Redis
Key-Value 형태로 저장되는 NoSQL로, 인메모리 데이터베이스이다. 디스크가 아닌 컴퓨터의 주 메모리에 데이터를 저장하기 때문에 보다 빠른 데이터 검색이 가능하다.
특징
1. 다양한 자료구조 지원
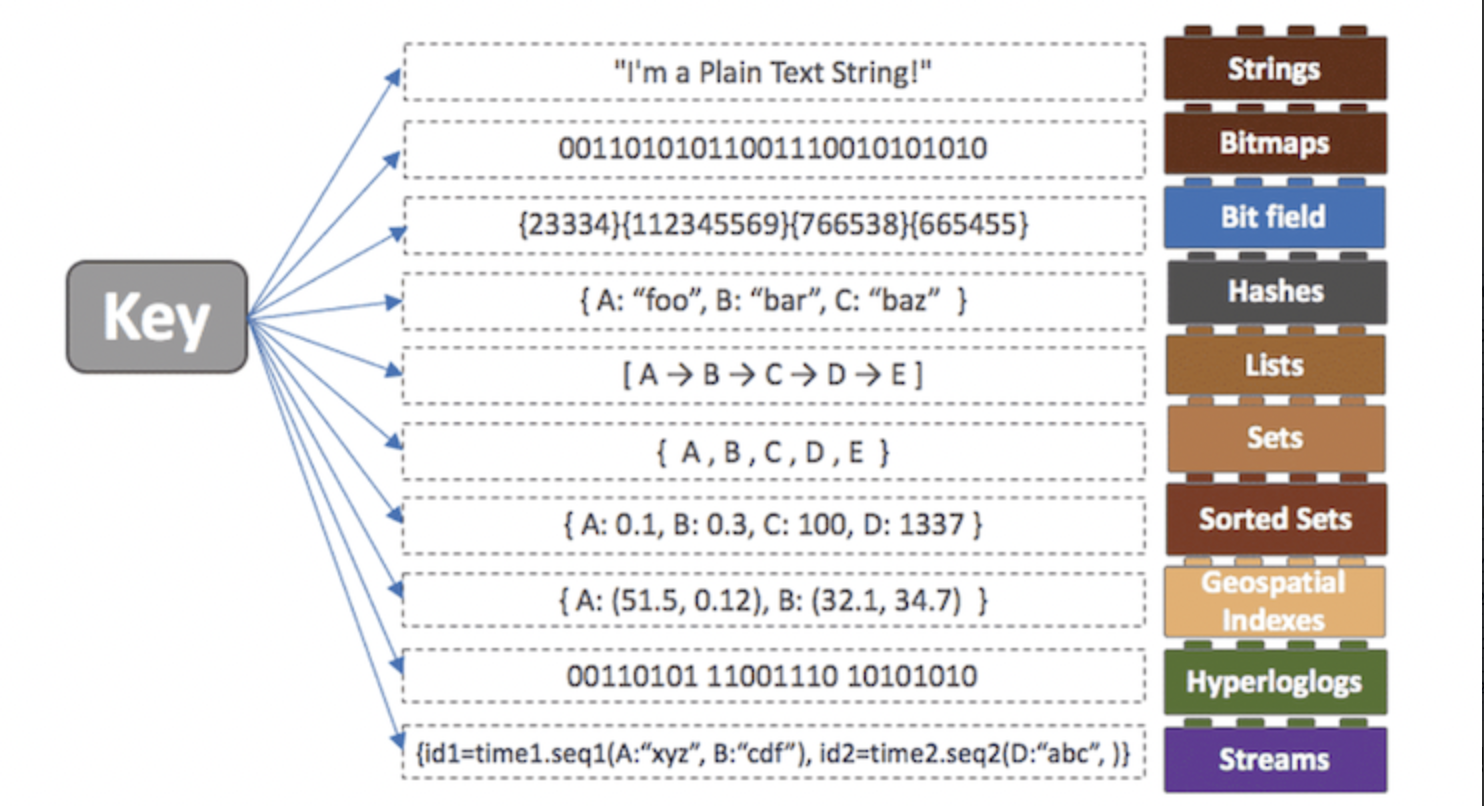
- String, Set, Sorted Set, Hash, List 등의 다양한 자료구조를 지원하여 개발 편의성이 좋아지고 난이도는 낮아진다.
2. 지속성 지원
- 디스크 없이 주 메모리에만 저장하는
Memcached와는 달리 영속성 지원을 위해 데이터를 디스크에 저장할 수 있다. 따라서 서버가 내려가더라도 디스크에 저장된 데이터를 읽어서 메모리에 로딩한다. 디스크에 저장하는 방식은 순간적으로 메모리에 저장된 데이터 전체를 디스크에 저장하는 RDB(Snapshotting) 방식과 Redis의 Write/Update 연산을 모두 log파일에 기록하는 형태인 AOF(Append On File) 방식이 있다.
3. 읽기 성능 증대를 위한 서버 측 복제 지원
- Redis를 사용하는 서버가 충돌할 경우 전체 데이터베이스의 초기본을 복사받는 마스터/슬레이브 복제를 지원한다.
장점
- 데이터 입력/삭제가 MySQL 보다 10배 빠르다.
- 메모리를 활용하면서 데이터를 영속적으로 보존할 수 있다.
- 명시적으로 삭제 또는 expires를 설정하지 않으면 데이터가 삭제되지 않는다.
- 스냅샷 기능을 제공하여 메모리 내용을
.rdb파일로 저장하여 특정 시점으로 복구할 수 있다.
- Master-Slave 형태로 여러개의 서버를 띄울 수 있어, 데이터 손실 위험성을 줄일 수 있다.
Master-Slave 구조
Redis 에서는 실행 중인 노드가 다운되더라도 실시간으로 다른 노드에 데이터를 복사하여 계속 서비스되도록 할 수 있다. 이러한 replication은 Master-Slave 구조로 구성할 수 있는데, 실제 운영 서비스에서는 노드가 물리적으로 다른 곳에 위치해있는 것을 권장한다.
Slave 노드가 실행될 서버의 redis.conf 파일을 아래와 같이 설정해주면 slave 노드를 구성할 수 있다.
# redis.conf
replicaof 127.0.0.1 7000 # replicaof <master ip> <master port>
repl-ping-replica-period 10
repl-timeout 60Master 노드에서 데이터를 추가하는 경우 Slave노드에서도 해당 데이터를 조회할 수 있으며, Slave 노드는 Read-Only 이기 때문에 데이터 생성 명령어를 실행할 경우 오류가 발생한다.
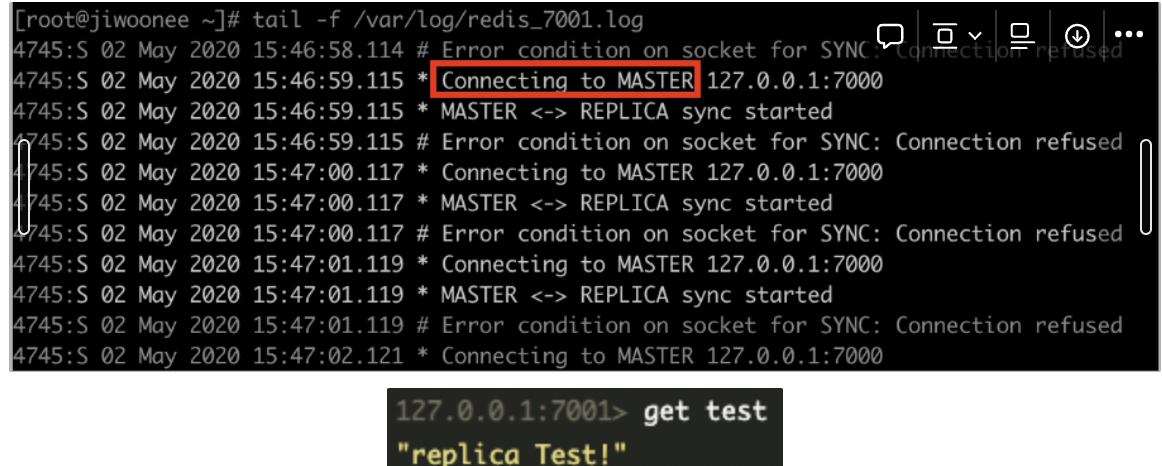
- Master 노드가 다운되었을 경우의 Slave 노드의 로그
-> Master 노드에 sync를 보내 연결을 시도. slave 노드에서는 데이터를 여전히 조회할 수 있음.
- Master 노드가 다시 살아났을 경우의 Slave 노드의 로그
-> Master 노드에 연결되어 복제를 계속함
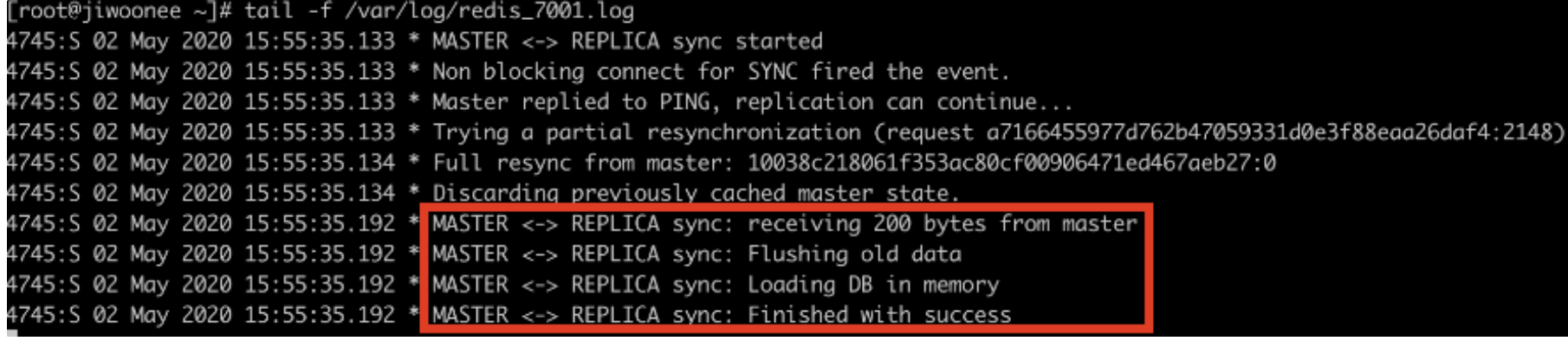
이렇게 Master-Slave 노드의 구조로 서비스 안정성을 높일 수 있다. 하지만 Slave 노드는 읽기 동작만 가능하기 때문에 제대로된 서비스를 보장하기 어렵다. 이런 상황을 위해 Slave 노드가 여러 개인 경우 그 중 하나를 Master 노드로 승격시킬 수 있다.
지속성
(1) RDB
주기적 스냅 방식인 snapshot 방식과 유사하며 쓰기 작업은 바이너리파일로 저장된다. 이 방식은 백업에 적합하며 하나의 rdb 파일을 Amazon S3와 같은 데이터 센터에 전송할 수 있다. 수동 또는 지정된 시간마다 실행시킬 수 있으며 데이터 손실이 발생할 때 복구된다. AOF보다 파일 크기가 작지만 로딩 속도는 더 빠르다.
생성 및 로드는 save , bgsave 명령어를 사용한다.
save (동기화)
메인 프로세스가 RDB파일이 생성을 수행하며 파일 쓰기 작업동안에는 클라이언트의 명령을 수행할 수 없다.
예시)
# redis.conf
save 600 10 # 600초 동안 10번 이상 키 변경 발생 시 데이터베이스에 백업bgsave (비동기)
하위 프로세스가 백그라운드로 RDB 파일 생성을 실행하므로 RDB파일 쓰기 작업 중에도 레디스 서버는 클라이언트의 명령을 처리할 수 있다.
캐시 용도로만 쓸 경우 save 설정은 "" 로 해주는 것이 권장된다. stop-write-on-bgsave-error 를 비활성화 해주어야 한다. (yes인 경우 RDB파일 저장에 실패 시 Redis에 쓰기 작업을 할 수 없음)
(2) AOF
서버에서 실행되는 모든 명령을 추적하고 서버가 재부팅된 후 별도의 명령어 없이 로그를 기반으로 데이터베이스를 재구성한다. 입력/수정/삭제 명령이 실행될 때 기록된다. 로그가 쌓이는 것이기 때문에 파일 크기는 계속 커지며 파일 크기 제한에 따라 기록이 중단될 수 있고, 레디스 서버 시작 시 로드가 지연될 수 있다. 이 경우 파일 크기가 100 퍼센트 이상 커질 시 주기적으로 rewrite하여 크기를 줄여야한다.
보통 AOF를 기본으로, RDB를 부차적으로 사용하며 AOF 는 everysec마다 실행, rewrite를 사용한다. (다만 캐시용으로만 쓰이는 경우 appendonly는 비활성화 하는 것이 좋음) Master 노드 자동 재시작 시 AOF 없이 RDB 파일만 있는 경우 slave 노드도 마스터와 같이 몇분 전 RDB 파일의 데이터들을 받게 된다.
# redis.conf
appendonly yes # AOF 활성화. 해당 설정이 yes이면 aof 파일을 먼저 읽고 no이면 rdb 파일을 먼저 읽음. 해당 값이 yes이고 aof 파일이 없는 경우 rdb 파일을 읽지 않음.
appendfilename "appendonly.aof" # 파일명 지정. 경로는 지정 불가
appendfsync # AOF 기록 시점
auto-aof-rewrite-percentage 100 # 파일 크기가 100프로 이상 커지면 rewrite 자동실행
auto-aof-rewrite-min-size 64mb # aof파일 크기가 64이하이면 rewrite 실행하지 않음❗️활용 - 캐싱
캐시 저장 방식 지침
- 자주 사용되며 변경 빈도가 낮은 데이터를 선정
- In-memory DB인 만큼 언제든 데이터가 유실될 가능성이 있다는 것을 염두 (디스크에 저장함으로써 지속성을 유지할 수 있지만 캐싱을 위한 성능으로는 적합하지 않음. Replication을 할 경우 성능에 영향이 가지 않도록 어느정도 기간을 설정해야함으로 데이터 정합성도 깨질 우려 있음)
캐시 제거 방식 지침
- 캐시 데이터는 영구 저장소(e.g., 데이터베이스)의 데이터와 반드시 동기화 되어야 함 → 캐시 구성시 만료 정책 필요
- 기간이 만료되면 캐시에서 삭제되고 영구 저장소에서 데이터를 읽어와 새로 저장
- 만료 주기가 너무 짧으면 성능 저하, 너무 길면 데이터 정합성 문제 또는 메모리 부족 문제가 발생할 수 있음
- 대규모 트래픽 환경에서 TTL이 너무 짧으면 cache stampede 현상이 일어날 수 있음. 여러 환경에서 특정 키를 조회하려는 순간 key의 만료시간이 지났다면 영구 저장소에 한꺼번에 데이터 조회 요청을 하며 duplicated read가 발생하게 되고, 조회한 데이터를 또 캐싱하는 duplicated write이 발생 → 성능 저하 및 요청 병목으로 서비스 장애로 이어질 가능성
캐시 공유 방식 지침
- 캐시는 여러 인스턴스에서 공유하도록 설계되기 때문에 한 인스턴스가 수정한 데이터를 다른 인스턴스의 변경으로 덮어씌우지 않도록 해야함 → 데이터 정합성을 위한 확인 절차 필요
- 캐시된 데이터 업데이트 직전에 데이터가 조회된 이후로 수정되지 않았는지 확인하거나 업데이트 전 Lock을 걸어 정합성을 유지
- Lock을 거는 방식의 경우 조회 업무를 처리하는 프로세스에 대기열이 생기는 단점이 있음. 따라서 데이터 크기가 작아 빠르게 수정 가능하거나 빈번하게 수정이 일어나는 경우 적합
- 업데이트 전 변경 여부를 확인하는 방식의 경우 업데이트가 드물고 충돌이 발생하지 않는 경우에 적합. 변경 여부 확인 후 변경되지 않았다면 즉시 수정, 변경 되었다면 변경 여부를 애플리케이션에서 결정하도록 해야함
캐시 가용성 방식 지침
- 캐싱은 데이터 조회 성능을 확보하기 위함이므로 데이터 영속성은 영구 저장소에 위임하는 것이 바람직
- 또한 캐시 서버가 다운되거나 서비스가 불가능할 때도 전체 서비스에는 문제가 없어야 함
캐싱 전략
(1) 지연로딩 (Lazy Loading)
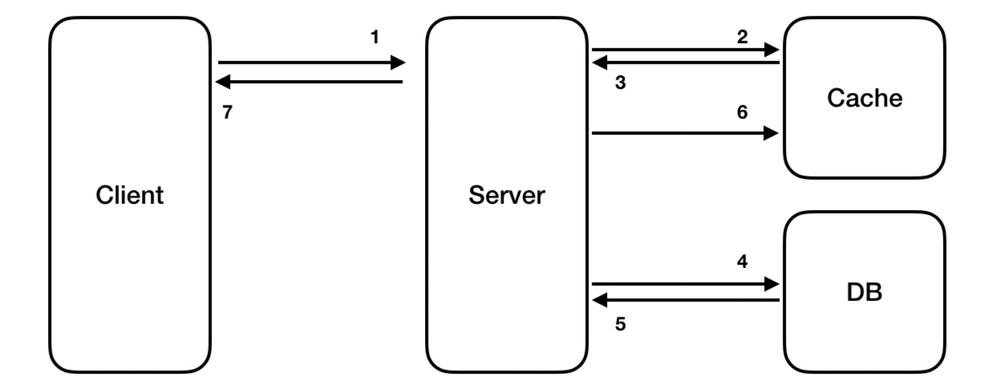
- 데이터 요청이 들어온 경우 캐시를 우선 확인하여 데이터가 있으면 반환하고 없으면 DB나 API에 접근하여 데이터를 가져와 캐싱하는 방법
- 요청받은 데이터만 캐시에 저장하므로 효율성이 증대되며 캐싱되지 않은 데이터를 DB에서 가져오므로 cache miss에 치명적이지 않다.
- 캐시에 없는 데이터 조회 시 (1) 캐시 조회 (2) DB 조회 (3) 캐시에 저장 이 세 단계를 거치게 되므로 캐시 미스가 많이 발생할 수록 지연이 발생한다.
- 초기 데이터는 항상 캐시 미스가 발생한다는 점을 고려하여 미리 DB의 데이터를 캐시에 넣어주는 cache warming 작업이 필요하다.
- 읽기 작업이 많은 경우 적합
(2) Read Through
- 데이터 조회 시 캐시만 조회하며 캐시 미스가 발생한 경우 DB에서 데이터를 가져와 캐싱. 지연로딩 방식과 비슷하지만 지연로딩은 캐시 미스 시 앱(서버)가 직접 DB를 조회하는 반면 Read Through는 캐시가 DB를 조회한다.
- 초기 데이터는 항상 캐시 미스가 발생하므로 cache warming 작업을 해주거나 DB에 데이터 저장 시 캐시에도 쿼리를 수행하도록 설정할 수 있다.
(3) Write Through
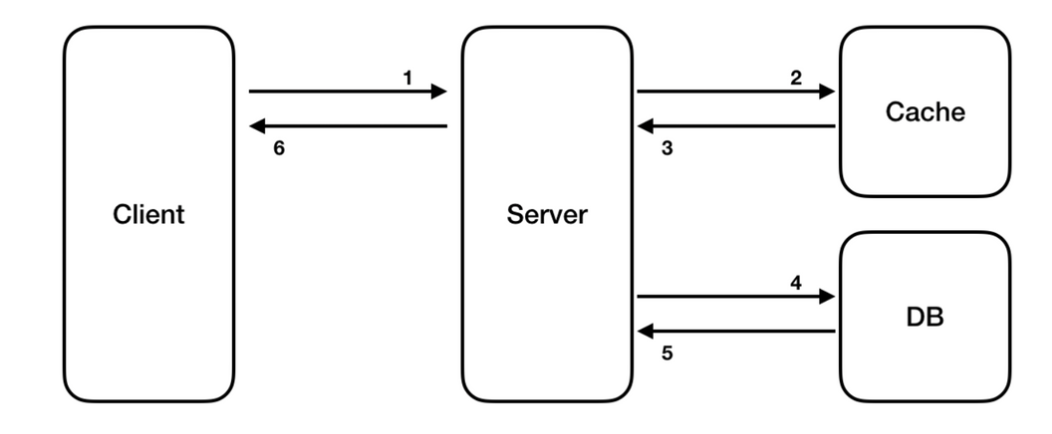
- 데이터 생성/수정 시 캐시와 DB에 모두 쓰기 작업을 한다.
- 데이터가 항상 최신 상태를 유지할 수 있다.
- 데이터 생성/수정 시 항상 캐시와 DB를 모두 히트하게 되므로 성능이 저하되고 사용되지 않는 데이터가 캐싱되므로 리소스 낭비가 발생한다.
- 새로운 노드가 발생할 경우 데이터를 찾지 못할 수 있다. (데이터가 최신 상태이므로 읽기 작업에서는 무조건 cache만 읽기 때문.)
- 데이터가 유실되면 안되는 경우에 적합
(4) Write Around
- 데이터 생성/수정 요청이 들어오면 DB에만 저장하고 데이터가 읽힐 때에만 캐싱하는 전략
- Lazy Loading 방식과 잘 쓰이는 쓰기 전략
- Write Through 보다 속도가 빠르지만 데이터 저장 시 DB에만 저장하기 때문에 데이터 정합성 문제 발생
- 데이터가 한번 쓰여지면 잘 읽히지 않는 실시간 로그 및 실시간 채팅의 경우 우수한 성능을 보임
- 데이터 최신성을 보장하기 위해서는 캐시 entry를 무효화하거나 더 적절한 쓰기 전략을 적용하는 것이 좋음
(5) Write Back
- 데이터 Insert 작업이 많이 일어나는 경우 생성될 데이터를 캐시에만 저장해놓았다가 DB에 한꺼번에 쿼리를 실행하여 배치하기 위한 전략
- 쓰기 작업이 빈번한 경우에 적합
- 캐시를 해두었다가 한꺼번에 디스크에 저장하므로 데이터 유실 위험성이 있음
- Read Through 방식과 결합하여 가장 최근에 업데이트 또는 조회된 데이터를 항상 캐시에서 활용할 수 있도록 하는 혼합형 워크로드에 적합
TTL(Time-To-Live)
- 각 전략에 TTL을 적용하면 이점을 더 극대화할 수 있음.
- Key의 만료시간을 설정하여 만료시간이 지나면 자동으로 삭제
- Lazy Loading: 만료시간이 되면 데이터가 삭제되어 캐시 미스 발생 → 데이터 최신 상태 유지 가능
- Write Through: 업데이트 되지 않은 데이터를 자동 삭제하여 메모리 이득을 볼 수 있음
redis.conf 권장 설정 및 속성 값 이해
redis.conf 권장설정
[Redis] redis.conf 설정 파일
참고
인메모리 데이터베이스란 무엇입니까?
레디스(Redis)란 무엇인가?
[Redis] AOF vs RDB - Redis 메모리 관리 방식 비교
해피쿠 블로그 - [Redis] master-slave(replication) 구축하기
[REDIS] 📚 캐시(Cache) 설계 전략 지침 총정리
레디스(Redis)의 다양한 활용 사례
