딥러닝 모델 (DNN, Deep Neural Network)
🔴 Feedforword network
: 정보가 입력층에서 출력층으로 한 방향으로만 흐름.
1. MLP (Multi-Layer Perceptron)
- 가장 기본적인 신경망 구조로, Fully Connected Layer(완전 연결층)로 구성됨
- 각 층의 뉴런이 이전 층의 모든 뉴런과 연결 (Dense Layer)
- 비선형 활성화 함수 (ReLU, Sigmoid 등)를 사용하여 복잡한 패턴 학습 가능
- 주로 구조가 단순한 데이터(표 형식 데이터, 간단한 분류 문제) 처리에 사용됨
구성 요소:
- 입력층(Input Layer): 데이터 입력
- 은닉층(Hidden Layer): 비선형 변환 및 학습 수행. Fully Connected Layer.
- 출력층(Output Layer): 최종 예측값 도출
활용 분야:
- 기본적인 분류(Classification) → 숫자 인식(MNIST), 질병 예측
- 회귀(Regression) → 가격 예측, 날씨 예측
- 기본적인 특징 학습 → CNN, RNN 등에 포함되어 사용됨
한계점:
- Fully Connected Layer로 구성되어 있어 파라미터 수가 많음 → 연산량 증가
- 이미지, 시계열 데이터 처리에는 비효율적 (특징 학습이 어려움)
- 과적합(Overfitting) 가능성이 높음
2. CNN (Convolutional Neural Network) - 이미지 처리 특화
📏 출력 크기 계산 공식
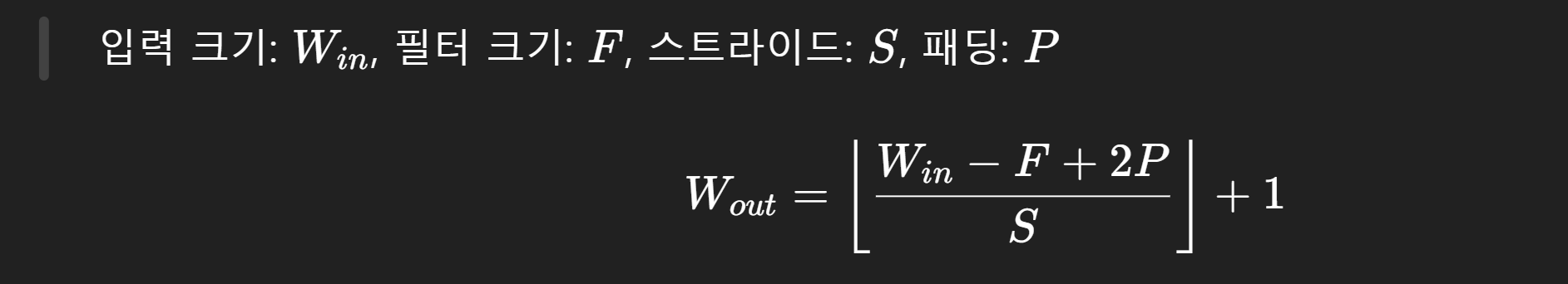
✏️ CNN 계산 원리
📦 1. 기본 원리: 필터 = 패턴 감지기
- CNN의 필터는 작은 크기의 가중치 행렬
- 이 필터를 이미지 위에서 슬라이딩하면서, 입력 이미지의 특정 부분과 내적(dot product)을 수행
🧬 2. CNN이 학습하는 과정
실제 CNN에서는 사람이 위 필터를 직접 만들지 않음
👉 대신, 필터의 값(가중치)을 학습!
초기에는 필터가 "무작위 값"임
하지만 학습을 반복하면서:
어떤 필터는 "수직선"에 민감해지고
어떤 필터는 "둥근 윤곽"에 민감해지고
어떤 필터는 질감이나 반복 패턴에 반응하도록 조정됨
즉, CNN은 데이터 안에서 자주 나타나는 패턴을 자동으로 “탐지기”로 만들어냄.
3. 🪜 계층적 구조
CNN은 필터를 여러 층으로 쌓음.
1층: 엣지, 선, 방향
2층: 모서리, 패턴
3층 이상: 눈, 얼굴, 사물의 형태
마치 사람 눈처럼 저수준 → 고수준 특징을 순차적으로 학습해 나가는 구조
🧱 CNN의 핵심 블록: Convolution → ReLU → Pooling
🎯 전체 구조 요약
[입력 이미지]
↓
[Convolution] : 특징 추출
↓
[ReLU] : 비선형성 부여
↓
[Pooling] : 정보 압축 + 특성 유지
↓
[다음 층 반복]1️⃣ Convolution (합성곱)
📌 역할
이미지의 지역적인 특징(엣지, 선, 질감 등)을 필터(커널)로 감지
🧮 작동 방식
입력 이미지 위에서 작은 필터를 슬라이딩하며 내적 연산
각 위치마다 특징 맵(feature map) 생성
📷 예시
입력: 32×32×3 (컬러 이미지)
필터 크기: 3×3×3
→ 출력: 30×30×1 (특징 맵 하나)
여러 개의 필터를 쓰면 → 출력 채널 수(깊이)가 늘어남
2️⃣ ReLU (Rectified Linear Unit)
📌 역할
비선형성 부여 (이미지 특징을 더 잘 구분하기 위해)
음수 값을 0으로, 양수는 그대로 유지
ReLU(x) = max(0, x)✅ 이유
만약 CNN 전체가 선형 연산만 했다면, 아무리 많은 층을 쌓아도 결국 선형 결과만 나옴 → 의미 없음
ReLU는 그걸 깨고 복잡한 패턴도 학습할 수 있도록 함
3️⃣ Pooling (서브샘플링, 다운샘플링)
📌 역할
특징 맵을 더 작게 줄이면서 (압축)
중요한 정보는 유지
연산량 줄이고, 불변성(invariance)도 증가
🧮 종류
| 종류 | 설명 |
|---|---|
| Max Pooling | 윈도우 내에서 최댓값만 남김 (가장 흔함) |
| Average Pooling | 윈도우 내 평균값을 남김 |
🔁 반복 구조
이 세 개는 보통 한 블록처럼 계속 반복돼:
[Conv → ReLU → Pool] → [Conv → ReLU → Pool] → ...✅ 요약
단계 이름 역할
1 Convolution 이미지에서 특징 추출
2 ReLU 비선형성 부여, 학습력 증가
3 Pooling 정보 압축, 위치 불변성 증가
❓ 왜 CNN(Convolutional Neural Network)을 사용하는가?
1️⃣ 공간적 특징 추출에 특화
- 이미지 내 엣지, 선, 모서리, 질감 등 지역적 패턴(local features)을 자동으로 감지
- 필터(커널)를 통해 공간 구조를 고려한 특징 추출 가능
- → 이미지나 영상 처리에 최적화된 구조
2️⃣ 파라미터 효율성 (MLP 대비)
- 입력 이미지가 224×224×3일 경우, MLP에선 수천만 개 파라미터 필요
- CNN은 필터를 전체 영역에 공유 (weight sharing)하기 때문에
- 학습 파라미터 수가 적음
- 연산 속도 빠름
- 과적합 위험 낮음
3️⃣ 위치 불변성 (Translation Invariance)
- 이미지 내 객체의 위치가 조금 달라져도 같은 특징으로 인식 가능
- Convolution + Pooling 연산 덕분에 위치 변화에 강함
- 예: 고양이 위치가 바뀌어도 “고양이”로 인식
4️⃣ 계층적 특징 학습 (Hierarchical Feature Learning)
- 층이 깊어질수록 점점 더 복잡한 특징을 학습함
| 층 단계 | 학습하는 특징 |
|---|---|
| 얕은 층 | 엣지, 선, 색 대비 등 기본 형태 |
| 중간 층 | 모양, 질감, 단순 패턴 등 |
| 깊은 층 | 얼굴, 사물 등 고수준 개념 |
5️⃣ 다양한 시각 문제에 적용 가능
CNN은 다양한 컴퓨터 비전 분야에서 뛰어난 성능을 보여줌:
- 이미지 분류 (Image Classification)
- 물체 탐지 (Object Detection)
- 얼굴 인식 (Face Recognition)
- 자율주행 비전 (Autonomous Driving)
- 의료 영상 분석 (Medical Imaging)
- 영상 생성 (Generative Models, e.g. GAN)
6️⃣ 자동 특징 추출 (End-to-End Feature Learning)
- 전통적인 방식(SIFT, HOG 등)은 사람이 수동으로 특징 설계
- CNN은 데이터로부터 특징을 자동으로 학습
- → 유연성 높고, 문제에 따라 확장 가능
- Transformer
Positional Encoding
Multi-head Attention
🟣 Feedback network
: 은닉층에 피드백 연결을 가지고 있어 이전 단계의 정보를 기억하고 활용함.
3. RNN (Recurrent Neural Network)
- 이전 타임스텝의 정보를 기억하며 순차적(Sequential) 데이터 처리 가능
- 순환 구조(Recurrent Connection) 를 통해 이전 상태(hidden state)를 다음 단계로 전달
- 시계열(Time-Series), 자연어 처리(NLP) 등 시간 의존성이 있는 데이터에 적합
구성 요소:
- Hidden State: 과거 정보를 저장하는 내부 상태
- Recurrent Connection: 현재 입력과 이전 hidden state를 함께 처리
활용 분야:
- 자연어 처리 (NLP) → 번역기, 챗봇
- 음성 인식 (Speech Recognition) → Siri, Google Assistant
- 금융 데이터 예측 → 주가 예측, 트렌드 분석
- 음악 생성 (AI 작곡)
한계점:
- Gradient Vanishing(기울기 소실) 문제 → 학습이 어려워짐
- 긴 시퀀스를 처리하는 데 한계 → 장기 의존성(Long-Term Dependency) 문제 발생
4. LSTM (Long Short-Term Memory) - RNN의 개선 버전
RNN(Recurrent Neural Network)은 학습 과정에서 Gradient Vanishing 문제가 있었고, 이를 해결하기 위해 셀 상태, Gate (Input, Forget, Output) 개념을 도입한 것이 LSTM
- RNN의 Gradient Vanishing 문제 해결
- 장기 기억(Long-Term Memory) 유지 가능
- 게이트(Gate) 메커니즘을 활용하여 중요 정보만 저장하고 불필요한 정보 제거
구성 요소:
- Forget Gate: 불필요한 정보 제거
- Input Gate: 새로운 정보를 저장할지 결정
- Output Gate: 최종 출력을 생성
활용 분야:
- 장기 의존성이 중요한 NLP → 기계 번역(Translator), 문맥 이해(Chatbot)
- 음성 인식 → 구글 음성 입력, 자동 자막 생성
- 시계열 예측 → 기상 예측, 주식 예측
한계점:
- 연산량이 많고 느림 → 파라미터 수가 많아 학습이 오래 걸림
- 병렬 연산이 어려움 → Transformer 모델이 등장하면서 LSTM의 활용이 줄어듦
출처: https://salmon1113.tistory.com/67#1. Feedforward Network-1-1
