인문학적 개발자 늘한
저번 글에서는 python 의 모듈 중 하나인 requests에 대해서 알아봤었는데,
이번 글에서는 requests로 가져온 정보를 어떻게 원하는 입맛대로 뜯어볼 수 있는지 알아보겠습니다.
BeautifulSoup란?
"당신이 그 끔찍하게 생긴 웹페이지를 쓴 건 아닙니다. 당신은 그저 그 웹페이지에서 데이터를 가져오려 하고 있군요. 뷰티풀 수프가 도움을 주기 위해 여기 있습니다. 2004년 부터, 뷰티풀 수프는 프로그래머들의 화면을 긁어오는 수시간, 수일을 절약해주었습니다"
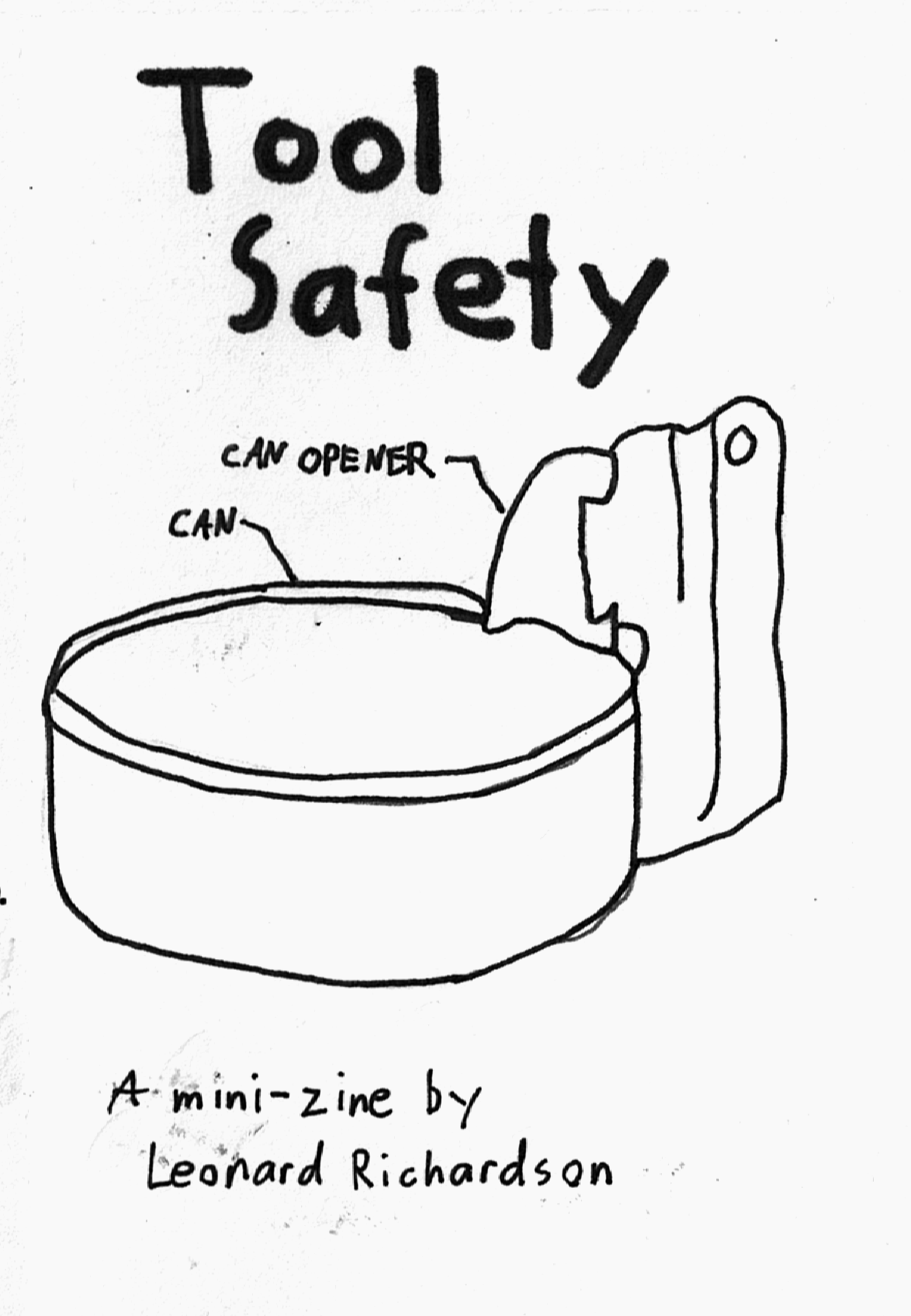
BeautifulSoup의 홈페이지에 들어가 보면 확인할 수 있는 글귀와 사진입니다.
ToolSafety 페이지를 보면 수프 캔을 따는 캔 따개의 그림이 그려져있숩니다.
BeautifulSoup라는 이름이 정확히 어떻게 지어진 건지는 모르겠지만
아마도 웹페이지의 데이터를 쓸 수 있게 끔 해주는 BeautifulSoup의 역할이 마치 통조림 캔을 따는 can opener의 그것과 같다는 뜻이 아닐까 추측해 볼 수는 있겠습니다.
BeautifulSoup는 마치 캔 따개 처럼 웹의 데이터를 먹을 수 있게 ( 사용할 수 있게 ) 해주는 모듈이다!
BeautifulSoup 코드 미리보기
BeautifulSoup를 이용한 코드를 한 번 미리 보도록 하죠.
import requests
from bs4 import BeautifulSoup as bs
url = "https://www.naver.com/"
html_text = requests.get(url).text
soup_obj = bs(html_text, "html.parser")
저번 글에서 이어지는 코드입니다.
BeautifulSoup 설치
윈도우 기준으로 윈도우 + R 키를 누르고 cmd를 검색하면 나오는 커맨드창에
pip install bs4
를 입력해주면 설치가 가능하지 만!
우리는 colab 환경에서 진행하고 있기 때문에 따로 설치하지 않아도 패키지가 준비되어있습니다. 넘어가 보도록 합시다
bs4
bs4는 BeautifulSoup ver.4 의 약자이고 2004년에 BeautifulSoup가 처음 나온 이후 네 번째 버전입니다.
from bs4 import BeautifulSoup as bsbs4 패키지에서 BeautifulSoup를 가져오면 되지만 이름이 너무 길어 불편할 수 있으므로 bs 정도로 바꿔주는게 일반적입니다. ( pandas 를 pd로 바꿔주는 것과 유사한 convention )
BeautifulSoup 객체
BeautifulSoup 객체는 생성될 때 두 개의 매개변수를 받도록 설계되어 있습니다.
soup_obj = bs(html_text, 'html.parser')첫 번째 인자는 str 형식이어야 하며, html 이나 xml 형식으로 작성된 문자열이어야 합니다.
보통 requests나 urllib로 가져온 웹페이지 정보에 .text를 붙여서 첫 번째 인자로 넣어주게 되죠.
두 번째 인자는 앞에서 넣은 text를 어떻게 요리할 지에 대한 해석기(parser) 를 넣어줘야 합니다.
BeautifulSoup Parser(뷰티풀 스프 해석기)
두 번째 인자로 넣어줄 parser로는 BeautifulSoup4 기준으로 4가지가 존재합니다.
| parser | 사용방법 | 장점 | 단점 |
|---|---|---|---|
| 파이썬의 html.parser | BeautifulSoup(markup, "html.parser") | 각종 기능 완비, 적절한 속도 | 이전 버전의 파이썬에 대해 호환성이 좋지 않음 ( 파이썬 2.7.3 이나 3.2.2 이전 버전에서) |
| lxml의 HTML 해석기 | BeautifulSoup(markup, "lxml") | 아주 빠름, 이전 버전 파이썬에 꽤 잘 호환됨 | 외부 C 라이브러리 의존 |
| lxml의 XML 해석기 | BeautifulSoup(markup, ["lxml", "xml"]) BeautifulSoup(markup, "xml") | 아주 빠름, 유일하게 XML 해석기 지원 | 외부 C 라이브러리 의존 |
| html5lib | BeautifulSoup(markup, html5lib) | 구 버전의 파이썬과 매우 호환 잘 됨, 웹 브라우저의 방식으로 페이지를 해석함, 유효한 HTML5를 생성함 | 아주 느림, 외부 파이썬 라이브러리 의존, 파이썬 2 전용 |
이렇게 4가지 종류의 parser가 존재하기는 하지만, !
보통 python 만 가지고도 환경설정 하기가 귀찮은 경우가 많기 때문에
( lxml parser는 외부 c 라이브러리에 의존 )
정말 전문적으로 매우 많은 양의 작업을 해야하는 일이 아니면 'html.parser'을 주로 쓰게 될 겁니다.
( XML parser 는 공공데이터 포털처럼 API 에서 보내주는 데이터가 XML 형식인 경우에 써볼 수 있기 때문에 , 후에 올릴 'python 으로 API 사용하기' 강의에서 다뤄보도록 하겠습니다. )
soup_obj = bs(html_text, 'html.parser')아무튼 다시 코드로 돌아와서 보면 이제는 이 코드를 완벽하게 이해할 수 있습니다.
bs() 객체를 생성하는데,
첫 번째 인자로 html text를, 두 번째 인자로 html parser를 보내줘서,
soup 객체를 얻어내는 코드인 겁니다.
print(soup_obj)프린트를 해보시면 지저분하게 줄줄히 나열되던 html 언어가
이렇게 꽤나 잘 정렬되어 보이는 걸 알 수 있습니다.
soup 객체 활용
BeautifulSoup를 이용해서 soup 객체를 만들어봤는데, 단순히 정렬되게 보여주는 거에서 끝날리가 없죠.
soup객체는 이 html에서 특정한 태그 밑의 text를 찾아내는데 아주 뛰어난 메서드를 가지고 있습니다.
find
findAll
select
이렇게 세 친구가 자주 쓰이는데, 저는 css 선택자를 이용할 수 있는 select 메서드를 한 번 알아보겠습니다.
soup_obj.select()
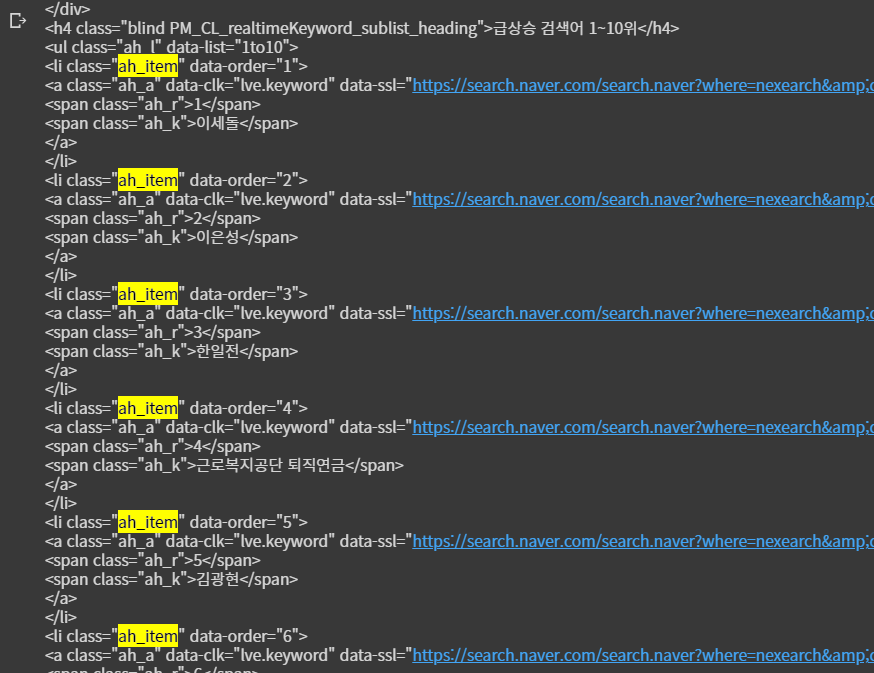
soup 객체를 뜯어보니 네이버 실시간 검색어 순위가 들어있습니다.
이 친구들을 가져와보고 싶을 때 사용할 수 있는 메서드가 바로 select입니다.
저 검색어 데이터가 들어있는 친구를 뜯어보니
'ah_item' 이라는 클래스를 가진 li 태그 안에
'ah_a'라는 클래스를 가진 a 태그 안에
'ah_k'라는 키워드를 가진 span 태그 안에 텍스트로 ---!
저희가 원하는 키워드가 들어있는 걸 확인할 수 있습니다.
방금 위에 썼던 긴 글을 css 선택자로 바꾸면
li.ah_item > a.ah_a > span.ah_k이렇게 쓸 수 있습니다.
" . " 은 클래스를 뜻하는 문법입니다.
혹시 크롤링을 하다가 id="ah_item"이라고 써있는걸 봤다면 #ah_item이라고 써주면 됩니다.
" # " 는 아이디를 뜻하는 문법입니다.
그리고 " > "는 '바로 아래에 자식으로 있는' 이라는 뜻입니다.
css 문법이기 때문에 html css를 거의 모르시는 분에게는 어려울 수도 있습니다.
이렇게 이런 select 메서드는 html에서 해당 선택자에 부합하는 태그들을 list 형태로 가져오게 됩니다.
