*Crwler
-조직적, 자동화된 방법으로 월드 와이드 웹을 탐색하는 컴퓨터 프로그램(From 위키백과)
*Seeds
-https://wikipedia.org
-https://naver.com
-여러개의 사이트들을 출발점으로 잡고 크롤링을 시작
-wikipedia.org -> Pages -> Hyperlinks
*웹 크롤러 vs 웹 스크레퍼
-웹 스크레핑: 웹 사이트에서 원하는 정보를 자동으로 추출 & 수집하는 프로그램
-엄밀히 말하자면 크롤링을 막 시작하는 사람은 크롤러를 만들수는 없다. 어렵기 때문.
-웹 스크레퍼를 연습하다 보면 웹 크롤링의 기본적인 매커니즘을 알 수 있다.
*아무 웹 사이트나 크롤링하면 될까?
-크롤링할 사이트의 주소에서 robots.txt를 찾아보자!
*Robots.txt
-크롤러가 해당 사이트의 데이터를 수집하는 것을 허용할지 금지할지 알려주는문서
-도메인 뒤에 robots.txt를 입력하면 된다.
-www.naver.com/robots.txt
-www.google.co.kr/robots.txt
*구글의 robots.txt 예시
-#Group 1
User-agent: Googlebot
Disallow: /nogooglebot/
-#Group 2
User-agent: *
Allow: /
-Sitemap: http://www.example.com/sitemap.xml
-#으로 시작하는 부분은 주석
-User-agent: 크롤링 봇의 이름
-Disallow: 허락하지 않는다
(/nogglebot/user/1, /nogglebot/something/long/long/url)
-*: 와일드 카드는 모든걸 포함한다, 선택한다는 뜻
-즉 #Group1은 Disallow(허락X), #Group2은 허락됨
-Sitemap: 크롤링 봇에게 도움을 줌. 참고 xml
*크롤링에 사용되는 모듈
-Axios + Cheerio
-Selenium, beautifulsoup, scrapy
-Puppeteer
*Axios + Cheerio
-HTTP 요청과 HTML DOM Parser 사용하기
-HTTP 요청을 보내야지만 정보를 획득한다 = Axios
-HTTP 데이터들을 파싱하는 작업 = Cheerio
*Axios
-우리가 원하는 페이지에 HTTP 요청을 보내기
-(https://www.npmjs.com/package/axios)
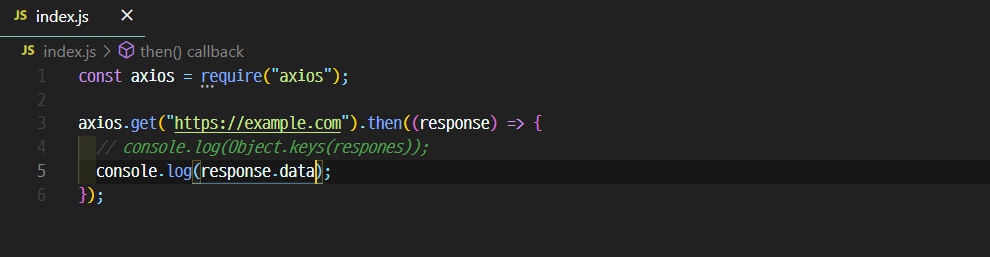
$node index.js
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">
body {
background-color: #f0f0f2;
margin: 0;
padding: 0;
font-family: -apple-system, system-ui, BlinkMacSystemFont, "Segoe UI", "Open Sans", "Helvetica Neue", Helvetica, Arial, sans-serif;
}
div {
width: 600px;
margin: 5em auto;
padding: 2em;
background-color: #fdfdff;
border-radius: 0.5em;
box-shadow: 2px 3px 7px 2px rgba(0,0,0,0.02);
}
a:link, a:visited {
color: #38488f;
text-decoration: none;
}
@media (max-width: 700px) {
div {
margin: 0 auto;
width: auto;
}
}
</style>
</head>
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div>
</body>
</html>
*Cheerio
-획득한 HTML 문서를 다루기 쉽게 파싱(parsing)
-(https://www.npmjs.com/package/cheerio)
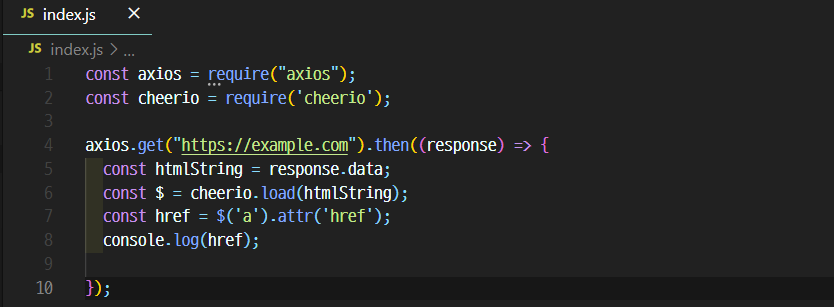
$node index.js
https://www.iana.org/domains/example

