
자료구조
프로그램에서 사용할 자료를 기억장치에 저장하는 방법과 저장된 그룹 내의 자료 간의 관계, 처리 방법 등 연구 분석
자료구조 분류
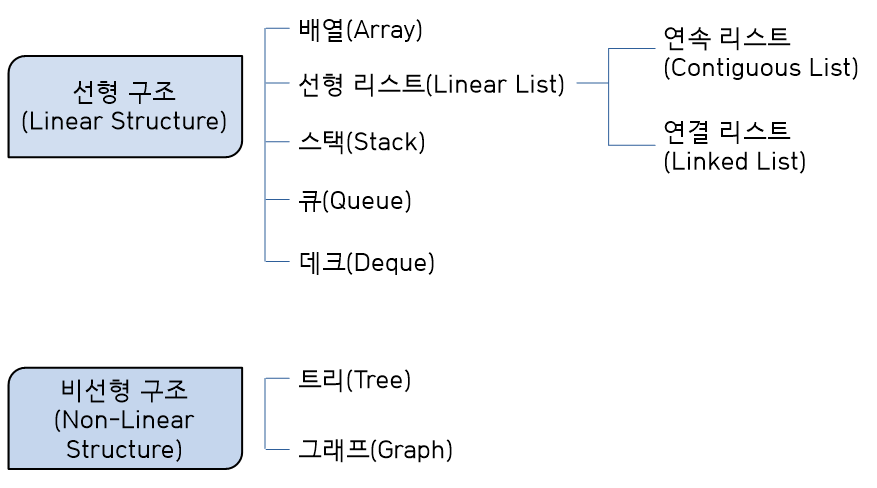
배열
동일 자료 형의 데이터들을 같은 크기로 나열하여 순서를 갖고 있는 집합- 정적인 자료 구조라 기억장소 추가가 어려우며, 데이터 삭제 시 메모리 낭비가 발생
- 첨자를 이용하여 데이터 접근
- 반복적 데이터 처리에 적합한 구조
- 사용한 첨자 개수에 따라 n차원 배열이라 부름
선형 리스트
일정한 순서에 의해 나열된 자료 구조이며, 연속 리스트와 연결 리스트가 있다.연속 리스트
일정한 순서에 의해 나열된 자료 구조(배열 사용)- 기억장소 이용 효율은 밀도 1이 가장 좋음(밀도가 낮을 수록, 자료가 빡빡하게 있을 수록)
- 중간에 데이터 삽입 시 연속된 빈 공간이 있어야 하며, 삽입·삭제 시 자료 이동 필요
연결 리스트
자료 항목 순서에 따라 노드 포인터 부분을 이용하여 연결시킨 자료 구조- 노드의 삽입·삭제가 쉬움
- 연결을 위해 포인터 부분이 필요하여 연속 리스트에 비해 기억 공간 효율 ↓
- 접근 속도가 느림
- 중간 노드 연결이 끊어지면 다음 노드 찾기가 어려움
스택(Stack)
리스트의 한쪽으로만 자료 삽입·삭제가 이루어짐LIFO(Last In First Out, 후입선출)방식오버플로우(Overflow): 기억공간 꽉 찬 상태에서 데이터 삽입 시 발생언더플로우(Underflow): 기억공간 텅 빈 상태에서 데이터 삭제 시 발생- Top : 가장 마지막 삽입 자료 기억된 위치
- Bottom : 스택 가장 밑바닥
큐(Queue)
리스트 한쪽에서 삽입, 다른 한쪽에선 삭제 작업이 이루어지는 자료구조FIFO(First In First Out, 선입선출)방식- F(Front) : 가장 먼저 삽입된 자료 기억 공간 가리키는 포인터, 삭제 담당
- R(Rear) : 가장 마지막에 삽입된 자료 기억 공간 가리키는 포인터, 삽입 담당
트리(Tree)
노드(Node)과 가지(Branch)를 이용하여 사이클 없이 구성한 그래프 형태의 자료구조- 기억 공간은
노드(Node), 노드를 연결하는 선은링크(Link) - 주로 족보, 조직도 등 표현
근노드(Root Node): 트리 맨 위의 노드디그리(Degree): 각 노드에서 뻗어나온 가지 수단말노드(잎 노드): 자식이 없는 노드트리의 디그리: 노드들의 디그리 중 가장 많은 수
DBMS
데이터저장소
데이터들을 논리적 구조로 조직화하거나 물리적 공간에 구현한 것
논리 데이터저장소는 데이터 및 데이터 간 연간성, 제약 조건 등을 식별하여 논리적 구조로 조직화
물리 데이터저장소는 논리 데이터저장소에 저장된 데이터와 구조들을 하드웨어적 저장장치에 저장
데이터베이스
통합된 데이터(Integrated Data): 자료의 중복 최소화저장된 데이터(Stored Data): 컴퓨터가 접근 가능한 저장 매체에 저장운영 데이터(Operational Data): 조직의 고유 업무 수행 시 필요한 자료공용 데이터(Shared Data): 시스템을 공동으로 소유·유지
DBMS
DBMS의 필수 기능 : 정의, 조작, 제어
정의 기능(Definition): 데이터베이스에 저장될 데이터 타입·구조 정의, 이용 방식, 제약 조건 명시조작 기능(Mainoulation): 데이터 검색, 갱신, 삽입, 삭제 등 수행할 때 사용자-데이터베이스 간 인터페이스 제공제어 기능(Control): 데이터 무결성 유지, 보안 유지 및 권한 검사, 정확성 유지하기 위한 병행 제어
DBMS의 장점
- 데이터 독립성·일관성·무결성 유지
- 보안 유지
- 데이터 표준화·통합·실시간 처리 가능
DBMS의 단점
- 전문가 부족
- 전산화 비용 증가
- 집중 액세스로 과부하 발생
- 파일 백업과 회복 어려움
- 시스템 복잡
데이터 입출력
소프트웨어 기능 구현을 위해 데이터비으세 데이터 입력·출력하는 작업SQL
- 국제표준 데이터베이스 언어
- 데이터
정의어,조작어,제어어로 구분정의어(DDL; Data Define Language): 스키마, 도메인, 테이블, 뷰, 인덱스를 정의·변경·삭제조작어(DML; Data Matinpulation Language): 프로그램이나 질의어를 통해 저장된 데이터를 실질적 처리제어어(DCL; Data Control Language): 데이터 보안, 무결성, 회복, 병행 수행 제어 등 정의
데이터 접속(Data Mapping)
프로그래밍 코드와 데이터베이스 데이터를 연결하는 행위SQL Mapping: 프로그래밍 코드 내 SQL을 직접 입력하여 DBMS의 데이터에 접속 (ex. JDBC, ODBC, MyBatis)ORM: 객체 지향 프로그래밍의 객체와 관계형 데이터 베이스의 데이터를 연결 (ex. JPA, Hibernate, Django)
트랜잭션(Transaction)
데이터베이스의 상태를 변환하는 작업의 단위 또는 수행할 연산- 트랜잭션 제어할 때 사용하는 명령어를
TCL(Transation Control Language)라고 하며, TCL에는COMMIT,ROLLBACK,SAVEPOINT가 있다. COMMIT: 트랜잭션이 수행한 변경 내용을 데이터베이스에 반영ROLLBACK: 트랜잭션이 행한 작업을 취소하고 이전 상태로 되돌림SAVEPOINT: 롤백할 저장점을 지정
절차형 SQL
프로그래밍 언어처럼 연속적 실행이나 분기, 반복 등 제어가 가능한 SQL- 단일 SQL 문장으로 처리하기 어려운 연속적 작업 처리에 적합
- BEGIN ~ END 형식의 블록 구조라 기능별 모듈화 가능
- 절차형 SQL 종류 :
프로시저,트리거,사용자 정의 함수- 프로시저(Procedure) : 호출을 통해 미리 저장해놓은 SQL 작업 수행
- 트리거(Trigger) : 이벤트 발생할 때마다 관련 작업이 자동으로 수행
- 사용자 정의 함수 : 프로시저와 비슷하나, 종료 시 예약어 Return을 사용하여 처리 결과를 단일값으로 반환

keep going