Github의 배포
파일업로드

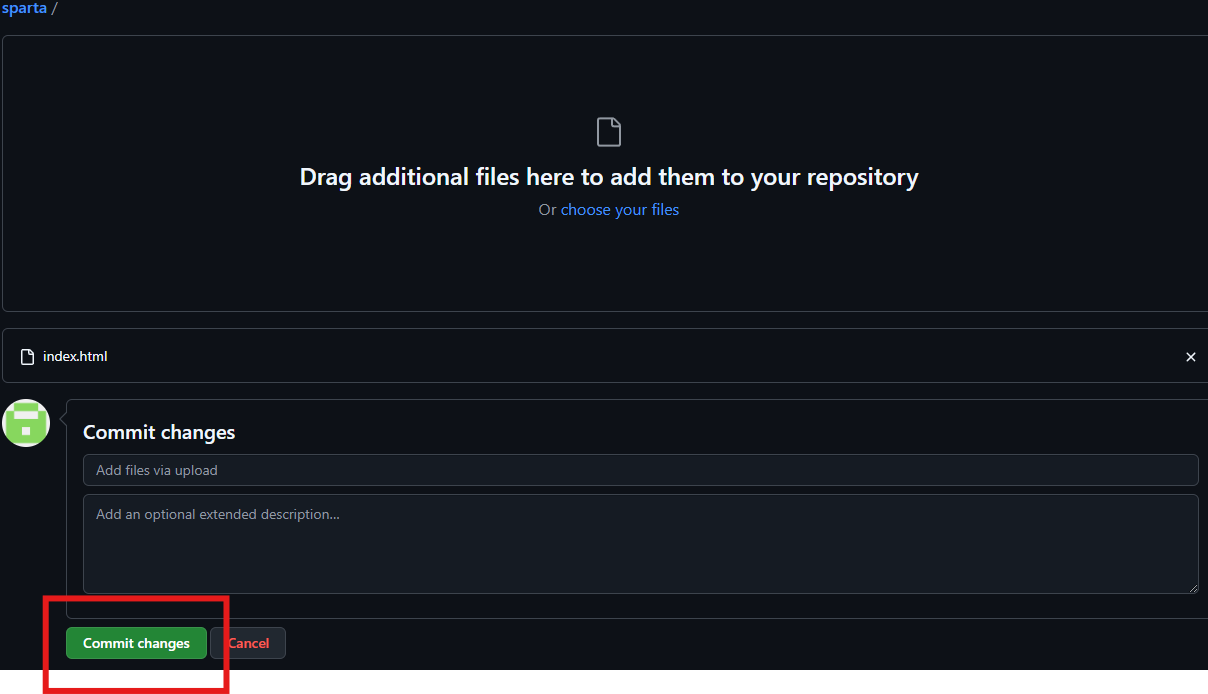
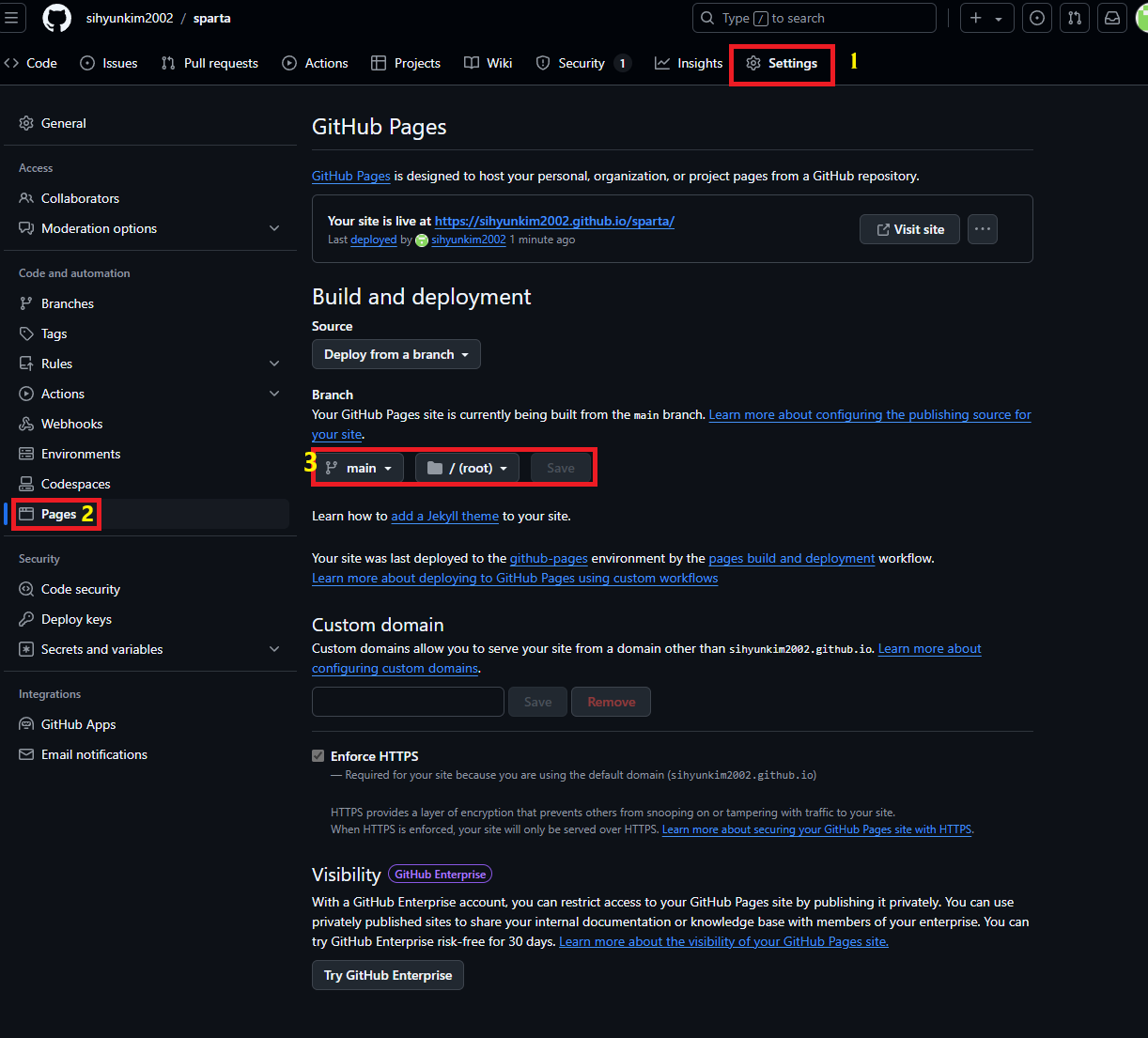
Settings - pages
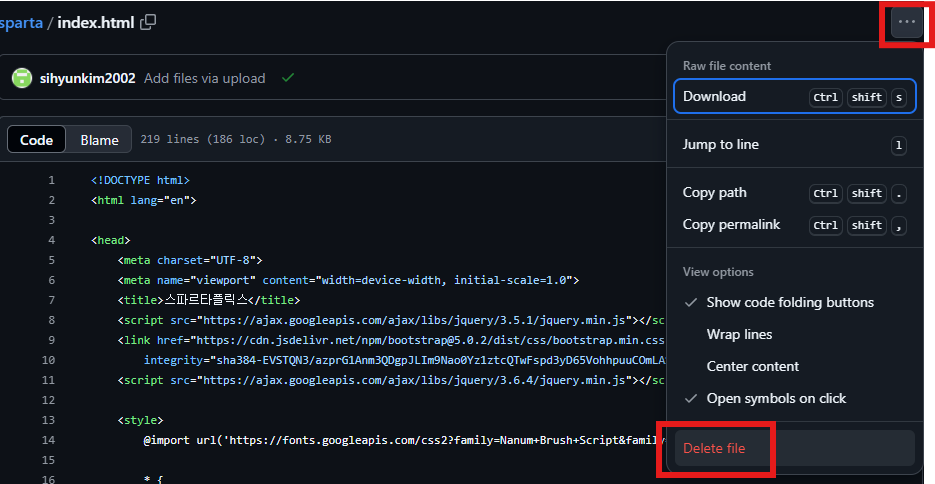
깃허브 수정
 |  |
|---|
firebase의 한계점
저장하고 받는 것 외에는 커스텀마이징 하기 어려움
구글서비스에만 의존한다.
- 파이썬의 장점
백앤드에서 일어나는 일들을 컨트롤 할 수 있다.
Google Colab
파이썬 무료
ctrl +enter로 코드 결과 확인
되게 직관적이다.
크롤링 웹에 있는 정보를 가지고 오는 것
스크래핑의 원리
스크래핑은 인터넷에서 필요한 정보를 가져오기 위해 웹 페이지의 구조와 내용을 읽어오는 것
스크래핑을 할 때, 내가 웹 페이지의 HTML 코드를 이용한다.
HTML은 웹 페이지의 구조와 내용을 담고 있는 언어
웹 페이지의 뼈대로 이해하면 편함
스크래핑은 이 HTML 코드를 컴퓨터가 이해할 수 있는 방식으로 읽어오는 것
스크래핑 기본 세팅
import requests //남들이 만들어 놓은 것 from bs4 import BeautifulSoup / URL = "https://bit.ly/web-movie" headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'} data = requests.get(URL, headers=headers) / soup = BeautifulSoup(data.content, 'html.parser') print(soup)//
BeautifulSoup
여기서 내가 필요한 것만 복사하는 걸
도와주는 라이브러리
requests
가지고 오는 도와주는 것
select/ select_one
태그 안의 텍스트를 찍고 싶을 땐 → 태그.text
태그 안의 속성을 찍고 싶을 땐 → 태그 ['속성']
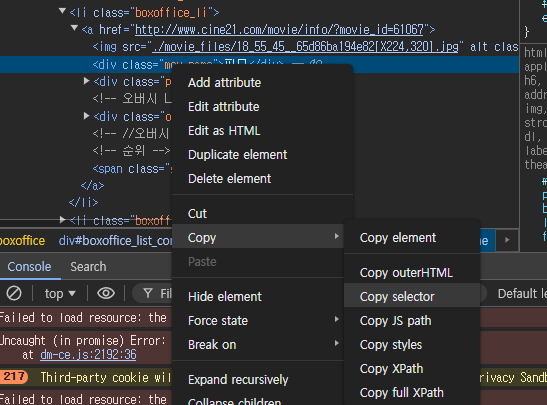
파이썬에서 필요한 것만 가져오기 위해서
title = soup select_one('')
한개를 사용하겠다는 것
print(title.text)
제목만 나옴
파이썬을 배우면 서버에 내가 만든 홈페이지를 직접 올리고 회원가입 로그인 같은 걸 구현할 수 있다.
