
안녕하세요! NewCodes 개발자입니다.
NewCodes는 기술 블로그 큐레이팅 서비스입니다.
각 기업의 최신 기술 블로그를 모아서 한 번에 보여주고 있어요!
2025년 5월부터 저 혼자 군대에서 만들기 시작했어요!
현재에도 서버를 안정적으로 운영하려 노력하고 있습니다 😊
이번 글에서는 Spring AOP의 원리에 대해 알아보려 합니다.
NewCodes에서 로컬 캐시를 설정하면서 생긴 문제를 토대로 정리해볼게요!
캐시가 갱신되지 않는 문제 발생!
NewCodes는 홈 화면의 블로그 글 목록을 DB에서 조회합니다.
크롤링하기 전까지는 DB에 있는 데이터가 변하지 않으므로,
로컬 캐시를 도입해 DB 부하를 줄이고자 했습니다.
다만 새 글이 크롤링되면 기존 캐시를 삭제(evict)해야 최신 글을 보여줄 수 있겠죠.
문제의 코드
이를 구현하기 위해 Spring Boot를 쓰고 있던 NewCodes 서버에서는 아래와 같이 코드를 짰습니다.
// CrawlingService.java
private CrawlResult crawlAndSaveArticles(...) {
for (Article article : crawledArticles) {
saveArticleWithAnalysis(article, corporation, crawler);
}
}
@Transactional
@CacheEvict(value = "corporationArticles", allEntries = true) // 캐시 evict!
public void saveArticleWithAnalysis(...) {
crawlerArticleRepository.save(article);
}위 코드는 새로운 글이 저장될 때 곧바로 캐시를 evict해서 최신화된 글을 곧바로 볼 수 있게 합니다.
언뜻 보기에는 잘 동작할 것 같습니다. 테스트 코드를 작성해서 실행했을 때에도 잘 되는 것처럼 보였습니다. 하지만, 이는 실제로 캐시 evict가 되지 않았습니다.
문제를 발견했던 순간
서버를 재시작한 순간 이상한 점을 발견했습니다. 재시작을 하기 전, 가장 최신 글은 '1일 전'의 글이었습니다.
재시작 이후, 홈 화면에 들어가보니 새로운 글이 보였습니다. 그런데 이 글은 '7시간 전'에 발행된 글이었습니다.
이상한 게 느껴지시나요? 크롤링해서 최신 글이 있었다면 곧바로 evict가 되었을 겁니다. 그러면 7시간 전 발행 글은 재시작 전에도 보였어야 합니다!
재시작 이후 새로운 글 나타난 걸 보니 캐시가 evict되지 않고 stale(오래된) 캐시를 계속 리턴하고 있었다는 걸 짐작할 수 있습니다.
이러한 추측으로 서버 로그 확인 결과, 캐시를 evict 했다는 로그는 살펴볼 수 없었습니다. 추측이 확신이 되는 순간이었습니다.
문제의 원인
도대체 어떤 원인 때문에 캐시 evict가 되지 않았던 걸까요?
문제의 주 원인은 self-invocation(내부 호출)로 인해 AOP 적용이 안 됐다는 점입니다. 참고로 @CacheEvict는 Spring AOP 기반으로 동작합니다.
이를 이해하기 위해서 우선 Spring AOP에 대해 알아봅시다.
Spring AOP가 동작하는 원리
AOP 소개
AOP(Aspect-Oriented Programming)란 핵심로직과 부가로직(공통 관심사)를 분리하기 위한 하나의 패러다임입니다.
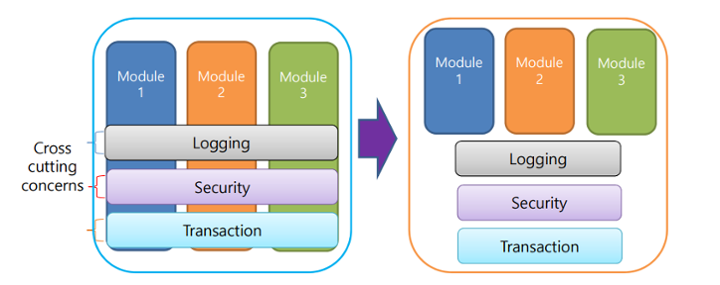
로깅, 트랜잭션, 예외 처리와 같은 부가 로직을 중복 없이 관리할 수 있습니다. 예를 들어, 트랜잭션은 여러 DB 관련 로직에서 쓰일 수 있습니다. 이를 간단히 @Transactional만 붙여도 트랜잭션이 실행되게 할 수 있죠.
AOP가 없었다면, 트랜잭션 코드는 아래처럼 작성해야 했을 겁니다.
@Service
@RequiredArgsConstructor
public class MemberService {
private final DataSource dataSource;
public void createMember(String name) {
Connection conn = null;
try {
conn = dataSource.getConnection();
conn.setAutoCommit(false); // 트랜잭션 시작
// 1. insert member
try (PreparedStatement ps = conn.prepareStatement(
"INSERT INTO member (name) VALUES (?)")) {
ps.setString(1, name);
ps.executeUpdate();
}
// 2. 다른 테이블에도 관련 작업
try (PreparedStatement ps = conn.prepareStatement(
"INSERT INTO log (message) VALUES (?)")) {
ps.setString(1, "회원 등록됨: " + name);
ps.executeUpdate();
}
conn.commit(); // 트랜잭션 커밋
} catch (Exception e) {
if (conn != null) conn.rollback(); // 롤백
throw new RuntimeException(e);
} finally {
if (conn != null) conn.close();
}
}
}DB에 접근하는 메서드를 작성할 때마다 매번 위와 같은 try & catch 문을 중복해서 작성해야 했을 겁니다.
또, 트랜잭션 처리 관련해서 수정해야 할 코드가 있다면 중복된 코드들을 모두 다 수정해야 하기에 관리하기도 까다롭습니다.
그래서 탄생한 게 AOP입니다. @Transactional 이거 하나만 붙임으로써 트랜잭션을 지원해주는 아주 편리한 기술이죠!
Spring AOP 원리
이 편리한 AOP는 어떻게 만들어졌을까요?
핵심은 proxy 기반으로 동작한다는 겁니다!
아래 그림을 차분히 살펴봅시다.
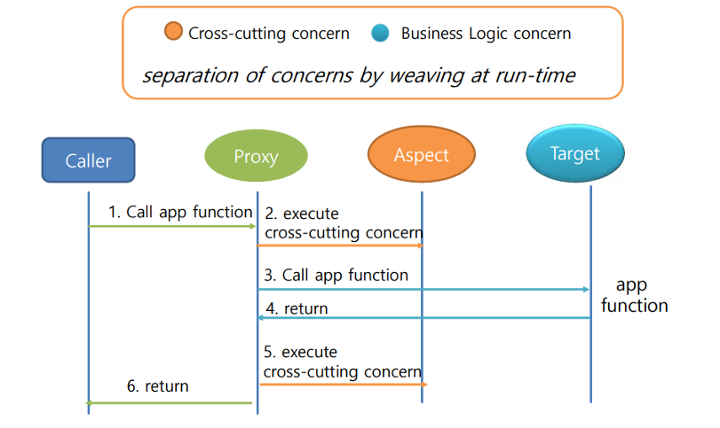
- Caller: 함수 호출자
- Proxy: 원래 객체를 감싸서, 횡단괌심사와 원래 객체의 메서드를 실행
- Aspect: 횡단 관심사를 하나로 모듈화한 것 (중복된 코드를 하나로)
- Target: 원래 객체. Aspect를 적용하는 곳
원래 객체를 감싸는 proxy를 만들고, 해당 proxy 안에서 aspect를 실행하는 방식입니다.
스프링 프레임워크에서는 bean 생성 시점에 원래 객체를 감싸는 proxy bean을 만들어 컨테이너에 등록합니다.
참고로 스프링은 다음 조건일 때 Proxy Bean을 생성합니다.
- 클래스에 AOP 어노테이션이 있을 때 (@Transactional, @Cacheable, @Async 등)
- AspectJ 표현식과 매칭되는 메서드가 있을 때
이후, 사용자가 컨테이너에서 해당 bean을 요청하면 실제로는 proxy bean을 주입받게 됩니다.
내부 호출이 AOP 적용이 안 되는 이유
다시 본론으로 돌아와 봅시다. 아래에서 AOP가 적용이 안 되었던 이유는 무엇일까요?
// CrawlingService.java
private CrawlResult crawlAndSaveArticles(...) {
for (Article article : crawledArticles) {
saveArticleWithAnalysis(article, corporation, crawler); // ← 여기!
}
}
@Transactional
@CacheEvict(value = "corporationArticles", allEntries = true)
public void saveArticleWithAnalysis(...) {
crawlerArticleRepository.save(article);
}앞서 언급한 정보를 토대로 추론해볼 수 있습니다.
아래 그림에서 Caller를 다시 유심히 살펴봅시다.
Caller는 proxy를 호출하고 있습니다. proxy를 호출하는 게 가능했던 이유는 bean을 주입받을 때 원래 bean이 아닌 proxy bean을 주입받았기에 가능한 일입니다.
그런데 위 코드를 보면 Caller는 proxy를 거칠 수가 없습니다. 내부에서 직접 메서드를 호출하고 있기에 proxy를 통해서가 아니라 다이렉트로 실행이 됩니다.
AOP는 프록시를 통해서 동작하고, 프록시는 외부에서 호출했을 때만 동작합니다. 그러므로 내부에서 호출하는 방식은 AOP가 적용이 안 됩니다.
외부 호출 (AOP 동작)
Controller → [Proxy] → Aspect 실행 → 실제 saveArticleWithAnalysis()내부 호출 (AOP 동작 안함)
같은 클래스 내부 → this.saveArticleWithAnalysis() → 직접 실행 (Proxy 우회)내부에서 메서드를 호출할 때는 this.saveArticleWithAnalysis()이 호출됩니다.
이 this는 Proxy가 아닌 실제 객체를 가리키므로, Proxy를 거치지 않습니다.
문제의 테스트 코드
저는 아래와 같이 테스트 코드를 작성했는데도 왜 위 코드가 문제가 됐는지 몰랐을까요?
@SpringBootTest
@AutoConfigureMockMvc
@Transactional
public class ArticleControllerCacheTest {
@Autowired
private CrawlingService crawlingSerivce;
@Test
void 게시글_추가시_캐시_삭제_후_preload() throws Exception {
// given - 캐시 생성
// when - 게시글 추가
// 문제: crawlAndSaveArticles를 통해서가 아니라 저장 메서드를 직접 호출!
crawlingSerivce.saveArticleWithAnalysis(newArticle, corp, defaultBlogCrawler);
// then - 캐시 삭제되어 다시 DB 조회
}
}그건 바로.. 실제 호출경로와는 다르게 호출했기 때문입니다. 실제 호출 경로는 crawlAndSaveArticles()를 통해서 호출해야 합니다.
하지만, 저장 메서드를 직접 호출함으로써 proxy를 통해서 호출하게 되었습니다. 그래서 테스트에서는 통과가 잘 되었던 것입니다.
테스트코드를 작성할 때 메서드 호출의 결과만 신경 썼었던 것 같습니다. 앞으로는 호출 경로를 포함해 최대한 실제 호출 흐름대로 테스트할 수 있도록 해야겠습니다.
해결방안
AOP 적용이 되게끔 하기 위해서 코드를 어떻게 수정해야 할까요?
1) 별도 클래스로 분리
가장 쉬운 방법은 별도의 클래스로 분리하는 것입니다. AOP가 적용된 메서드들을 다른 클래스로 옮겨 사용하면 됩니다.
아래 코드를 살펴보시죠!
// CrawlingService.java
@Service
@RequiredArgsConstructor
public class CrawlingService {
private final ArticlePersistenceService articlePersistenceService; // ← Proxy 객체
private CrawlResult crawlAndSaveArticles(...) {
for (Article article : crawledArticles) {
articlePersistenceService.saveArticleWithAnalysis(article, corporation, crawler);
}
}
}새로운 클래스 파일을 만들었습니다.
// 새 파일: ArticlePersistenceService.java
@Service
@RequiredArgsConstructor
public class ArticlePersistenceService {
private final CrawlerArticleRepository crawlerArticleRepository;
@Transactional
@CacheEvict(value = "corporationArticles", allEntries = true)
public void saveArticleWithAnalysis(...) throws IOException {
crawlerArticleRepository.save(article);
}
}crawling 로직을 주로 담당하는 서비스와 article CRUD를 담당하는 서비스를 나누었습니다.
이로써 articlePersistenceService에는 proxy bean이 주입되기에 AOP가 동작하게 됩니다!
역할에 따라 서비스 코드를 나눔으로써, 결합도를 낮추면서도 내부 호출 문제를 해결할 수 있는 게 큰 장점입니다. 그래서 이 해결 방안으로 선택해서 해결했습니다!
2) self injection
자기 자신의 proxy를 주입받아 사용하는 방법도 있습니다.
@Service
@RequiredArgsConstructor
@Slf4j
public class CrawlingService {
// 기존 필드들...
private final OpenaiService openaiService;
// 자기 자신의 프록시를 주입받음
private CrawlingService self;
@Autowired
public void setSelf(CrawlingService self) {
this.self = self;
}
private CrawlResult crawlAndSaveArticles(Corporation corporation, WebDriver driver) throws IOException {
// ...
for (Article article : crawledArticles) {
if (!crawlerArticleRepository.findFirstByLinkAndDeletedAtIsNull(article.getLink()).isPresent()) {
self.saveArticleWithAnalysis(article, corporation, crawler); // ← self 사용!
newArticles.add(article);
}
}
// ...
}
}AOP proxy에 대한 이해를 했다면 해당 코드가 어떻게 동작하는지 잘 이해가 되실 겁니다! proxy 객체를 주입 받은 self를 통해서 호출하면 AOP가 적용됩니다.
3) ApplicationContext에서.getBean()
컨테이너인 ApplicationContext에서 직접 getBean()을 통해 proxy를 가져오는 방법도 있습니다.
@Service
@RequiredArgsConstructor
@Slf4j
public class CrawlingService {
private final ApplicationContext applicationContext;
// 기타 필드들...
private final OpenaiService openaiService;
private final CrawlerArticleRepository crawlerArticleRepository;
private CrawlResult crawlAndSaveArticles(Corporation corporation, WebDriver driver) throws IOException {
// ...
CrawlingService proxy = applicationContext.getBean(CrawlingService.class);
for (Article article : crawledArticles) {
if (!crawlerArticleRepository.findFirstByLinkAndDeletedAtIsNull(article.getLink()).isPresent()) {
proxy.saveArticleWithAnalysis(article, corporation, crawler); // ← 프록시 사용!
newArticles.add(article);
}
}
// ...
}
}하지만 2번째, 3번째 방법은 단점이 존재합니다. 결합도가 높다보니 테스트 코드를 짜기엔 용이하지 않습니다. 임시방편으로는 괜찮은 해결방법일 순 있습니다.
내부 호출로 인한 AOP 적용이 안 되는 문제가 발생하다는 건, 단일 책임 원리(SRP)를 위반했다는 시그널일 수 있습니다. 그러니 대부분의 경우에는 1번 해결 방안을 사용하는 게 합리적입니다.
마무리
이번 글에서는 Spring AOP의 내부 동작 원리를 살펴보고,
내부 호출 시 AOP가 동작하지 않는 이유를 알아봤습니다.
핵심은 "Spring AOP는 Proxy 기반이며, Proxy는 외부에서 호출될 때만 동작한다"는 점입니다.
교훈
- 프레임워크의 핵심 원리를 잘 이해하고 있어야 한다.
- 테스트코드는 최대한 실제 호출과 비슷하게 짜야한다.
레퍼런스
https://docs.spring.io/spring-framework/reference/core/aop/introduction-defn.html
https://www.podo-dev.com/blogs/93
여기까지 해서 NewCodes에서 캐시를 도입하며 배웠던 Spring AOP에 대한 글을 마무리합니다.
기술 블로그 큐레이팅 서비스 NewCodes 많이 방문해주세요!!
북마크 하시고 시간 날 때 한 번씩 들어와서 글 읽어보시는 거 추천드려요 ㅎㅎ
최근에는 유튜브 모음까지 추가됐어요! 피드백도 언제든지 환영입니다!!
읽어주셔서 감사합니다!


좋은 트러블슈팅이에 대한 글이었던 것 같습니다! 잘보고 갑니다~