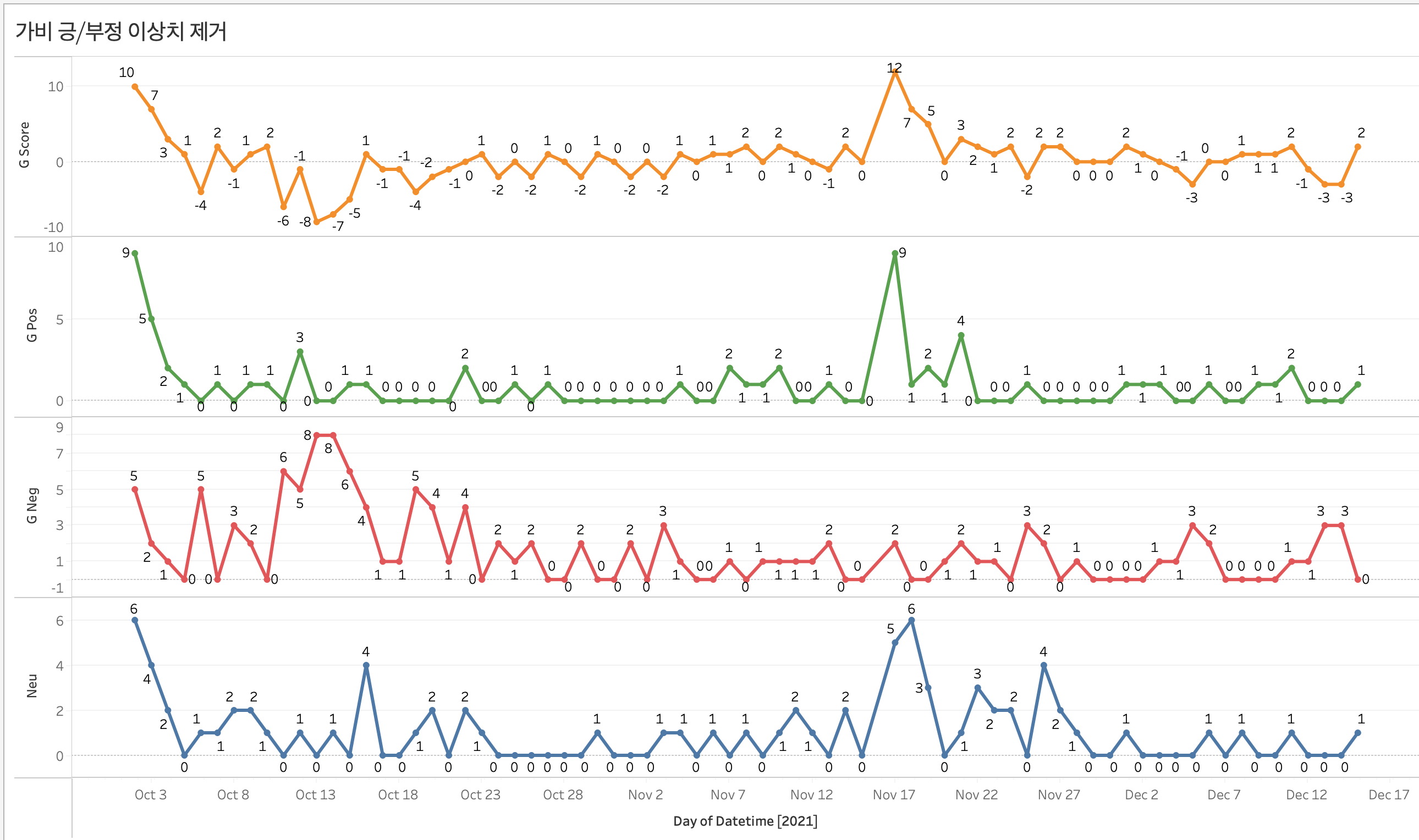
가비 - 긍정/ 부정의 변화
그래프를 통해 확인을 해보니 처음부터 가비에 대해서 부정적인 반응은 아니었다. 처음 10/03일 부근에는 점수가 10점가까이 되었는데 이후 10/09일을 기점으로 부정적인 반응이 나오더니 점수가 -8점까지 떨어지게 되었다. 이후 부정적인 반응이 줄어들다가. 11/16,17일 기점으로 긍정과 중립 반응이 크게 늘어났다. 그에 반해서 부정반응은 크게 늘어나지 않아 양의 점수를 대부분 유지했다.
아이키 - 긍정 반응 연속
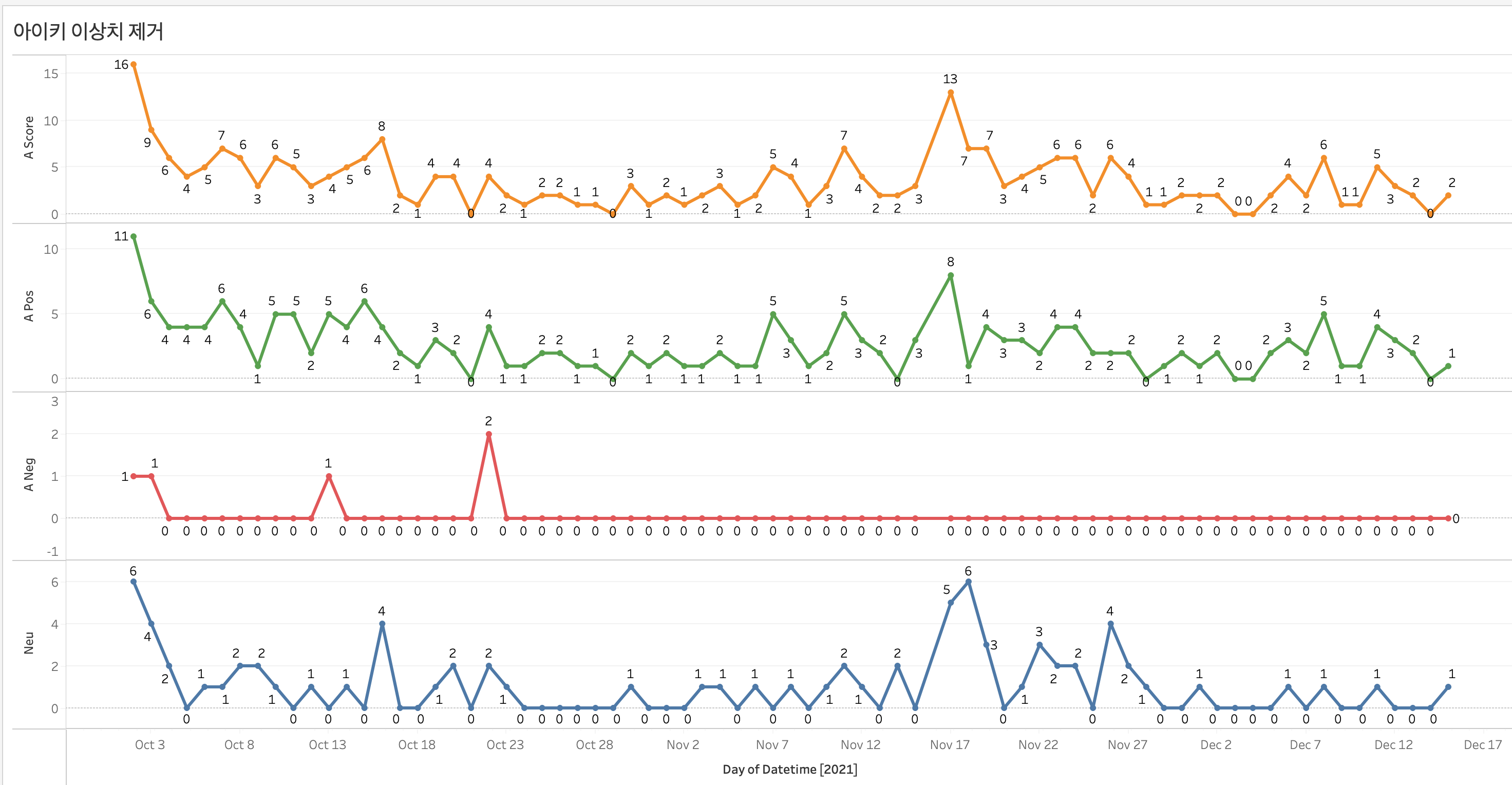
아이키 같은 경우 측정기간 전체적으로 양의 점수를 보였다. 특히 부정반응 같은 경우 특정 날짜를 제외하면 자료가 없을 정도로 부정적인 평가가 적었다. ( 콜라보 영상에서는 부정적인 반응이 없었다 ㄷㄷ.....)
자료를 통해서 확인을 해보니 아이키의 평판이 확실히 긍정적인 것을 확인할 수 있었다.
Best Comment
목표
유튜브를 보다보면 좋아요 순으로 댓글이 놓인 것 같은면서도 아닌 경우가 많다. 그래서 좋아요를 많이 받은 댓글은 무엇인지 상위 10개를 표시할 수 있다면 좋을 것 같았다. 그리고 그 상위 10개 댓글이 어떻게 분포되는지도 확인해보고 싶었다.
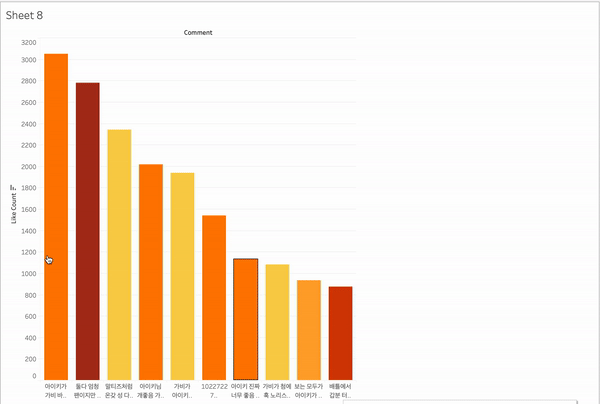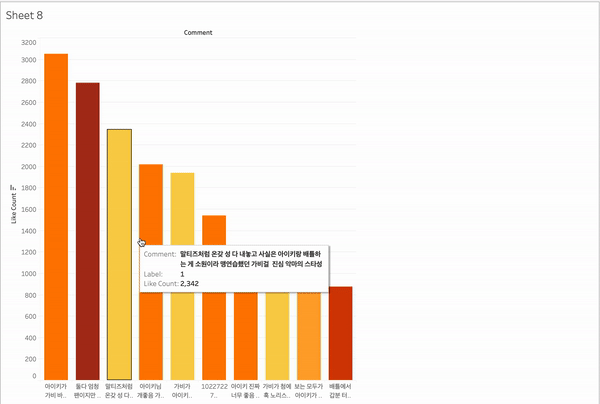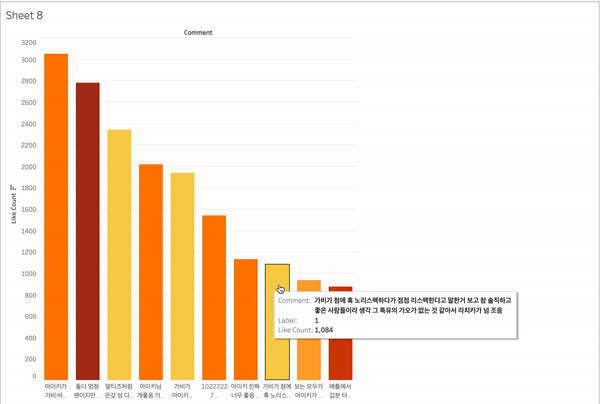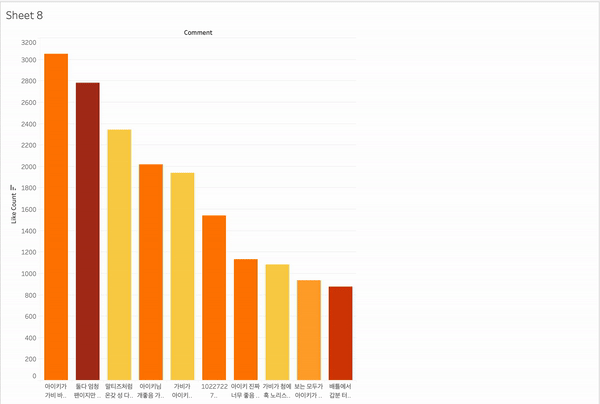
대시보드에 상위 10개 노출
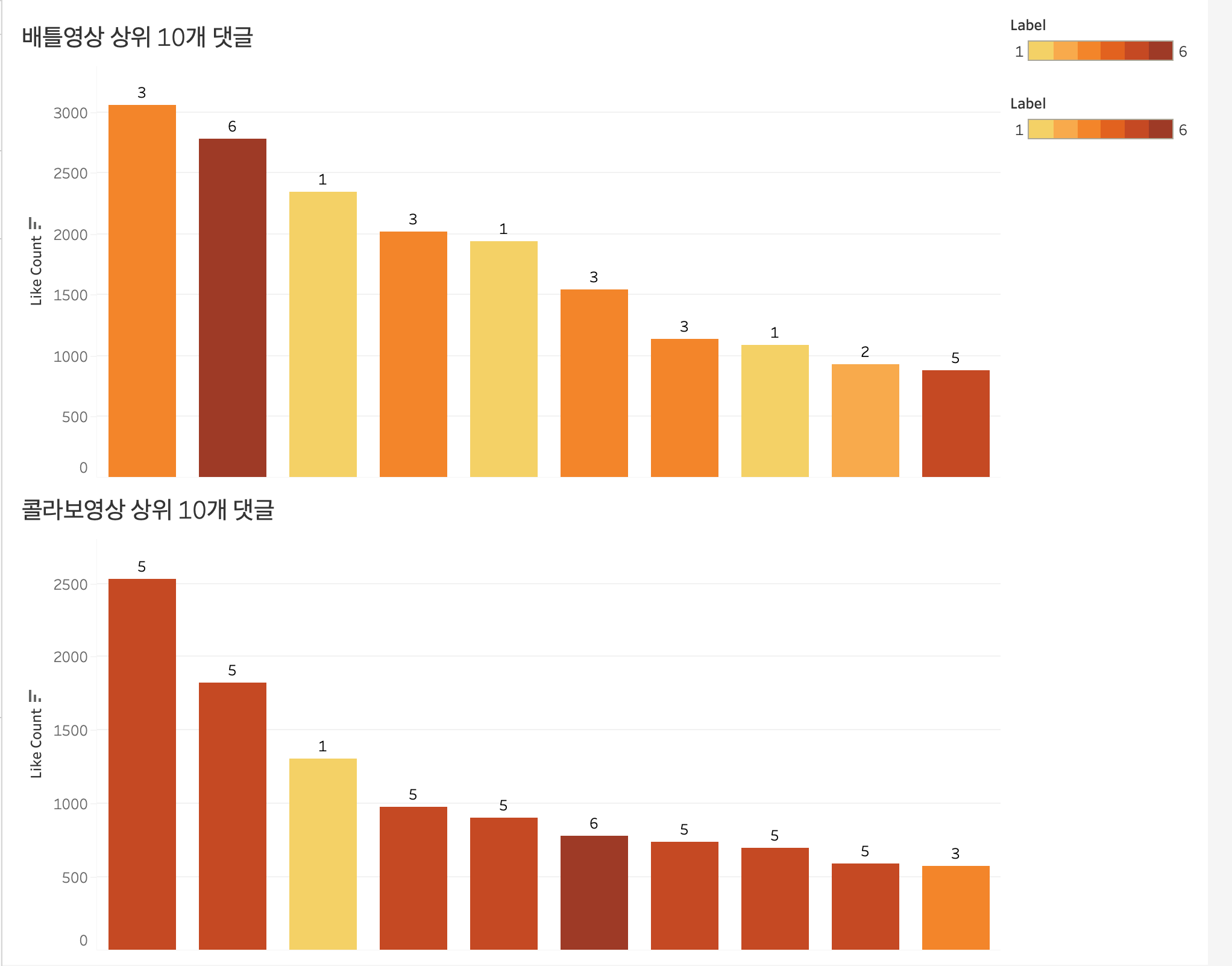
각 영상에서 상위 10개의 댓글을 라벨링 + 색깔 표시를 해서 표시해 보았다.
자세한 시각화 과정은 이 게시글에 정리를 해놓았다.
분석결과
배틀영상
- 가비 긍정 (1) : 3/10 30%
- 가비 부정 (2) : 1/10 10%
- 아이키 긍정 (3) : 4/10 40%
- 아이키 부정(4) : 0 0%
- 중립 긍정 (5) : 1/10 10%
- 기타 (6) ㅣ 1/10 10%
콜라보영상
- 가비 긍정 (1) : 1/10 30%
- 가비 부정 (2) : 0 10%
- 아이키 긍정 (3) : 1/10 40%
- 아이키 부정(4) : 0 0%
- 중립 긍정 (5) : 7/10 10%
- 기타 (6) ㅣ 1/10 10%
배틀영상에서는 각 댄서에 대한 선호도를 각각 표시했던 댓글이 좋아요 수를 많이 받았던 반면 콜라보영상에서는 두 댄서에 대해서 모두 긍정적으로 표시한 댓글이 좋아요를 많이 받았다는 것을 확인할 수 있다.
또하나 놀라운 점은 배틀영상에서 가비에 대한 부정적인 댓글이 많고 그런 댓글이 좋아요를 많이 받았을 줄 알았는데 외외로 가비를 긍정하는 댓글이 상위 댓글 중에 30%나 차지했다. 역시 데이터를 뽑아보기 전에는 모른다는 것을 한 번 더 느끼게 되었다.
💫 느낀점
데이터 ETL >>>>> 데이터 분석
흔히 말하는 Garbage In , Garbage Out 이 되지 않으려면 데이터를 잘 추출하고(Extract), 변환하고( Transfrom), 적재하는 (Load)하는 과정이 정말 중요하다는 것을 알게 되었다. 데이터 소스를 정확히 선정하고 전처리를 잘하는 것이 데이터 분석에서 자의적인 해석의 비중이 줄어들 수 있는 방법인 것 같다.(이번 분석은 자의적인 해석이 조금 많은 것 같다는 자기반성...... )
자연어의 모호성
라벨링을 하다보니 확실히 일반적인 범주형 데이터처럼 딱딱 떨어지는 숫자가 아니다보니 정확히 라벨링을 딱 하기가 애매한 경우가 많았다. 그래서 도메인(영상 및 프로그램에 대한 지식)지식으로 판단을 한 경우도 있었다. 실제 기업 서비스의 라벨링을 진행해본 적은 없기 때문에 라벨링이 어떻게 진행되는지 궁금해졌다.
데이터 파이프라인의 중요성
유튜브 API, 주피터 노트북, 타블로를 왔다갔다하면서 작업을 하면서 엑셀 파일로만 왔다갔다 했는데 그 과정에서 수정을 할 때마다 엑셀 자료의 갯수가 많이 나왔던 것 같다. 이름이 많아지다보니 다른 엑셀 파일을 임포트해오는 경우도 있었고 몇몇 자료에서 수정이 필요할 떄는 데이터 원본을 찾아가 수정하고 다시 엑셀 자료를 최신화하기도 했다. 이래서 데이터를 추출하고 데이터베이스에 적재하고 그 자료를 바탕으로 작업을 진행하는 파이프라인을 만드는 게 중요하다 느낄 수 있었다. 이번 작업한 자료는 많지 않으니 수작업을 할 수 있었지만 하루에도 수많은 자료가 쌓이는 서비스의 자료라면 휴먼에러를 줄이기 위해서라도 확실히 자동화가 필요한 것 같다고 느꼈다.
한 사이클을 혼자 해본 분석
실제 엄청 거대한 자료를 바탕으로 한 분석은 아니었지만 실제 데이터를 직접 구하고 전처리하고 결과까지 만들어보는 과정이 너무 재미있었다. 내가 느낀 바를 단순히 그런가보다하고 끝내는 게 아니라 데이터적으로 맞지 않았을 때는 왜 안맞는지에 대해서, 일치한다면 왜 일치하는지에 대해서 확인할 수 있어서 작업을 하면서 계속 여러 고민을 할 수 있었던 것 같다.
가비콥터와 함께 날아가며 마무리!! (재밌었따!!!)

자세한 코드는 제 깃헙 레포지토리에 있습니다.
.jpeg)