PACELC 이론
PACELC 이론은 CAP 이론을 보완하기 위해 등장한 이론입니다. CAP 이론에서 CA를 선택하려면 네트워크 장애가 전혀 없다는 전제가 필요한데, 이는 분산 환경에서는 불가능합니다. 따라서 파티션 허용성은 필수적으로 전제되어야 하며, 결국 CP나 AP 중 하나를 선택해야 합니다. 그런데 이는 장애 상황만 고려한 것이므로, 정상적인 상황도 함께 고려한 이론이 필요했습니다.
PACELC 이론은 PAC와 ELC로 구성됩니다. PAC는 CAP 이론의 약자와 동일하며, 순서를 바꾼 이유는 파티션 허용성 상황에서 가용성을 선택할지 일관성을 선택할지를 강조하기 위해서입니다. 이는 CAP 이론에서 CP나 AP를 선택하는 것과 같은 의미입니다.
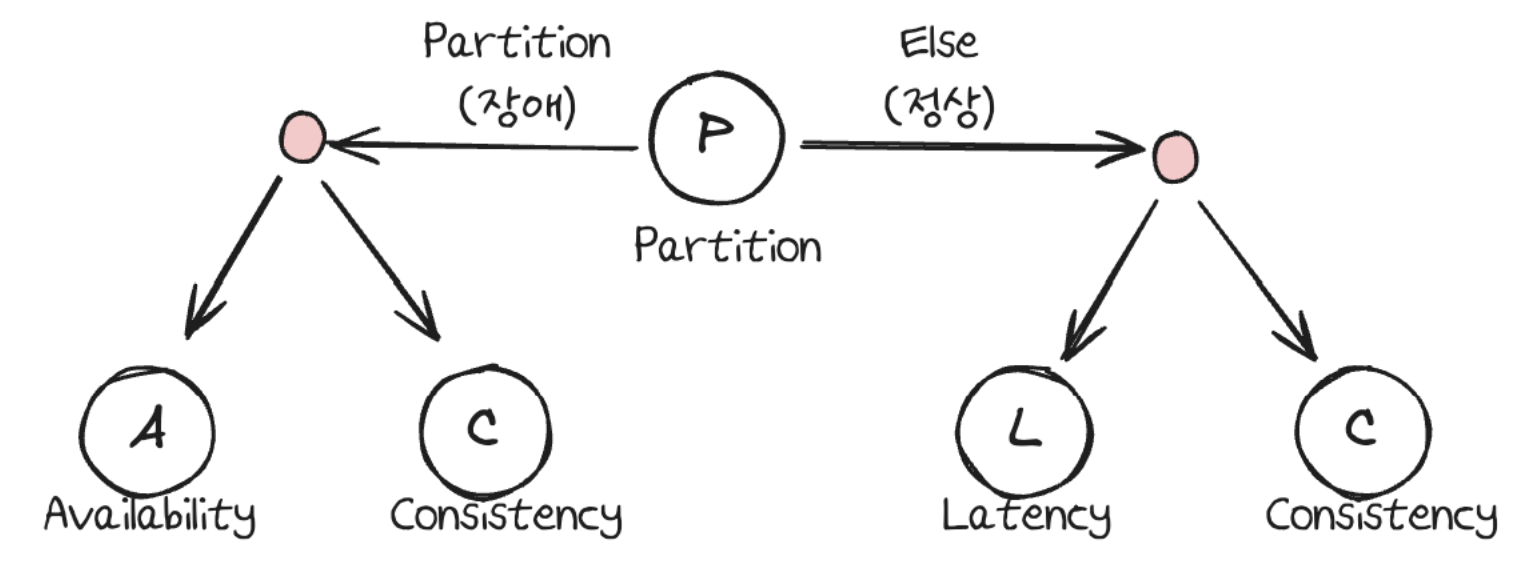
PAC는 네트워크가 분할된 상황을 다루지만, 실제로 분할된 상황은 드물고 대부분은 정상적으로 동작합니다. 그래서 정상 상황에서 무엇에 더 중점을 두는지가 ELC입니다. E는 Else의 약자로 분할 상황이 아닌 정상 상황을 뜻하며, 이때 시간 지연과 일관성 중 무엇을 우선할지 선택합니다. EL을 선택한다는 것은 정상 상황에서 빠른 응답 속도를 우선시한다는 의미입니다. 이 경우 모든 노드가 완벽하게 동기화될 때까지 기다리지 않고, 빠르게 응답을 주는 것을 더 중요하게 여깁니다. EC를 선택하면 정상 상황에서도 모든 노드의 데이터 일관성을 우선시한다는 의미로, 응답이 조금 느려지더라도 모든 노드가 동일한 데이터를 갖도록 보장하는 것을 더 중요하게 여깁니다.
구체적인 구현 예를 살펴보면, PC 상황은 장애 발생 시 일관성이 중요한 경우입니다. 금융 시스템이나 예매 사이트처럼 한 자리를 여러 사람이 예매하면 안 되는 경우가 해당됩니다. 이런 시스템에서는 서버가 죽거나 서비스가 중단되더라도 일관성을 반드시 지켜야 합니다. 정상 상황에서 일관성이 중요한 EC에는 VoltDB와 HBase가 있고, 정상 상황에서 속도가 더 중요한 EL에는 PNUTS가 있습니다.
PA 상황은 장애 발생 시 가용 노드만 반영했다가 복구되면 전체에 반영하는 시스템입니다. 일관성이 다소 떨어져도 문제없는 경우에 사용합니다. 카카오톡 같은 메신저 프로그램에서 메시지를 주고받을 때 한쪽에 지연이 생겨서 메시지를 못 받았다고 해도 큰 문제가 되지 않습니다. 오히려 서버가 중단되는 것이 더 심각합니다. 이처럼 서비스 유지가 더 중요한 경우에 사용합니다.
장애 시에는 가용성을 중요하게 생각하면서 정상 상황에서 일관성을 중시하는 EC에는 MongoDB가 있고, 정상 상황에서도 속도가 더 중요한 EL에는 Cassandra와 DynamoDB가 있습니다.
PACELC 는 CAP이론을 보완하기 위해 등장한 이론이다. 네트워크 장애가 없는 시스템이란 존재하지 않기에 CAP에서는 CP나 AP 중 하나를 택해야한다. 이는 정상 상황은 고려하지 못하기에 정상 상황을 고려한 PACELC 이론이 등장한 것이다. 장애 상황에서는 A또는 C를 선택하고, 그외의 상황에서는 지연성인 Latency를 선택할 것이냐, Consistency를 선택한다는 것이다. EL을 선택한다는 것은 정상 상황에서 빠른 응답 속도를 우선시한다는 의미입니다. 이 경우 모든 노드가 완벽하게 동기화될 때까지 기다리지 않고, 빠르게 응답을 주는 것을 더 중요하게 여깁니다. EC를 선택하면 정상 상황에서도 모든 노드의 데이터 일관성을 우선시한다는 의미로, 응답이 조금 느려지더라도 모든 노드가 동일한 데이터를 갖도록 보장하는 것을 더 중요하게 여깁니다.장애 시에는 가용성을 중요하게 생각하면서 정상 상황에서 일관성을 중시하는 PA/EC에는 MongoDB가 있고, 정상 상황에서도 속도가 더 중요한 PA/EL에는 Cassandra와 DynamoDB가 있다. HBase는 PC/EC이다. 장애 상황일 때 C를 위해서 A를 희생합니다. 그렇지 않은 경우에는 C를 위해 L을 희생합니다. PC/EL에는 PNUTS가 대표적이다.
