Hash Table이란?
효율적인 탐색을 위한 자료구조로써 key-value 쌍의 데이터를 입력받아 해시 함수에 key값을 입력으로 넣어 얻은 해시값을 데이터의 위치로하여 데이터를 저장한다.
특징
- 데이터 저장, 삭제, 탐색 시 시간 복잡도는
O(1)이다. - 충돌 발생 시 최악의 경우
O(n)의 시간복잡도를 갖는다. - 데이터가 저장되기 전에 미리 key, value 값을 저장할 저장 공간을 확보해야하기 때문에 공간 효율성은 떨어진다. 따라서 확보해놓은 공간이 부족하거나 저장공간이 중간중간 비어있는 경우가 생길 수 있다.
직접 주소화 테이블 (Direct Address Table)
가장 간단한 형태의 해시테이블로, key값으로 k를 갖는 원소는 index k에 저장하는 테이블이다. 예를 들어 k=3일 때, 인덱스 3위치에 데이터를 저장한다.
단점
- 최대 키 값에 대해 알고 있어야 한다.
- 불필요한 공간 낭비가 발생할 수 있다.
- key가 다양한 자료형을 가질 수 없다.
해시 함수를 이용한 해시 테이블
hash function h를 이용해서 (key, value)를 index h(k)에 저장한다. 해시 테이블은 탐색, 삽입, 삭제에 대해 O(1)의 매우 우수한 성능을 나타내지만 key값이 겹치는 충돌(Collison)이 발생하는 경우 탐색, 삭제 연산이 최악의 O(n) 시간복잡도를 갖는다.
Collision
서로 다른 키의 해시값이 같아 충돌하는 경우를 말한다. 중복되는 키는 없지만 해시 값이 중복될 수 가 있는데 이를 collision이 발생했다고 한다. key의 개수를 k, 테이블의 크기를 n이라고 할 때 해시 테이블 크기 대비 키의 개수는 k/n으로 나타내며 이를 적재율이라고 한다. 적재율이 1을 넘어설 때 충돌이 발생하게 되는데, 충돌 발생 시 성능이 저하되기에 해시함수 설계 시 해시값의 중복이 일어나지 않도록 설계 해야한다.
그럼에도 불구하고 충돌이 일어나는 경우 분리 연결법 (seperate chaning), 개방 주소법(open addressing) 등의 방법을 사용할 수 있다.
분리 연결법
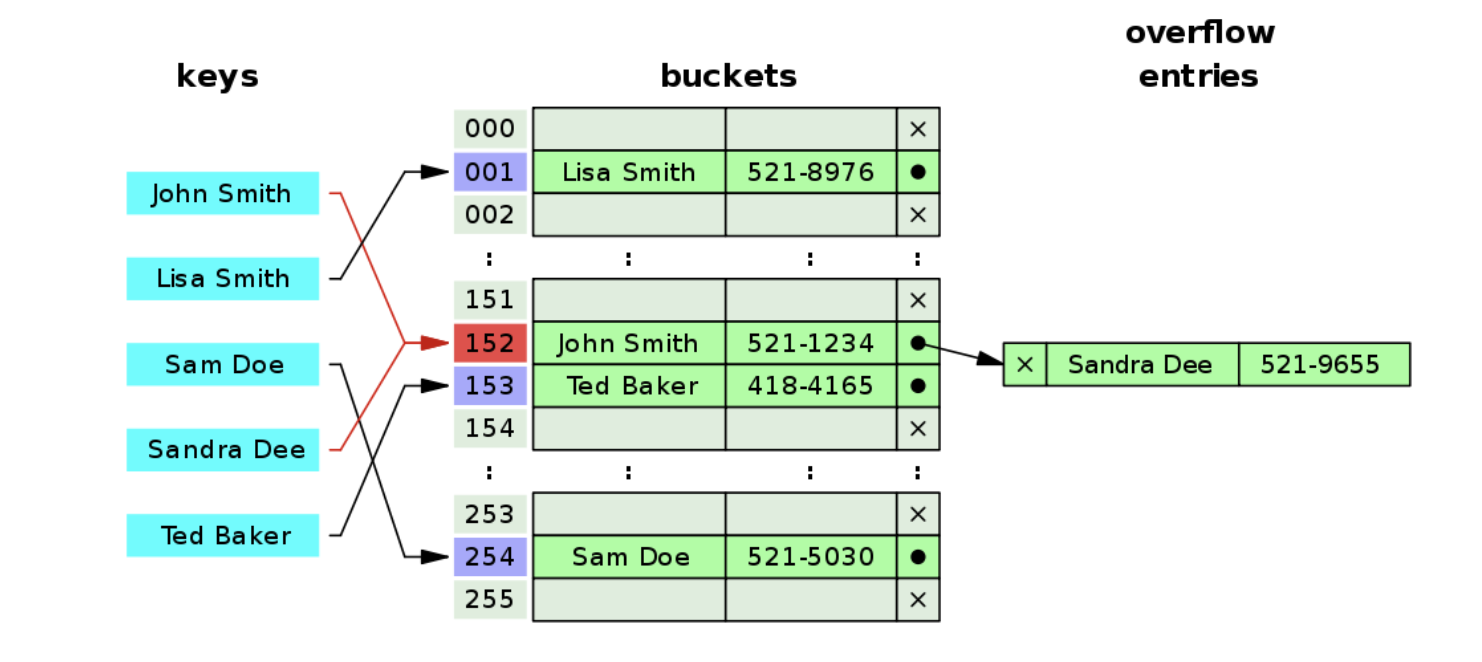
충돌이 발생한 경우 동일한 버킷에 저장하되 연결 리스트 형태로 저장하는 방법이다. 위 예시 사진을 보면 John Smith와 Sandra Dee의 해시값이 152로 겹쳐 연결 리스트 형태로 다음 위치의 주소를 가르키도록 처리했다.
개방 주소법
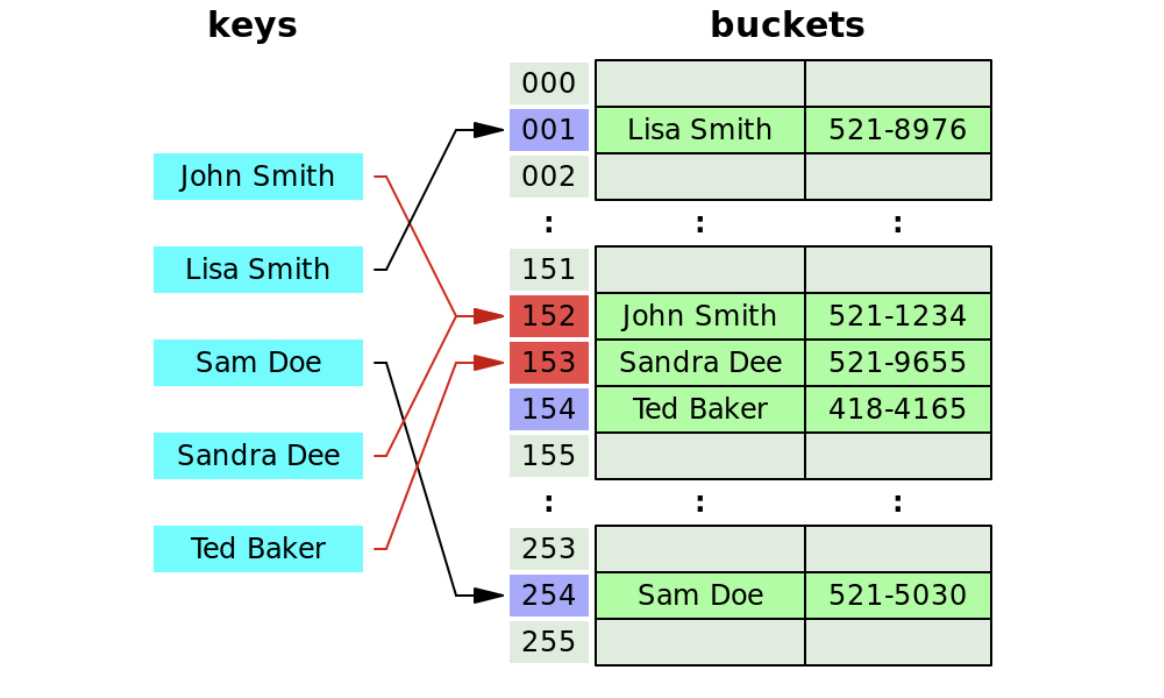
동일한 주소에 데이터가 있을 경우 다른 주소의 저장공간을 쓰는 방법이다. 해시 함수를 통해 얻은 해시값이 겹칠 경우 다음 인덱스로 이동하여 비어있는 자리를 탐사하고 빈 공간을 발견한 경우 해당 인덱스에 저장한다. 위 경우에는 해시값이 152로 겹쳐 153인덱스에 저장하고 있다.
데이터 삭제 시에는 탐색을 통해 해당 값을 찾고 그 자리에 삭제 표시를 한다. 또한 데이터 탐색 시에는 해시값의 인덱스부터 시작하여 탐사를 시작하며 삭제표시가 있는 곳은 지나가며 값을 찾는다.
BST (Binary Search Tree)란?
정렬된 이진 트리로, 어느 노드든 해당 노드의 왼쪽 서브트리에는 해당 노드보다 작은 값을 가진 노드들이 있고 오른쪽 서브트리에는 그 노드보다 큰 값의 노드로만 이루어진 트리이다.
특징
- 루트 노드의 값보다 작은 값은 왼쪽 서브트리에, 큰 값은 오른쪽 서브트리에 있다.
- 서브트리에 대해서도 위의 규칙이 재귀적으로 적용된다.
- 검색, 삽입, 삭제의 시간 복잡도는
O(log n)이다. - 최소값, 최댓값을 쉽게 찾을 수 있다.
- 최악의 경우는 한쪽으로만 치우친 트리인 경우이며 이때의 시간 복잡도는
O(n)이다. 한 노드에 대해 값이 큰지 작은지 확인하고 나면 탐색할 다음 노드들의 후보군이 줄어야하는데 그렇지 않고 모든 노드에 대해서 확인을 해야하기 때문.
=> AVL 트리로 개선 가능
삭제 연산
case1: 리프노드인 경우
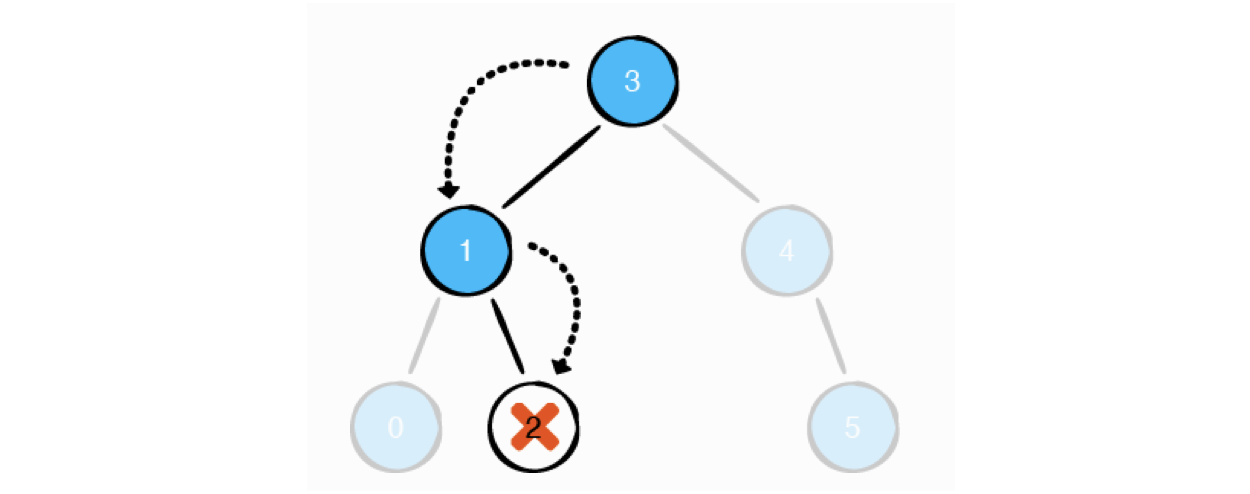
마지막 노드를 삭제시켜주면 된다.
case2: 삭제 대상 노드가 한 개의 자식 노드를 가진 경우
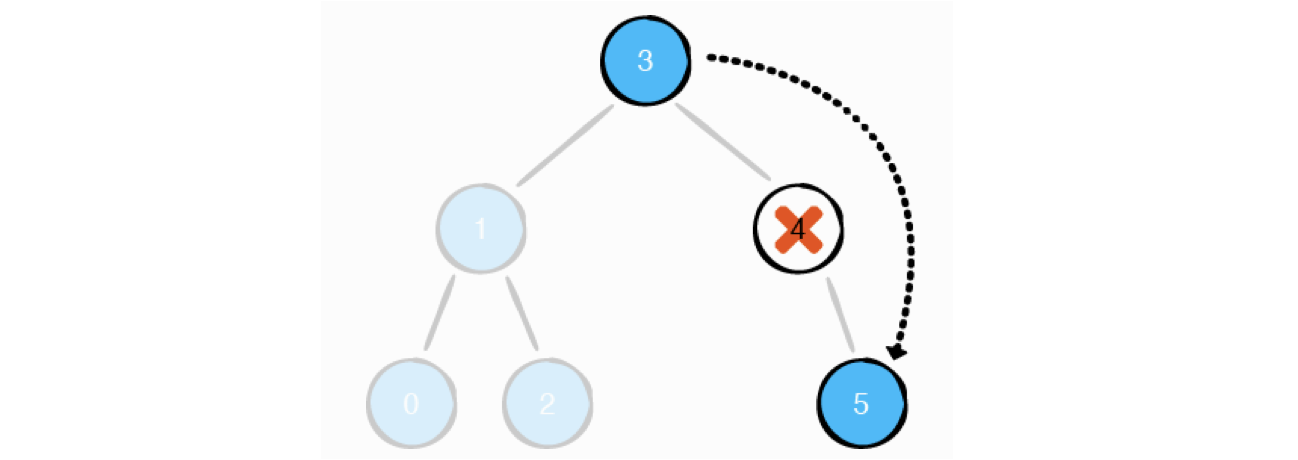
해당 노드를 삭제 후 자식 노드를 상위 노드와 연결 시켜주어야 한다.
case3: 삭제 대상 노드가 두 개의 자식 노드를 가진 경우
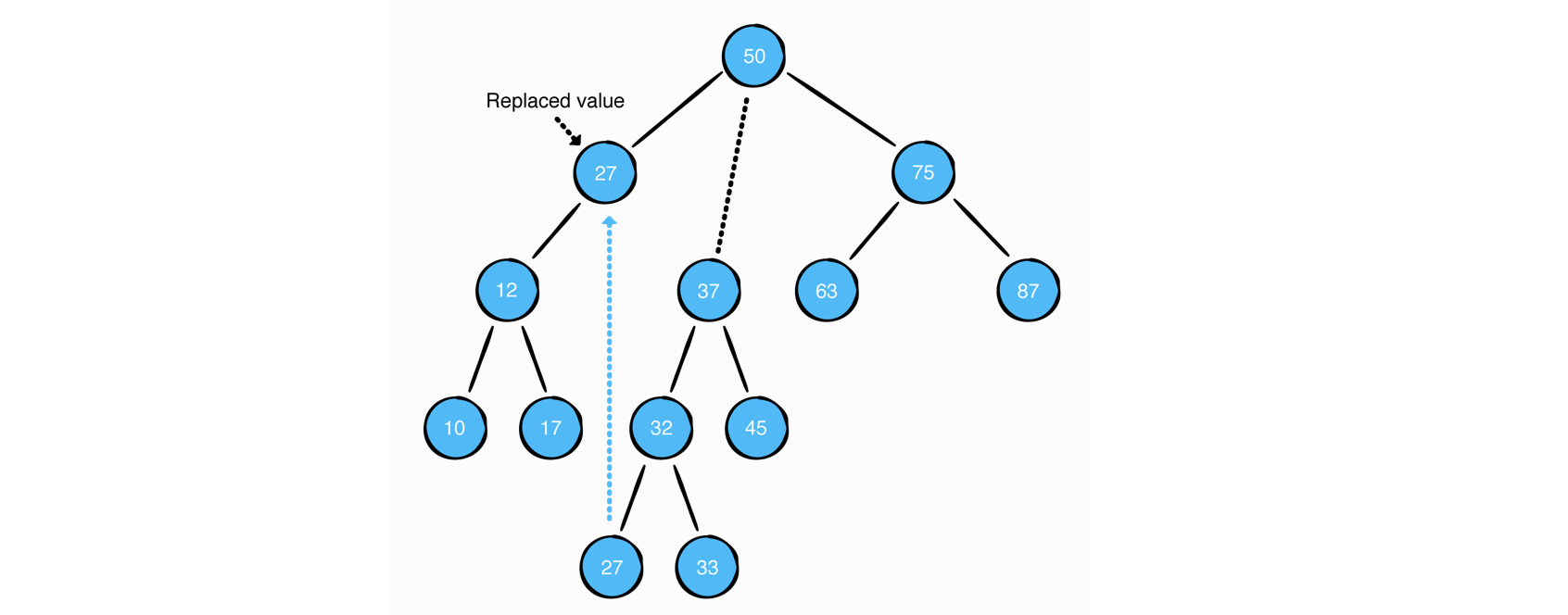
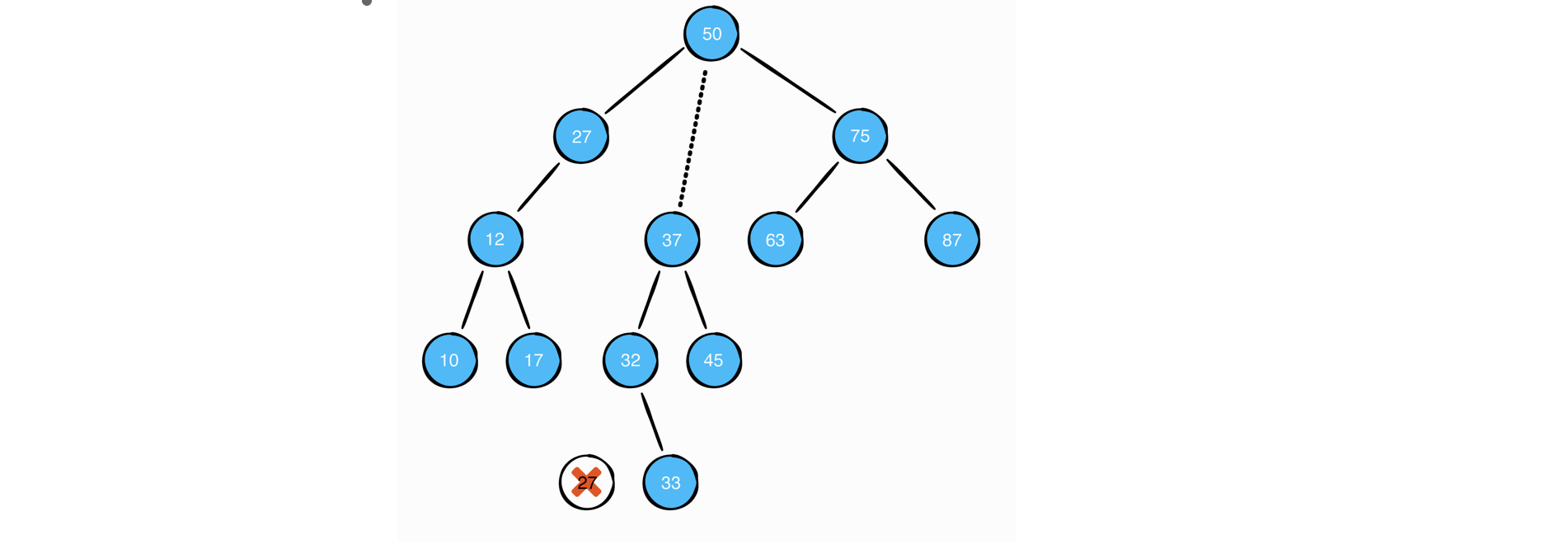
해당 노드의 오른쪽 서브트리에서 가장 작은 값과 교체 시킨다. 이렇게 하면 교체시킨 노드의 왼쪽 서브트리의 노드들은 항상 해당 값보다 작고, 오른쪽 서브트리의 노드들은 해당 값보다 항상 크므로, 이진탐색트리의 조건이 유지된다.
참고
https://baeharam.netlify.app/posts/data%20structure/hash-table
