
S3 용량을 어떻게 관리할 수 있을까? 에서 시작된 방법 구안
최근 Sopt의 AppJam 에서
AWS의 S3를 사용하여 게시글의 이미지를 저장 하는 로직을 세웠었다.
버킷 생성과 엑세스 키 발급부터 시작할건데 이 부분을 아는 분들은 3번 부터 보면 된다.
1. S3 Bucket 생성
우선 다른 사람들과 똑같이,
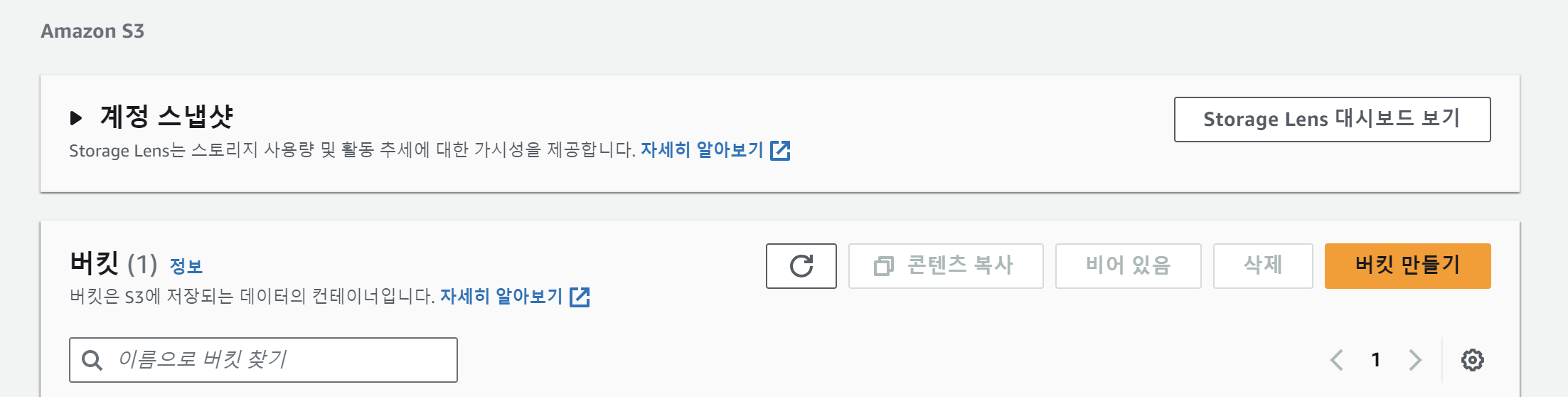
AWS에 들어가서 S3 bucket 만들기 를 눌러준다.
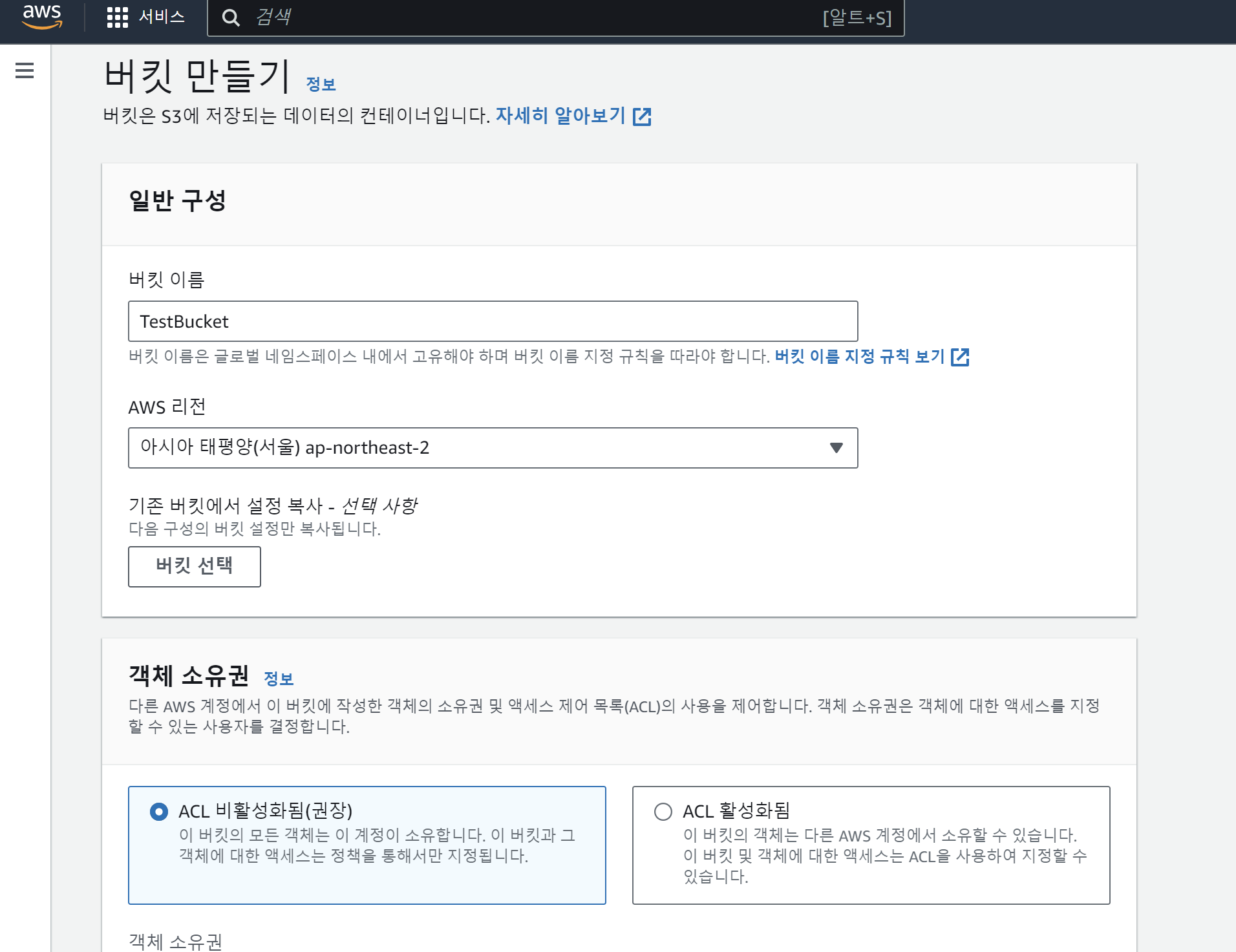
이후 만들고 싶은 버킷의 이름을 정하고,
나는 아무래도 서울에 살기 때문에 AWS 리전은ap-northeast-2 로 잡아줬다.
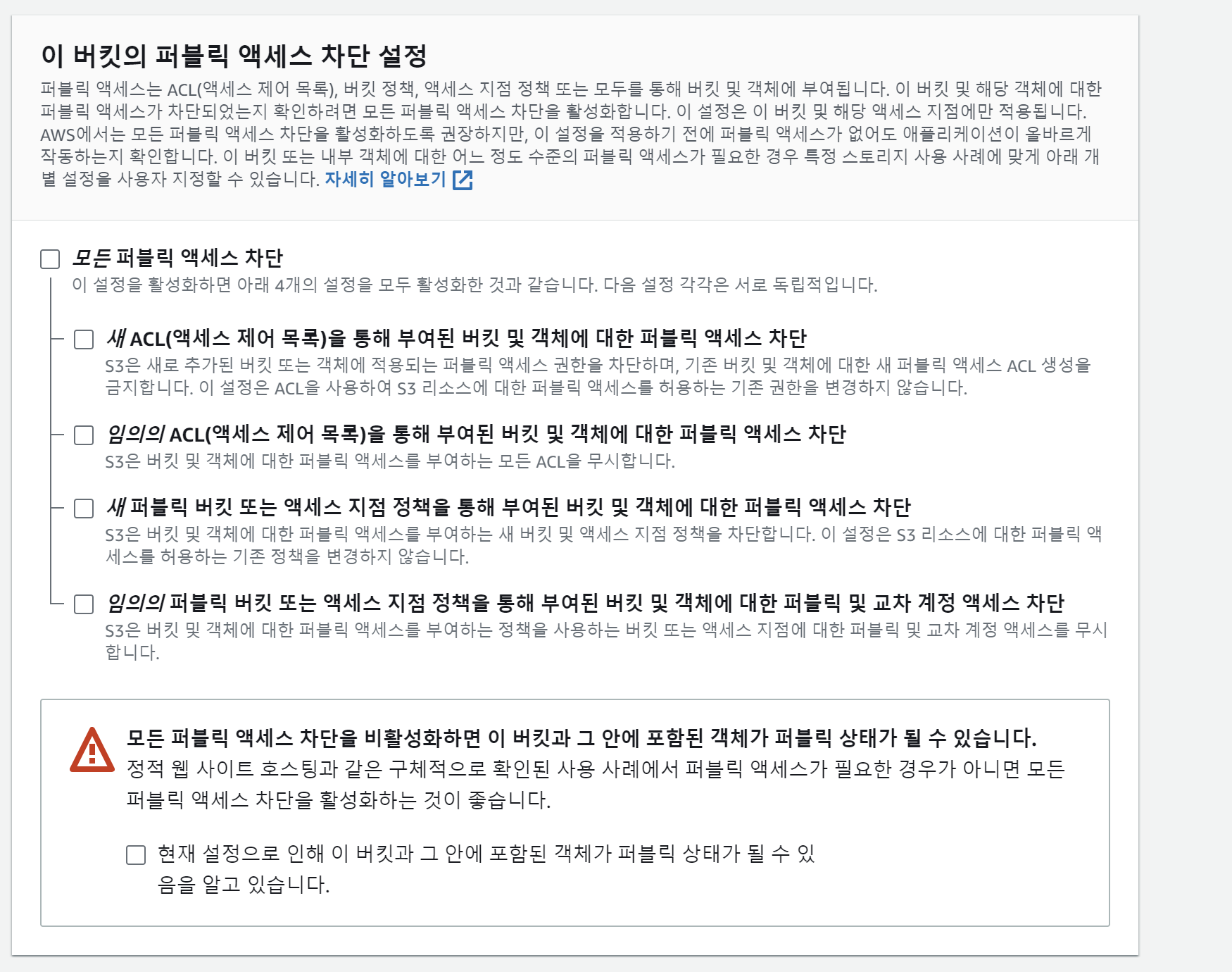
나 같은 경우는 이 링크로 유저가 접근이 가능해야 했기 때문에,🧐
퍼블릭 액세스 차단을 풀어줬다.
이후 나머지는 설정은 그대로 유지한 채 생성해줬다.
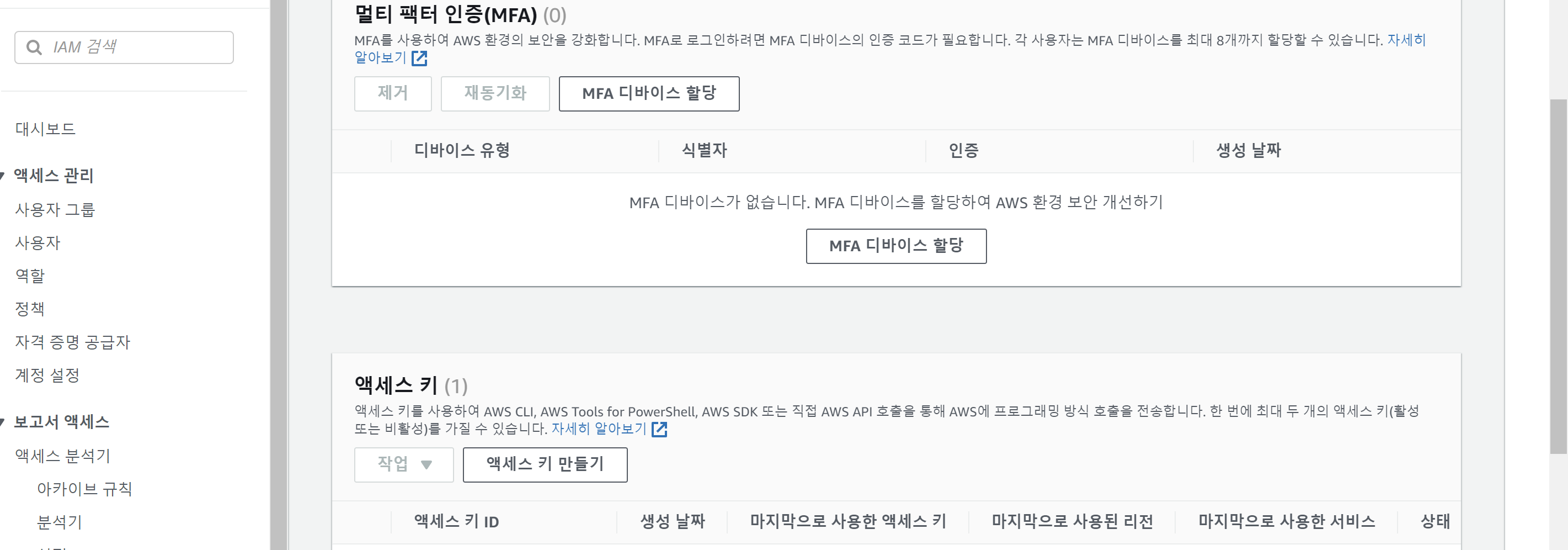
그리고 접근이 가능하려면 키를 발급받아야 하기 때문에
본인 계정 => 보안자격증명 으로 들어가서 엑세스 키를 발급 받아준다.
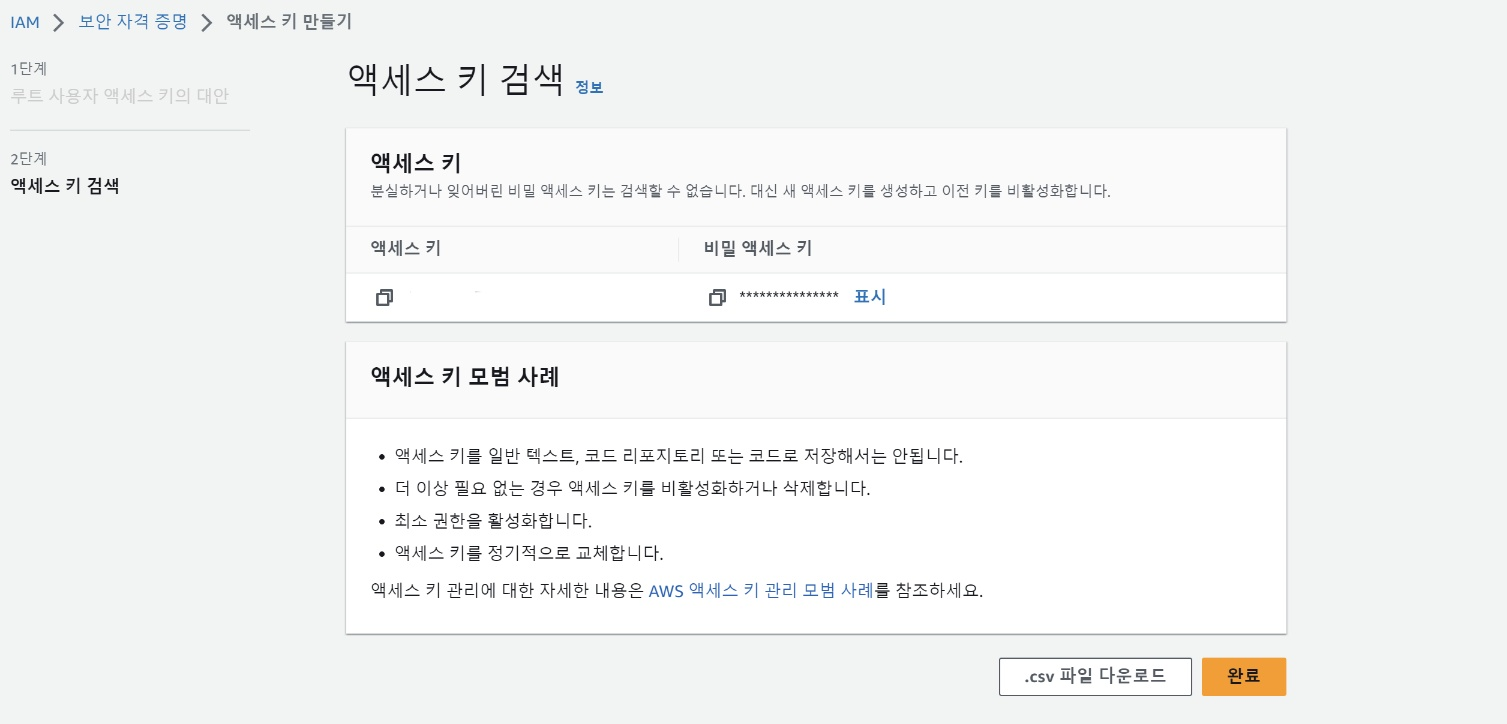
엑세스 키는 .CSV 파일을 다운받아서 꽁꽁 숨겨두고 필요할때 찾아보면 된다!
2. Intellij 설정
우선은 S3의 사용을 위해
build.gradle
implementation group: 'org.springframework.cloud', name: 'spring-cloud-starter-aws', version: '2.2.6.RELEASE'우선 위와 아래의 파일에 이 구문을 추가 해준다.
application.yml
cloud:
aws:
credentials:
access-key: {.csv 파일의 access-key}
secret-key: {.csv 파일의 secret-key}
region:
static: ap-northeast-2
s3:
bucket: {AWS에서 설정한 버켓 이름}이제 S3를 사용할 준비가 되었다!
@Slf4j
@Service
@RequiredArgsConstructor
public class S3Service {
private final AmazonS3 amazonS3;
private final AmazonS3Client amazonS3Client;
@Value("${cloud.aws.credentials.access-key}")
private String accessKey;
@Value("${cloud.aws.credentials.secret-key}")
private String secretKey;
@Value("${cloud.aws.s3.bucket}")
private String bucket;
@Value("${cloud.aws.region.static}")
private String region;
@PostConstruct
public AmazonS3Client amazonS3Client() {
BasicAWSCredentials awsCredentials = new BasicAWSCredentials(accessKey, secretKey);
return (AmazonS3Client) AmazonS3ClientBuilder.standard()
.withRegion(region)
.withCredentials(new AWSStaticCredentialsProvider(awsCredentials))
.build();
}이렇게 S3 Service를 작성해주면, AWS에 접근이 가능하다.🥳🥳🥳
3. 문제점 발생
우선, 나는 다른 블로그의 예제와 비슷하게
S3 Service에서 add 로직과 delete 로직을 사용해서 S3에 필요없는 사진들을 삭제 하고 있었다.
public String addImage(MultipartFile multipartFile, String folder) {
// 들어온 multipart 가 null 일 경우, 로직을 실행하지 않고 null return
if (multipartFile.isEmpty()){
return null;
}
String fileName = addFileName(multipartFile.getOriginalFilename());
ObjectMetadata objectMetadata = new ObjectMetadata();
objectMetadata.setContentLength(multipartFile.getSize());
objectMetadata.setContentType(multipartFile.getContentType());
try(InputStream inputStream = multipartFile.getInputStream()) {
amazonS3.putObject(new PutObjectRequest(bucket+"/"+ folder + "/image", fileName, inputStream, objectMetadata)
.withCannedAcl(CannedAccessControlList.PublicRead));
return amazonS3.getUrl(bucket+"/"+ folder + "/image", fileName).toString();
} catch(IOException e) {
throw new ImageException(ImageError.IMAGE_NOT_FOUND_ERROR, ImageError.IMAGE_NOT_FOUND_ERROR.getMessage());
}
}
// 파일명 random UUID
private String addFileName(String fileName) {
return UUID.randomUUID().toString().concat(findFileExtension(fileName));
}
// 파일의 유효성 검사, 가능한 확장자인지 확인
private String findFileExtension(String fileName) {
if (fileName.length() == 0) {
throw new ImageException(ImageError.IMAGE_NOT_FOUND_ERROR, ImageError.IMAGE_NOT_FOUND_ERROR.getMessage());
}
ArrayList<String> fileValidate = new ArrayList<>();
fileValidate.add(".jpg");
fileValidate.add(".jpeg");
fileValidate.add(".png");
fileValidate.add(".JPG");
fileValidate.add(".JPEG");
fileValidate.add(".PNG");
fileValidate.add(".gif");
String idxFileName = fileName.substring(fileName.lastIndexOf("."));
if (!fileValidate.contains(idxFileName)) {
throw new ImageException(ImageError.INVALID_MULTIPART_EXTENSION_EXCEPTION, ImageError.INVALID_MULTIPART_EXTENSION_EXCEPTION.getMessage());
}
return fileName.substring(fileName.lastIndexOf("."));
}
// 이미지가 여러개일 경우
public List<String> addImages(List<MultipartFile> multipartFileList, String folder) {
List<String> images = multipartFileList.stream().map(multipartFile -> addImage(multipartFile, folder)).collect(Collectors.toList());
return images;
}
public void deleteFile(String url){
if (url != null){
amazonS3Client.deleteObject( this.bucket , url.substring());
}
// 버켓 이름에 맞춰서 subString 길이 맞춰줘야함
}우선 나는 한가지 의문이 들었다.
수정을 하는 경우엔
내가 모든 사진을 수정할 수도, 한가지 사진을 수정할 수도 있다.
나는 모두 일관적인 Type으로 전달받아야 하는데 이를 어떻게 해결할까?
그렇다면
Velog나Notion은 이미지를 내가 붙여넣기를 실행했을때, 이걸 어떻게 처리할까?
그래서 나는 한가지 실험을 했다.
이미지를 집어넣고 Url을 확인하자!😲😲


두가지 모두 해보면 알겠지만 붙이자 마자, 해당 도메인이 붙어
바로 이미지가 저장이 되어 String 값인 Url을 보여주는 모습을 볼 수 있다.
나는 여기서 아이디어를 얻었다.💡💡
그렇다면 이미지를 저장하는 API를 만들어서, 수정을 할때도 일관적으로 String 값이 들어오도록 하면 어떨까?
@RestController
@RequiredArgsConstructor
@RequestMapping("/api/v1/image")
public class ImageController {
private final S3Service s3Service;
@PostMapping(value = "/add", consumes = MediaType.MULTIPART_FORM_DATA_VALUE, produces = MediaType.APPLICATION_JSON_VALUE)
@ResponseStatus(HttpStatus.CREATED)
public ApiResponse imageSave(@ModelAttribute ImageOneRequsetDto request){
if(request.getImage().isEmpty()){
return ApiResponse.error(ImageError.IMAGE_NOT_FOUND_ERROR, ImageError.IMAGE_NOT_FOUND_ERROR.getMessage());
}
String image = s3Service.addImage(request.getImage(), "image");
return ApiResponse.success(ImageSuccess.IMAGE_MODIFY_SUCCESS, image);
}
}하나의 Multipart File을 받는 RequestDto를 작성 후,
@ModelAttribute를 이용하여 from data 형식으로 받아준다.
혹시나 빈 파일을 첨부할 수도 있으니, 이는 ApiResponse.error로 에러 처리를 해줬다.
이렇게 하면 모두 일관적으로 들어오고, delete도 구현했고
S3의 용량을 최적화 했다고 생각했다.
다만 로직을 생각해보면 한가지 문제점이 생겼다.
이미지를 수정하고 뒤로가기를 한다면?
다시 Velog와 Notion을 보자.
아까 처럼 이미지를 저장하고 뒤로가기를 한다면 이미지가 삭제되어 있을까?

자, 이 사진은 내가 7월 7일에 실험용으로 넣고 글을 저장하지 않은채 뒤로가기 한 글에 첨부된 사진이다.
내가 지금 이 사진을 어떻게 불러올 수 있을까?🙄
당연히, 7월 21일 현재까지 지워지지 않았다는 뜻이다.
4. 해결법 고안
한창 알고리즘을 풀던 시절로 돌아가서 생각해봤다. 관련없는 뻘소리
어떻게 해결할 수 있을까?🤔🤔
- 넣은 이미지를 리스트에 넣고 해쉬맵으로 정말 전송한 사진만 true로 바꾸어 전송하면,
서버에서 해당 사진만 S3에 저장한다.
- 사진을 가지고 있다가 뒤로가기를 하는 경우 해당 사진 url을 받아 삭제한다.
- 처음엔 image라는 폴더에 저장했다가 실제 저장 이미지만 실제 도메인 이름이 달린 폴더로 이미지를 복사해 넣고, image라는 폴더는 주기적으로 삭제해준다.
이 글을 읽는 사람들은 어떻게 생각할지 모르겠지만,
나는 3번을 선택하고 S3 사진을 Copy 할 방법을 찾아봤다. 그러다 찾게된 S3의 CopyObject!
4-1. CopyObject 사용
📢 우선 해당 코드는 제 Bucket 이름에 맞게 구성되었기 때문에 복사하시는 분들은
본인들의 Bucket에 맞게 작성해야 한다는 부분을 알립니다
public String copyImage(String imageUrl, String url) {
String orgKey = imageUrl.substring(68);
String copyKey = url + "/" + orgKey.substring(7);
CopyObjectRequest copyObjectRequest = new CopyObjectRequest(this.bucket, orgKey, this.bucket, copyKey);
this.amazonS3Client.copyObject(copyObjectRequest);
return imageUrl.substring(0,68) + copyKey;
}CopyObjectRequest에는 우선 3가지 요소가 필요하다.
- bucket 이름
- orgKey
- copyKey
사실 이게 정말 레퍼런스가 적었는데
여기서 bucket은 변수처리를 했기 때문에 자동으로 들어가고,
orgKey는 기존의 버킷이름이 붙은 url을 제외한 복사하고 싶은 사진의 url이고
copyKey는 내가 붙여놓고 싶은 사진의 url이다.
이게 말이 어려운데
예를 들어 내가
https://s3.ap-northeast-2.amazonaws.com/testBucket/example/image/3j4jewe8wshdbb-s3k3-aq.jpg
{kind=link}
와 같은 링크의 이미지를 복사하고 싶다고 가정하자.
그렇다면 orgKey는 example/image/3j4jewe8wshdbb-s3k3-aq.jpg
copyKey는 testBucket 이후로 넣고 싶은 링크가 된다.
나는 return 값을 바로 DB에 넣어주고 싶어서 imageUrl에서 example을 삭제하고 copyKey 를 조합해
https://s3.ap-northeast-2.amazonaws.com/testBucket/copyKey/image/3j4jewe8wshdbb-s3k3-aq.jpg
{kind=link}
와 같이 만들어줬다.
나는 기존 이미지를 추가 할 경우엔 delete/에 넣어줬고, 이를 최종으로 넣을 경우에는
도메인 url을 붙여서

이와 같이 만들어줬다.
자 복사는 되었다. 아마 이 글을 보시는 분은 여기서 신나서 이미지를 보러 달려갈 겁니다.
그러면 여러분은 이와 같은 에러를 마주할것이고,

의문이 들겁니다.
왜냐면 내가 그랬기 때문
이와 관련해서 아무리 구글링해도, Bucket에서 퍼블릭 엑세스를 해주라는 말 뿐인데
우리는 처음에 생성할때 부터 퍼블릭 엑세스를 허용해줬다.
근데 왜 AccessDenied가 뜰까?
바로 CopyObjectRequest 를 할때, Access 관련 허가를 따로 내려줘야 하는 것.
copyObjectRequest.setCannedAccessControlList(CannedAccessControlList.PublicRead);이 코드를 S3서비스에 추가해주면...
해당 에러는 사라지고 사진의 퍼블릭 엑세스가 가능해진다!🥳🥳🥳
5. S3 수명주기
자 이제 사진은 복사했고, 이제 S3 관리를 시작해보자!
다시 AWS에 들어가서
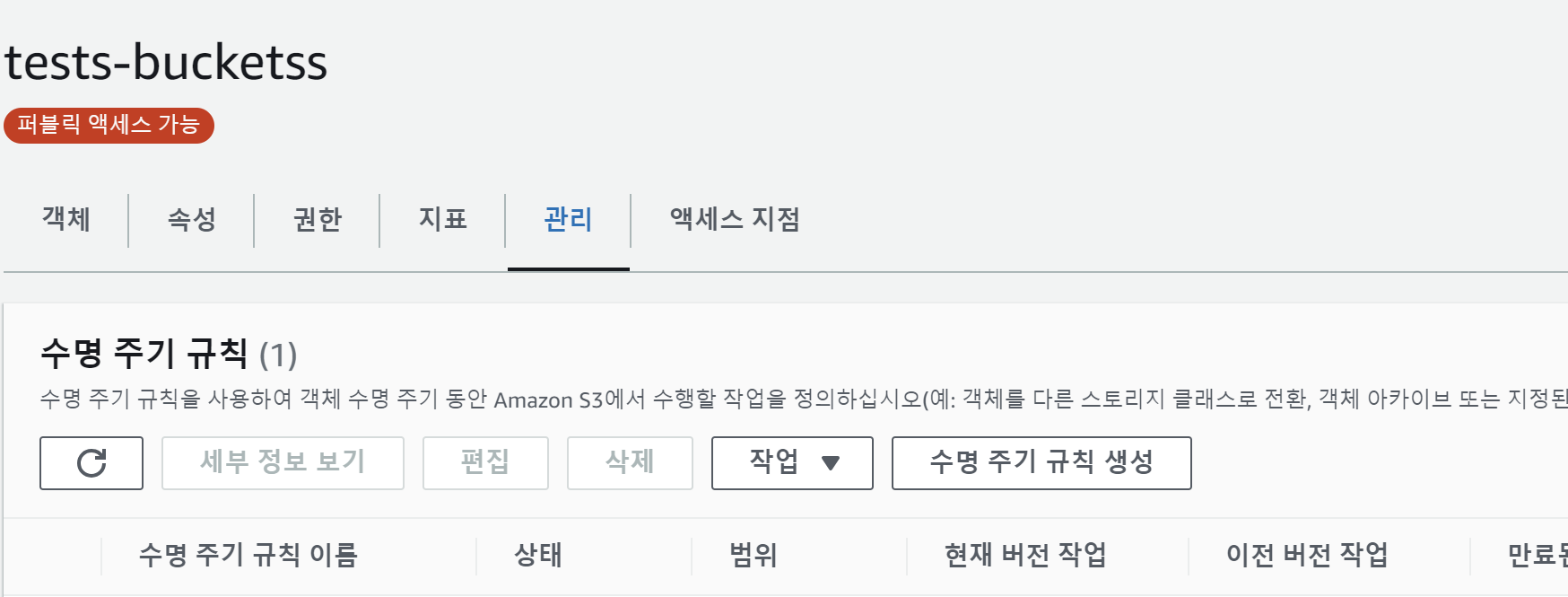
S3에서 관리를 누르고 수명주기 규칙 생성을 눌러주자
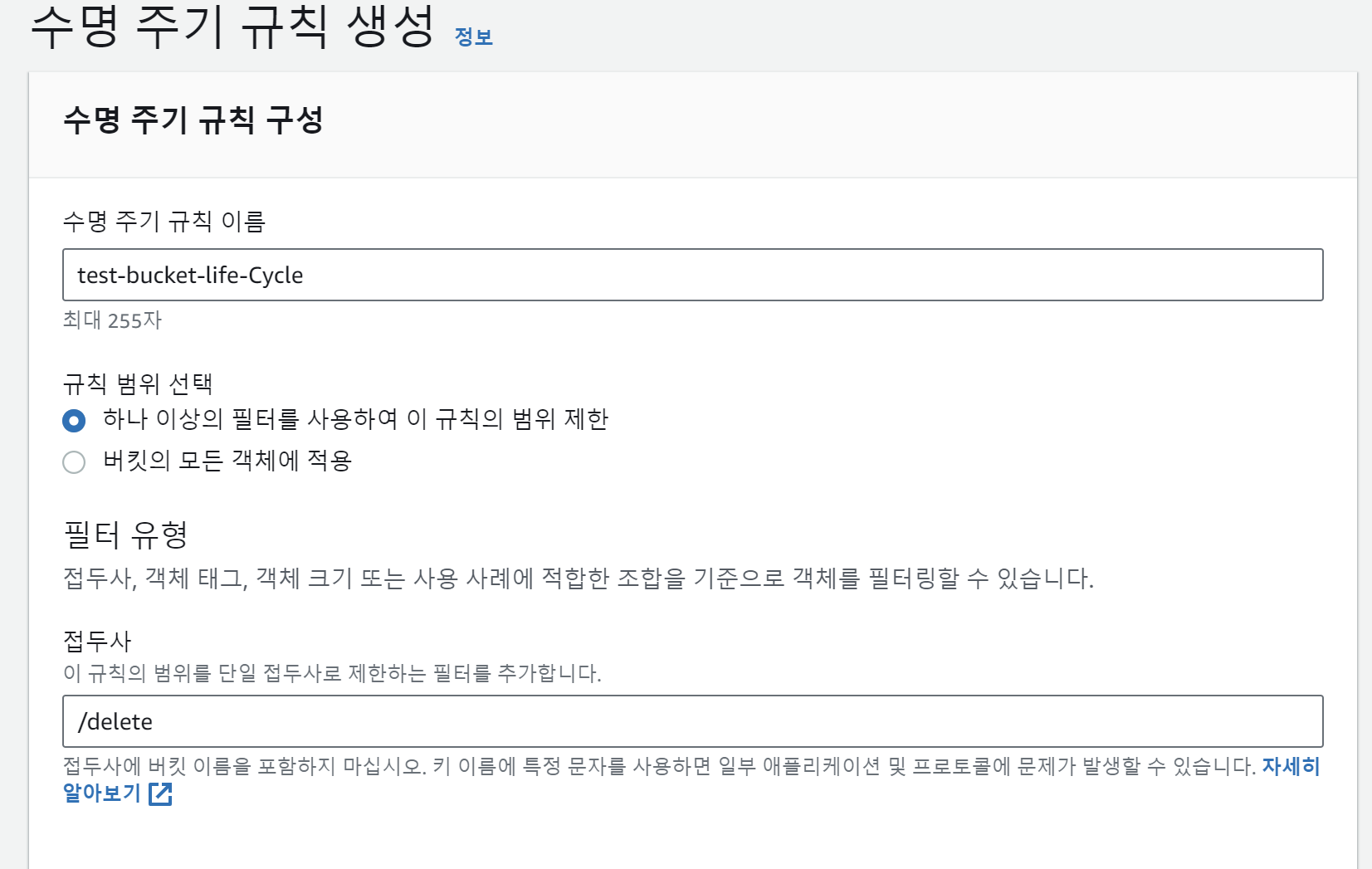
수명 주기 규칙의 이름을 주고,
필터 처리를 하고 싶은 접두사를 작성해주자.
나는 폴더링을 삭제할 이미지는 delete/ 하위에 놓았기 때문에 이렇게 작성해줬다.
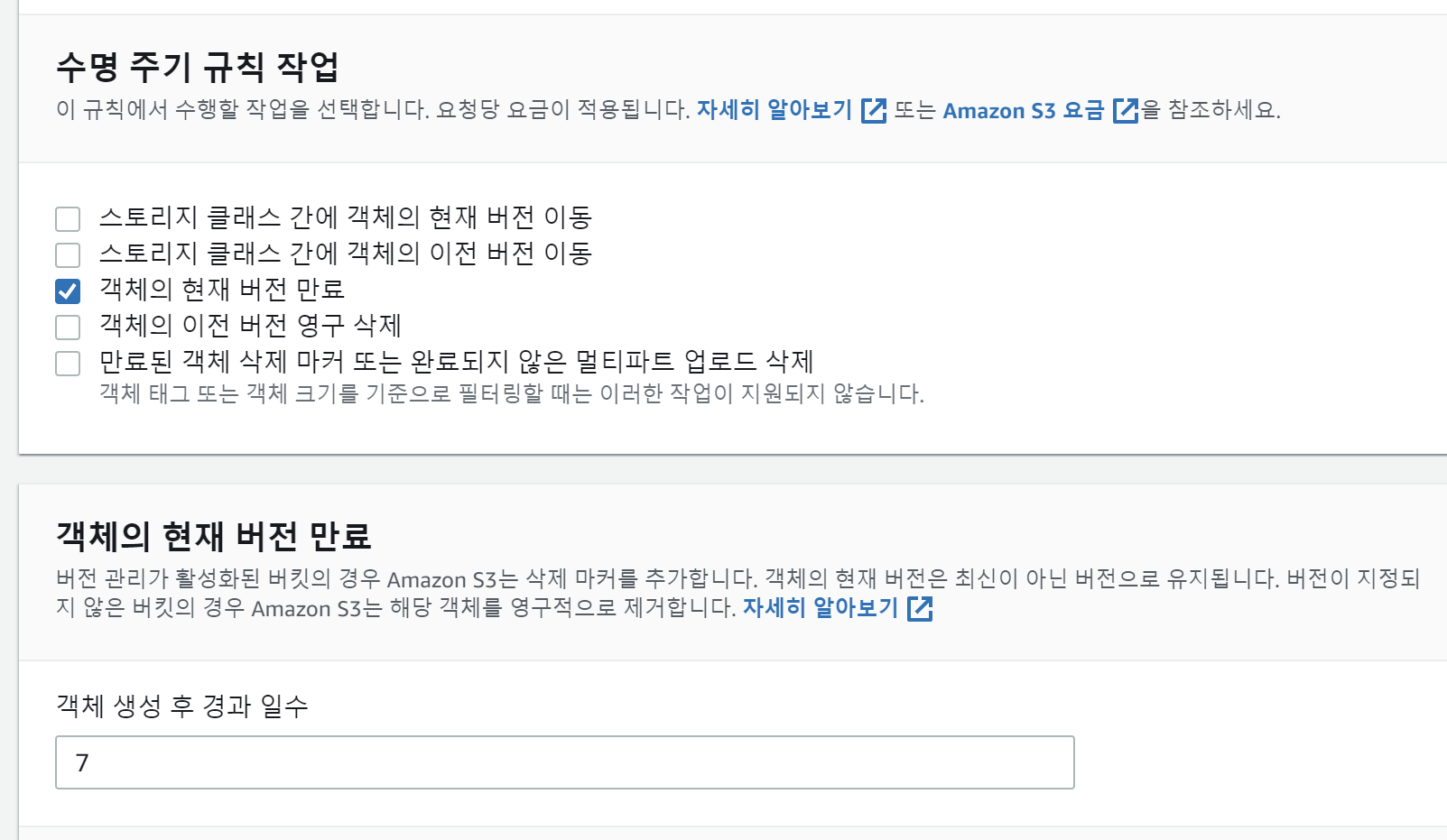
이후 나는 이 폴더의 객체가 생성된 후 7일이 지났을때, 객체가 삭제되도록 작성해줬다.
이렇게 처리한 후, 이제 7일 후에 S3에 들어가보면...
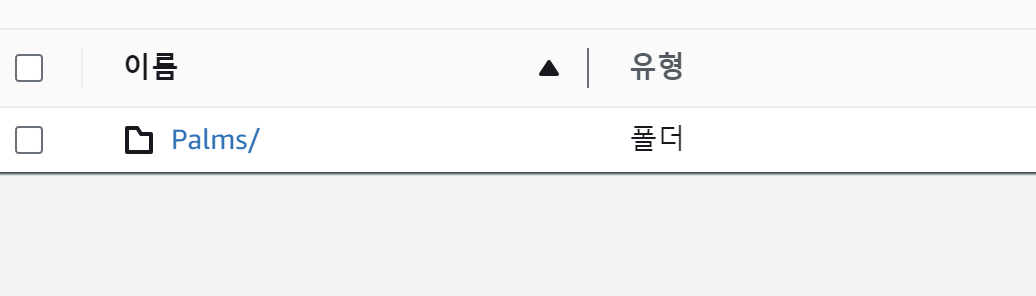
짜잔! delete/ 폴더의 객체가 사라져있다!😊😊
그리고 어떻게 보면 가장 중요한 부분 과연 수명주기규칙은 얼마일까?
아마 따로 변환하지 않았으면 Storage Class는 모두 동일하게 Standard 등급일 것이다.
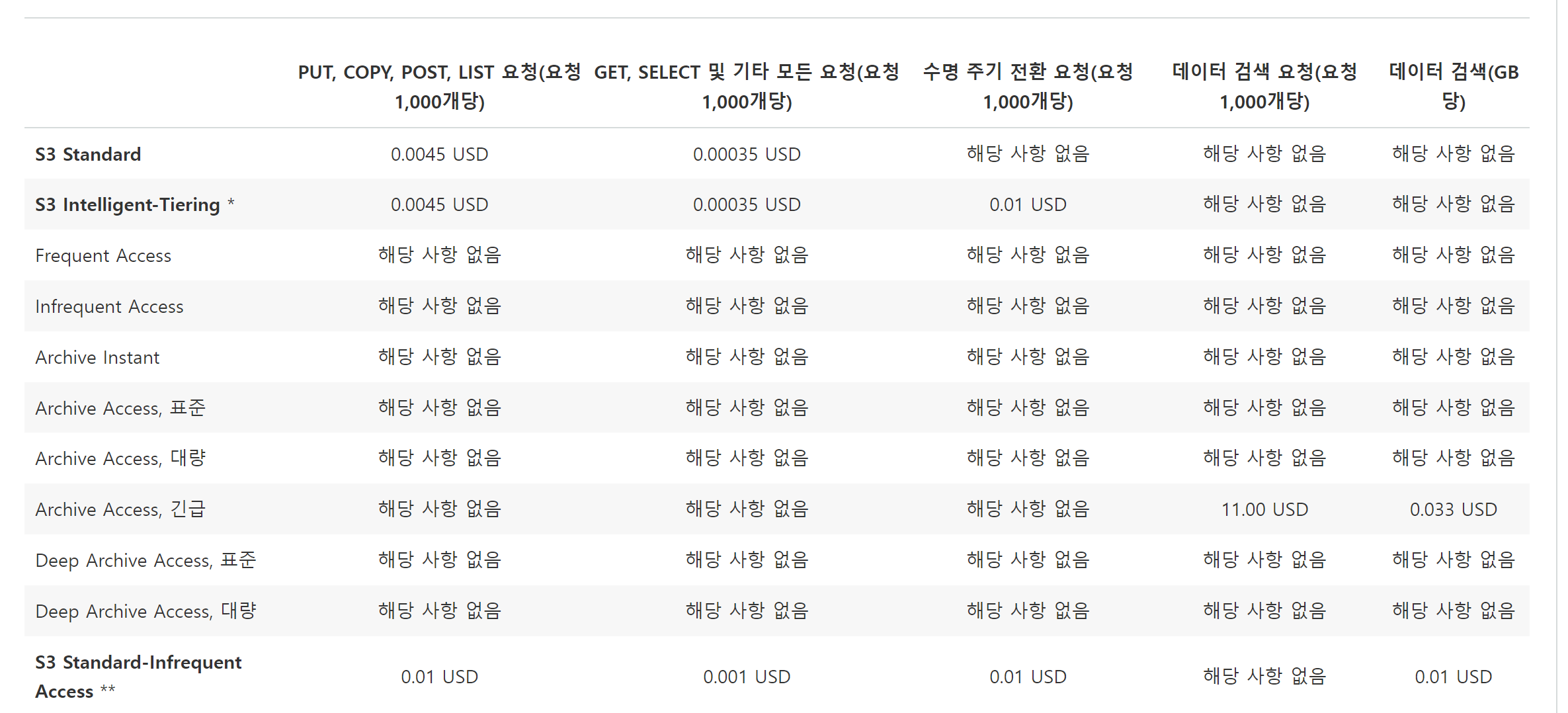
짜잔! 무려 해당사항 없음!
이렇게 우리는 주기적으로 필요없는 S3 객체의 저장도 막으면서 정말 사용하고 있는 사진만을
관리할 수 있게 되었다!
6. 마치며...
사실 관련된 레퍼런스가 적어서,
상상했던 부분이 될지 고민이 정말 많은채로 시작했었다.
누군가 같은 고민을 하는 사람들에게 도움이 되길 바라며... 마칩니다!
더 획기적인 방법이 떠오르면 추가적으로 작성하겠습니다. 그리고 잘못된 정보가 있다면 편하게 댓글 달아주세요! 끝!
