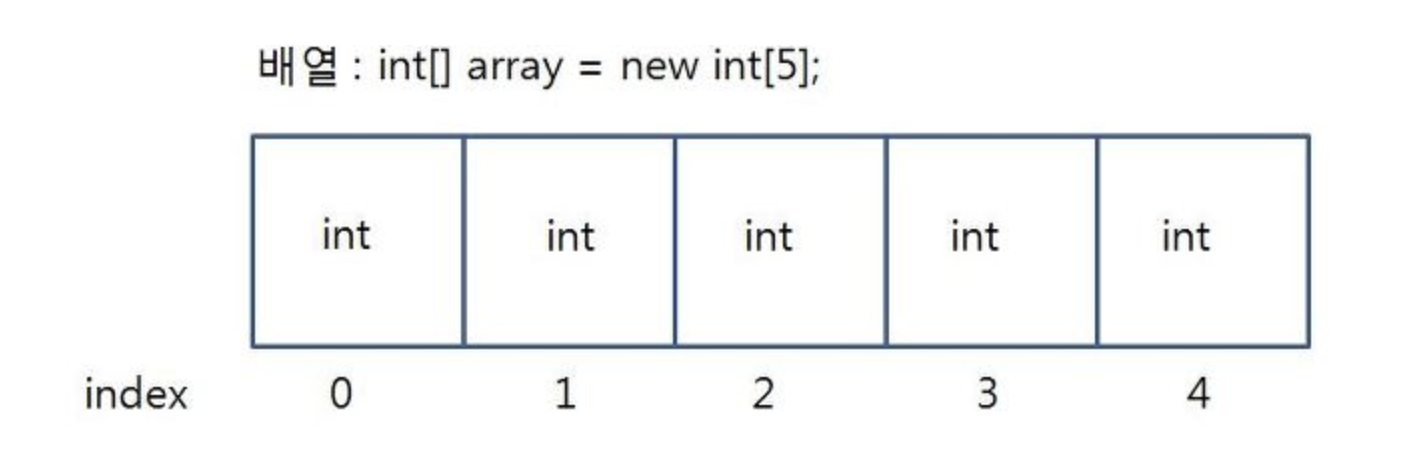
1. 배열(Array)
미리 할당된 크기에 연관된 데이터를 메모리 상에 연속적이고 순차적으로 저장하는 선형 자료구조
특징
- 저장공간이 고정되어 있음
- 순차적으로 저장
- 인덱스로 원소에 바로 접근할 수 있다.
- 마지막 원소가 아닌 원소를 제거하면 인덱스를 조정하는 shifting이 일어나 O(n)만큼의 시간이 소요된다.
=> lookup과 append가 빨라 원소를 빈번히 조회해야하는 경우에 유리하다.
=> 크기가 고정되어 있어 사용하지 않는 공간이 있을 경우 메모리 낭비가 발생할 수 있다.
=> 크기가 고정되어있어 크기를 변경하려면 새로운 배열을 만든 후 기존의 데이터를 옮겨줘야 한다.
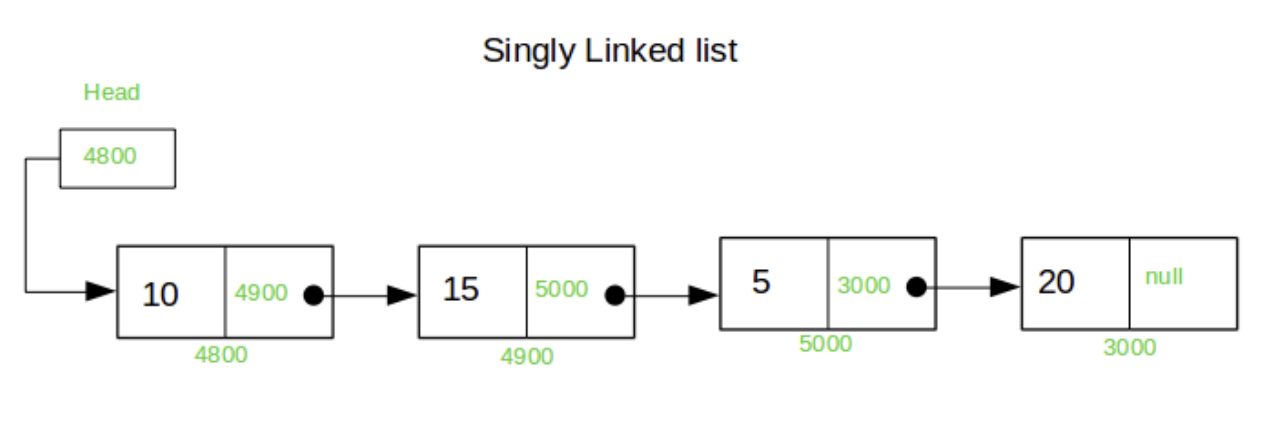
2. 연결 리스트(LinkedList)
노드라는 구조체에 데이터 값과 다음 노드의 주소를 저장하고 있는 자료구조. 기존 배열 자료구조의 삽입/삭제 비효율성을 해소하기 위해 등장하였다. 데이터는 물리적으로 비연속적으로 저장되어있지만 각 노드들이 다음 노드의 주소를 가리키고 있으므로 논리적으로는 연속적이다.
특징
- 데이터가 추가되는 시점에 메모리가 할당되기 때문에 메모리를 더 효율적으로 쓸 수 있다.
- 삽입/삭제 시 다음 노드의 주소만 바꿔주면 되기 때문에 데이터 이동에 시간을 들이지 않아 속도가 더 빠르다.
- 반면 데이터 조회 시 헤드부터 도달하고자하는 노드까지 순차적으로 접근해야하기 때문에 데이터 조회 속도는 느린 편이다. (랜덤 엑세스 불가능)
- Head 주소를 반드시 기억해야한다. 그렇지 않으면 탐색이나 삽입/삭제를 수행할 수 없다.
단점
(1) 실 연산 속도 저하
연결 리스트는 연산 시 더 빠른 효율을 낸다고는 하지만 실제 연산 속도를 측정해보면 배열이 오히려 더 빠르다고 한다. 그 이유는 연결 리스트의 데이터의 물리적인 저장 위치가 비연속적으로 분산되어 있기 때문이다.
메인 메모리에서 CPU로 데이터가 넘어오는 시간을 단축시키기 위해 이 둘 사이에 SRAM 기반의 캐시를 두어 CPU가 데이터를 기다리는 시간을 줄이는데, 배열의 경우 연속된 공간에 저장되어 있는 데이터를 한꺼번에 넘기면 되지만 연결 리스트는 메모리 곳곳에 저장된 데이터를 주소로 연결만 해놓은 것이기 때문에 캐시로 한꺼번에 데이터가 넘어가지 못해 결국 연산 속도가 느려진다.
(2) 주소 저장으로 인한 공간 낭비
다음 노드의 주소를 저장하고 있어야하는 연결리스트는, 배열보다 저장공간을 더 많이 쓰게된다. 정수형의 경우 연결 리스트는 배열보다 2배 더 큰 용량이 필요하다.
(3) 복잡한 연산으로 인한 오버헤드 발생
배열보다 연산이 더 복잡하여 연산 수행 시 더 많은 명령어가 필요하는 등, 알고리즘의 시간 복잡도 외에 추가적인 시간이 소모된다.
3. 배열 vs 연결 리스트
(1) 메모리 구조
- 배열: 데이터가 메모리에 연속적으로 저장된다.
- 연결 리스트: 메모리 상에서는 데이터가 연속적이지 않지만 각 노드가 다음 노드의 주소를 가지고 있으므로 논리적 연속성을 유지한다.
(2) 연산에 따른 시간복잡도
메모리 구조의 차이로 다음과 같이 시간복잡도가 달라진다.

-
조회
배열의 경우 데이터에 즉시 접근이 가능한 반면 연결 리스트는 순차접근만 가능하기 때문에 배열의 데이터 조회 속도가 더 빠르다. -
삽입/삭제
배열의 경우 맨 마지막 위치에 데이터를 추가/삭제하는 경우 시간복잡도가 O(1)이지만 그 외에는 인덱스 조정을 위해 데이터 shifting이 일어나 O(n)의 시간이 걸린다.
연결 리스트의 경우 삽입/삭제 시 다음 노드의 주소 값만 바꿔주면 되기 때문에 O(1)의 시간이 걸리지만 추가/삭제하려는 인덱스에 도달하기까지의 시간이 걸리기 때문에 실질적으로 O(n)의 시간이 걸린다고 할 수 있다.
(3) 메모리
-
메모리 낭비
배열은 선언 시 고정된 크기를 할당하기 때문에 데이터가 저장되고 있지 않더라도 공간을 차지하게 되어 메모리 낭비가 발생할 수 있다. 반면 연결 리스트는 런타임 중 크기를 늘리거나 줄일 수 있기 때문에 필요한 만큼만 메모리를 할당하여 낭비가 발생하지 않는다. -
메모리 할당 시점
배열의 경우 컴파일 단계에서 메모리 할당이 일어나며(정적 메모리 할당) 연결 리스트는 런타임 중 노드가 추가되는 시점에 메모리 할당이 일어난다. (동적 메모리 할당) -
메모리 할당 영역
배열은 데이터 메모리 영역에 할당되며 연결리스트는 힙 영역에 할당된다. 다만 배열이 정적 또는 글로벌 변수가 아닌 로컬 변수로 선언이 된 경우에는 스택 영역에 할당 될 수 있다.
참고
리스트 (3) - 연결리스트 (Linked List)
개발남노씨
