
Google I/O Extended Conference Incheon 4개 세미나 후기
1. Google I/O Conference

8월 26일 Google I/O Conference 에 참가했다.
매진이 빠르게 나 구매에 실패했었는데,
운이 좋게 같은 팀에게 티켓을 양도 받아 인천 으로 향하게 되었다. 따봉 동규야 고마워
원래 컨퍼런스는 꼭 누군가와 같이 가는데 이 날은 가는 사람을 못찾았다.
최근에 다리도 다쳤기에 다리를 절며 2시간 거리를 혼자 갔다.
이것이 열정..?^^..


Backend 트랙을 듣고 싶었고, 이후 Mind23 컨퍼런스 참가 준비를 위해 4개를 들었다.
Deadlock과Redis대기열 사용하기- 레거시에서 살아남기 with Feature Toggles
- 모듈러 모놀리스 살펴보기
다른 트랙과 세미나에 대한 후기는 없거나 정리하지 못해서 다른 트랙을 원하시는 분을 뒤로가기를 해주셔도 된다.
2. DeadLock과 Redis 대기열 사용하기
Redis 를 사용한 Lock을 사용해 동시성을 해결하는 방법에 관해 얘기 하셨던걸로 기억한다.
아직 redis에 대한 지식은 적어,
모든 내용을 흡수하지는 못했지만 처음에는 Skip List와 Zip List에 대해 언급하셨다.
각 키워드에 대해 내가 찾아본 부분들은 링크로 달아놓겠다.
Skip ListVsZip List
Skip List 와 Zip List는 무엇일까??
두가지의 차이점에 대해 언급하셨었는데,
개발이란 무릇 그러하듯 정답은 없고
Zip List: 메모리를 적게 사용하는 것이 가능Skip List: 위에 비교하여 특히 데이터가 증가할수록 속도 측면에서 우세하다
위 두가지의 장점을 보고 판단하여 알맞게 사용하라고 하셨다.
2-1. 관리 측면에서의 Lock
이후 DeadLock을 해결하기 위해
Spin Lock과 Distribution Lock 의 사용하신 모습을 보여주셨던 것으로 기억한다.
DeadLock?
교착 상태 라는 뜻으로,
한정된 자원을 여러 곳에서 사용하려고 할때, 프로세스가 자원을 얻지 못해
무한정 기다리며 다음 처리를 못하고 있는 상태를 의미 한다.
당시 왜 낙관적 Lock과 비관적 Lock이 아닌,
Spin Lock과 Distribution Lock을 사용하신 이유에 대해서 다른 분이 여쭤봤던 걸로 기억하는데,
찾아보니 낙관적 Lock과 비관적 Lock은
문제 발생시 rollback이나 사용하고 있을 것이라 예상하고 Lock 을 걸어놓는 등,
동시성 문제를 데이터베이스 자체에서 접근을 막는 것으로 해결하는 느낌 이었다면
Spin Lock과 같은 경우는 데이터베이스 접근 자체를 연결과정에서 기다리는 느낌이었다
연사해주신 분은 Redission을 사용한 Distribution Lock의 경우 timeOut을 설정할 수 있기에, 찾아보니 Lettuce는 안되는 듯함
동시성 관리가 가능하다고 여겨 사용하신 것 같았다.
여러모로 내 서비스에서 동시성 문제가 일어날 경우에 대해
고민할 수 있게된 시간이었다.
3. 레거시에서 살아남기 With Feature Toggles
레거시?
Legacy라는 용어로,
수정, 보완이 어렵거나 코드의 가독성이 떨어지거나 결합도가 높은 경우 등
사용하기 힘든 코드 를 레거시 코드 라고 부릅니다.Feature Toggles?
코드를 변경하지 않더라도 특정 기능을 On/Off 한다던지 등의
시스템 동작을 변경 혹은 제어 할 수 있는 것 입니다.
첫 시작은 Redis와 Memcached를 비교하면서 시작하셨다.
사실 Memcached는 처음 들어봐서 찾아봤다.

3-1. Redis Vs Memcached
Memcached도 Redis와 같이
Key - Value로 저장되는 저장소로 Ram에 데이터를 저장한다는 점에서 공통점을 가지고 있는데
다만, Memcached는 멀티쓰레드로 String만을 지원하고,
Redis는 단일쓰레드로 String, Set, Hash 같이 다양한 데이터 타입을 지원한다는 점에
차이점이 발생하는 것 같다.
| Redis | Memcached | |
|---|---|---|
| 저장 방식 | Key - Value | Key - Value |
| 데이터 Type | String, set, Hash, List, String | String |
| 저장 | Memory, Disk | Memory |
| 스레드 | Single Thread | MultiThread |
이후 Redis Persistence을 언급하셨다.
이 틈을 타 Redis의 영속성에 관해 찾아보니 RDB와 AOF 두가지 방식이 있었다.
두가지 중 무엇이 더 좋은가? 라는 질문은 앞서 말했듯이 의미가 없고
RDB
- 주기적으로 .rdb 라는 Snapshot을 파일의 형태로 저장
- 사이즈가 작아 읽는데 걸리는 시간이 짧으나, 추출에 속도가 걸림.
AOF (Append Only File)
- 명령어 자체를 모두 저장
- 현재 시점을 기준으로 저장 가능, 파일이 크고 재시작 속도가 느림
이후 두가지 Redis 아키텍처를 소개해주셨다.
3-2. Redis Cluster Vs Redis Sentinel
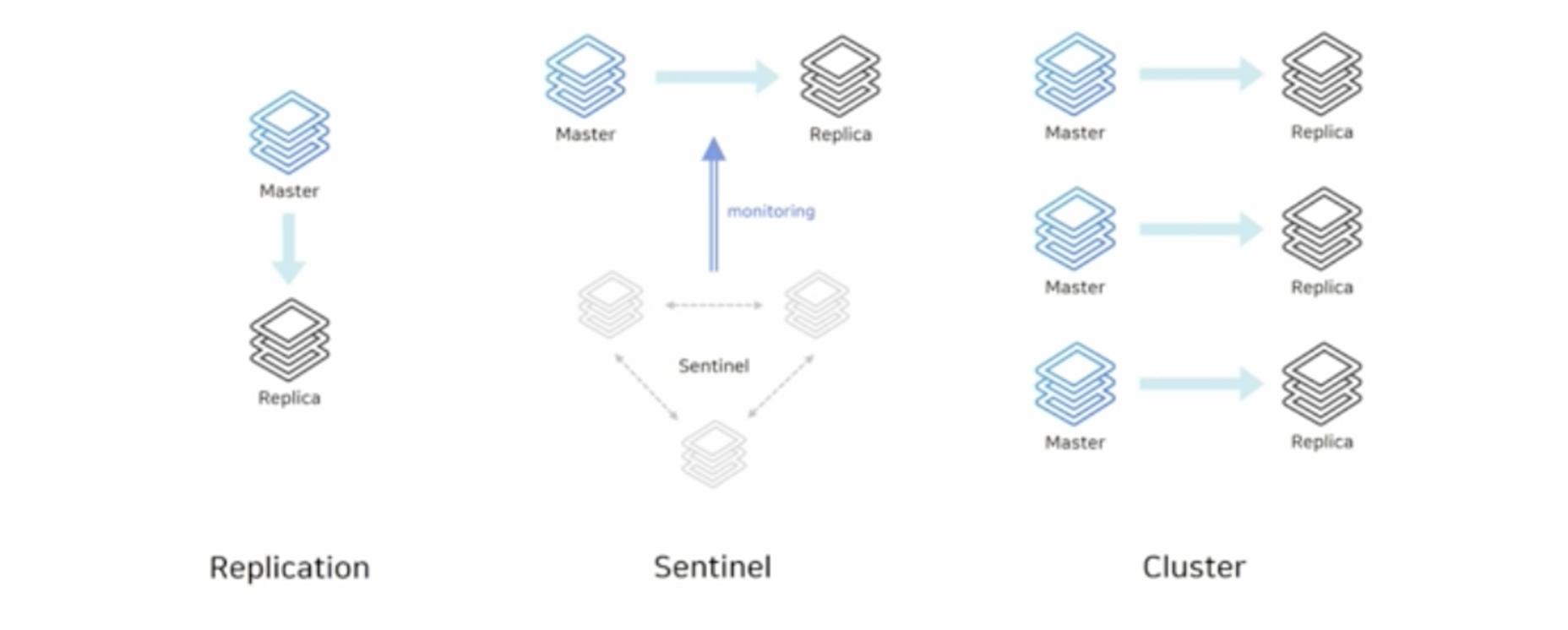
우선 Master와 Slave가 있다면,
공식문서에는
This is the full list of Sentinel capabilities at a macroscopic level (i.e. the big picture):
- Monitoring. Sentinel constantly checks if your master and replica instances are working as expected.
- Notification. Sentinel can notify the system administrator, or other computer programs, via an API, that something is wrong with one of the monitored Redis instances.
- Automatic failover. If a master is not working as expected, Sentinel can start a failover process where a replica is promoted to master, the other additional replicas are reconfigured to use the new master, and the applications using the Redis server are informed about the new address to use when connecting.
- Configuration provider. Sentinel acts as a source of authority for clients service discovery: clients connect to Sentinels in order to ask for the address of the current Redis master responsible for a given service. If a failover occurs, Sentinels will report the new address.
Redis Sentinel은 노드가 다른 노드를 모니터링하며, Master가 다운되었을 경우 자동으로
Sentinel이 이를 파악해 남은 Slave중 투표를 통해 Master을 선출한다고 하셨다.
이부분이 정말 신기한데, 찾아보니 노드끼리 협의하는 알고리즘이 들어가있는 것 같았다.
선출하는 과정까지 설명되어있지만,
나에게는 아직 너무 이른것 같아 넘겼다. Redis를 실습하면서 연구해볼 예정..
Redis Cluster는
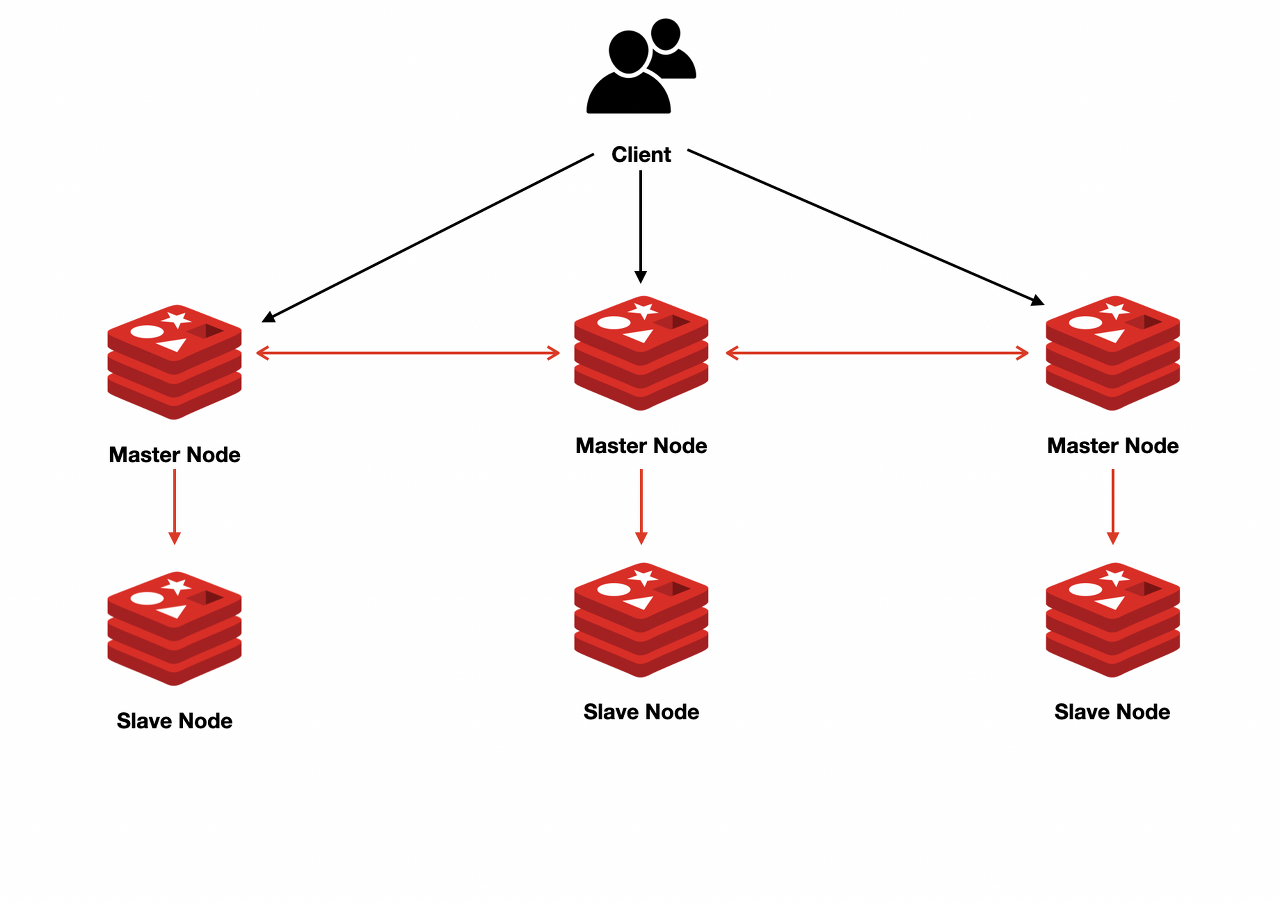
이와 같이, 여러개의 Master을 가지는 모습으로 보여졌고
이 점에서 Data sharding 이라는 기능을 지원해 대용량 트래픽을 분산할 수 있다는 장점을 가지고 있는 것으로 보였다.
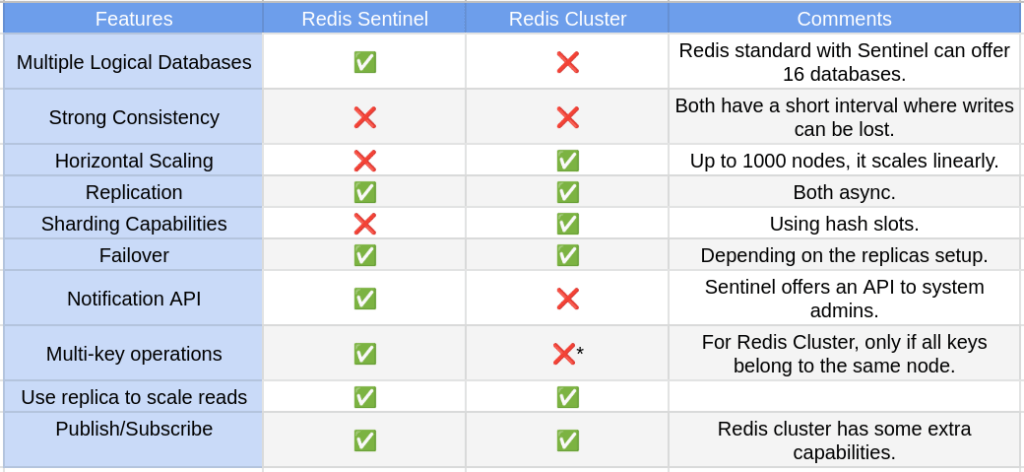
어떻게 사용해야 할까?
언급도 해주셨지만 보통 위와 같은 장점들로
Sentinel은 소규모 서비스에서,
Cluster는 사용이 오버엔지니어링이 되지 않을 정도로의 대규모 서비스에서 사용을 추천하는 것 같았다.
이후 Redis의 Ping Pong을 언급하시면서

이 아키텍처의 모습을 봤을때 이 사진이 떠오른다며 언급하셨는데
무슨 말씀을 하시는지 알것 같아 재미있었다.
4. 모듈러 모놀리스 살펴보기
이 날 흥미롭게 들은 주제가 2개 정도 있었는데,
블로그에는 많이 정리 못했지만 아키텍처를 좋아해서 그 중 가장 집중해서 들은 주제였다.
우아한 모노리스를 통해서
Moduler Monolithic 아키텍처에 대해 관심을 가지게 되었다고 하셨다.
다음에 정리해봐야지
4-1. Monolithic?
Moduler를 언급하기 전에 우선 Monolithic에 대해 얘기해보자.
보통 Monolithic과 Micro Service를 비교하는데,
Microservie Architecture
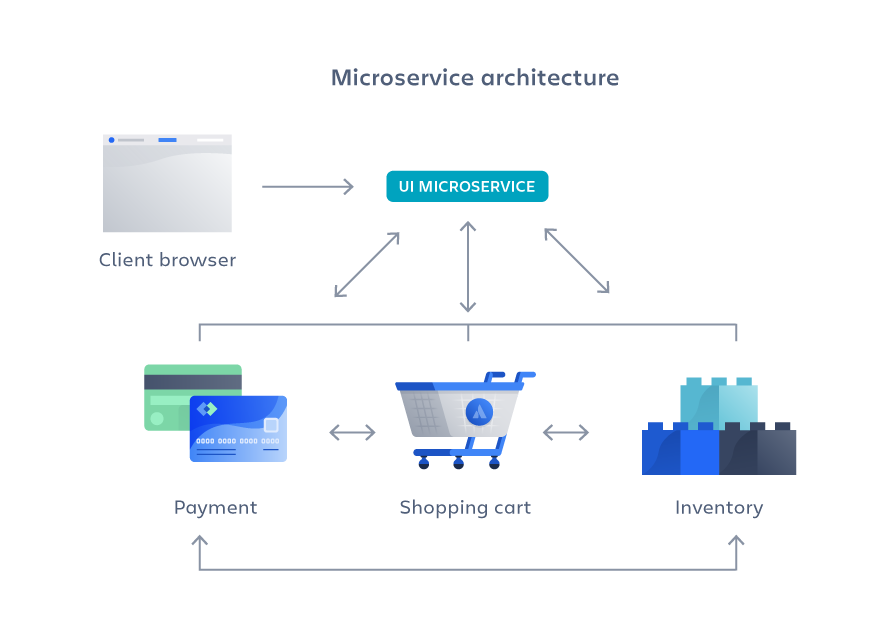
만약 물건을 사고, 판매하는 Application을 만든다면
결제, 쇼핑카트, 물건과 같이 기능별로 분리하여 변경과 조합이 가능하면서 다른 서비스에 영향을 주지 않는다는 장점을 가지고 있습니다.
Monolithic
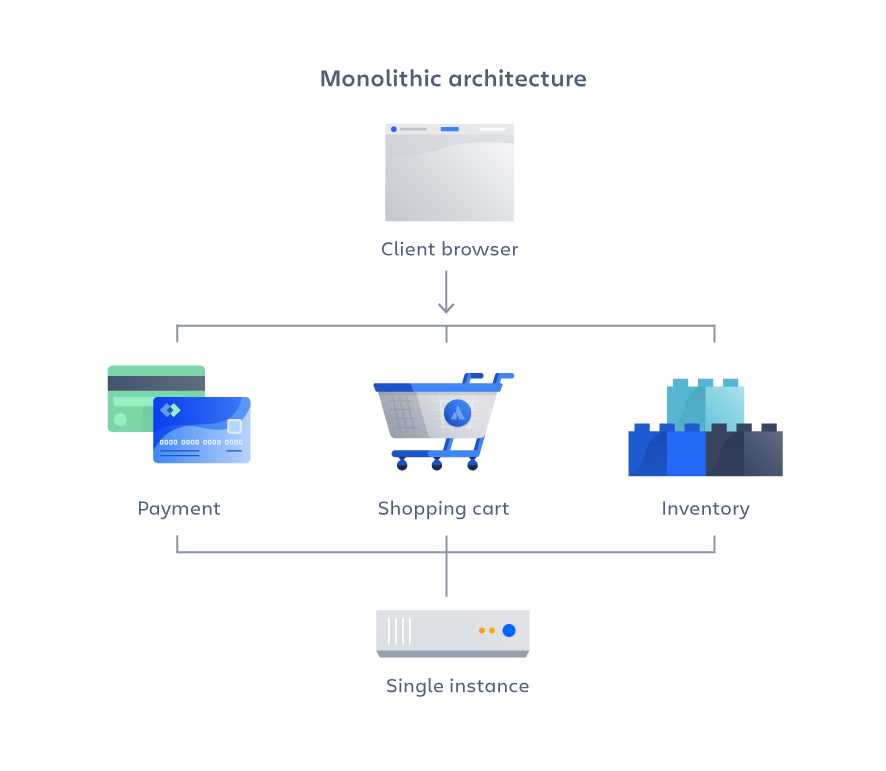
이게 보통 사용하는 구조라고 생각되는데,
그림과 같이 하나의 소프트웨어를 한 프로젝트에서 관리하는 느낌이다.
그렇다면 Moduler Monolith라는 건 뭘까?
4-2. Moduler

보통은 무언가를 쪼개 최소한의 단위로 만드는 것인데,
나는 퍼즐이 생각나는 것 같다.
당시 발표해주신 개발자님도 컨테이너 선박의 그림을 가져오셔서 설명해주셨다.
뭔가 나누는 의미의 Moduler와 합친 의미의 Monolith가 같이 있으니 신기한데,
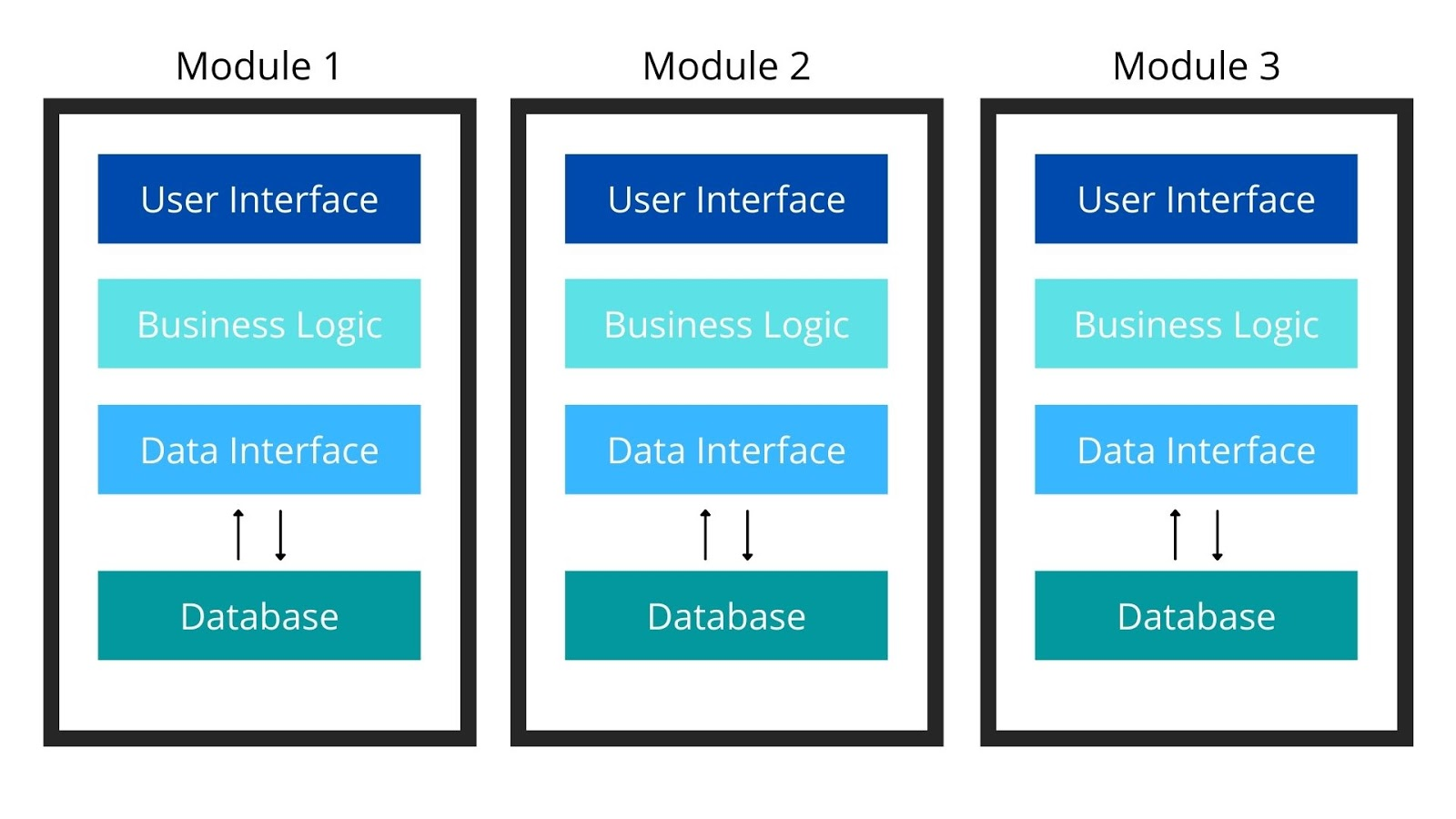
이런 모습으로, 기능의 로직을 모듈로 나누어 독립적인 형태로 구성하는 모습으로
생각하면 될 것 같다.
4-3. 어떤 아키텍처를 사용해야 할까?
아키텍처를 공부하면서 늘 나에게 던지던 질문이었다.
그렇다면 어떤 아키텍처가 가장 좋을까?
이 주제를 발표해주신 개발자 분은
의존성을 낮추기 위해서 Moduler Monolith를 사용했고,
커질 경우에는 이 모듈을 때어 네트워크 통신으로 변경하면 된다는 장점으로 선택하셨고
다만, 이를 위해서는 DB에서도 순환참조를 피하는 방식으로 비즈니스 관심사 분리가 필요하다고 하셨다.
사실 나는 아직 어떤 아키텍처가 더 좋다는 말은 하지 못하고,
우리 서비스에 어울리는 아키텍처에 대해 한번 더 생각해 볼 수 있는 기회였다.
Spring Booth에서도 Spring Modulith를 출시까지 했으니, 언젠가 사용해봐도 좋을 것 같다.
마무리 하며...
사실 혼자가게 된건 처음이라서 걱정이었는데,
생각보다 혼자가니 집중도 할 수 있고, 정리도 생각하며 해볼 수 있어서 좋은 기회였다.
그래서 정리하게 된걸 수도
다음 기회에도 꼭 예매에 성공하기를...
혹시 잘못된 정보가 있다면 망설이지 말고 꼭 댓글 부탁드립니다!
Reference
상품 주문 동시성 해결하기
Redis Replication
Redis의 특징과 사용법
마이크로서비스와 모놀리식 아키텍처 비교
Modular Monolithic Vs Micro Service
