Spring Data
Spring Data는 Spring Framework의 하위 프로젝트 중 하나로, 데이터 접근 계층을 구현할 때 반복되는 코드를 줄여 생산성을 높이는 것이 목표이다.
과거에는 DB에서 데이터를 가져오기 위해 직접 SQL을 짜고, Connection을 열고 닫고, 결과를 객체에 매핑하는 과정을 매번 구현해야 했다. Spring Data는 이를 추상화하여, 개발자가 비즈니스 로직에만 집중할 수 있도록 돕는다.
특징
- Repository 추상화: 인터페이스만 선언하면, 실행 시점에 Spring이 해당 인터페이스의 구현체를 자동으로 생성해준다. save(), findOne(), findAll(), delete() 같은 기본적인 CRUD 메서드를 직접 구현할 필요가 없다.
- 메서드 이름으로 쿼리 생성: 인터페이스에 메서드 이름만 규칙에 맞춰 지으면, Spring Data가 이를 분석해 쿼리를 자동으로 생성한다.
- 다양한 DB지원: RDBMS(관계형 DB)뿐만 아니라 NoSQL도 지원한다. DB 기술이 바뀌어도 사용 방법(인터페이스)은 거의 동일하다.
- Spring Data MongoDB: NoSQL인 MongoDB 연동
- Spring Data JPA: Hibernate 기반의 RDBMS 연동
- Spring Data Redis: Key-Value 저장소인 Redis 연동
- Spring Data Cassandra, Elasticsearch, JDBC 등
- 페이징 및 정렬 처리: 대량의 데이터를 다룰 때 필수적인 페이징과 정렬 기능을 아주 간단한 파라미터(Pageable) 추가만으로 처리할 수 있다.
Spring Data를 사용하는 이유
- 생산성 향상: 수백 줄의 DAO(Data Access Object) 코드가 단 몇 줄의 인터페이스 선언으로 대체된다.
- 유지보수의 용이성: 쿼리 방식이 표준화되어 있어 동료가 짠 코드를 이해하기 쉽고 수정도 빠르다.
- 데이터 저장소 기술로부터의 독립성: 비즈니스 로직과 데이터 접근 로직이 분리되어, 나중에 DB를 교체하거나 확장할 때 변경 범위가 최소화된다.
- 객체 지향적 개발: SQL 중심이 아닌 객체 중심의 개발을 가능하게 하여 도메인 모델에 더 집중하게 해준다.
Spring Data의 구조
Spring Data는 Spring Data Commons라는 공통 모듈을 기반으로 한다. 이 공통 모듈이 페이징, 기본적인 Repository 구조 등을 정의하고 각 DB별 모듈이 이를 상속받아 특화된 기능을 구현하는 구조이다.
- Spring Data Commons: 공통 인터페이스 및 인프라(Paging, Sorting, CrudRepository)
- Spring Data JPA/Mongo 등: 특정 기술에 특화된 구현체 제공
- Database Driver: 실제 DB와 통신하는 드라이버
Spring Data Commons
Spring Data는 여러 프로젝트로 되어있다. 그 중 Spring Data Commons에 대해 알아보자. Spring Data Commons는 개발자가 단계별로 필요한 기능을 골라 쓸 수 있게 인터페이스를 계층화해 두었다.
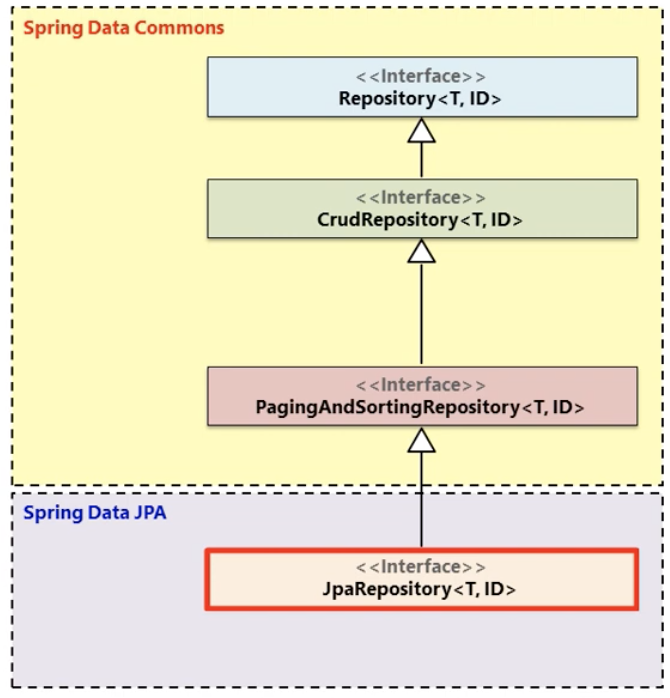
위 사진을 보면 Repository 인터페이스가 최상위 인터페이스로, 하위에 CrudRepository와 그 하위 인터페이스인 PagingAndSortingRepository 가 계층적으로 정의되어있는 것을 볼 수 있다. 그리고 Spring Data JPA라는 프로젝트에서 위의 Commons 인터페이스들을 모두 상속받고, 여기에 JPA 특화 기능(플러시, 배치 삭제 등)을 더한 것이다.
- Repository: 최상위 인터페이스로, 아무 기능이 없는 마커 인터페이스 이다.
- CrudRepository: 기본적인 CRUD 기능을 제공한다,
- PagingAndSortingRepository: CRUD기능에 페이징과 정렬 기능이 추가되었다.
예시 코드
public interface UserRepository extends JpaRepository<User, Long> {
// 이름으로 사용자를 찾는 메서드 (쿼리 자동 생성!)
List<User> findByName(String name);
// 이메일에 특정 단어가 포함된 사용자 찾기
List<User> findByEmailContaining(String keyword);
}만약 사용자 정보를 관리한다면, 예전에는 DAO 클래스를 만들어 EntityManager를 주입받고 복잡하게 짰겠지만, Spring Data를 쓰면 위 예시와 같이 간단하게 표현할 수 있다. 이제 이 인터페이스를 서비스 계층에서 주입받아 userRepository.save(user) 처럼 호출하기만 하면 된다.
Spring Data JPA
Spring Data JPA는 자바의 ORM표준 기술인 JPA(Java Persistence API)를 한 단계 더 추상화하여, JPA를 훨씬 더 쉽고 편하게 사용할 수 있도록 도와주는 스프링 모듈입니다. 실무에서 가장 많이 사용되는 Spring Data 프로젝트다.
Spring Data JPA는 JPA 기반의 Repository를 쉽게 구현할 수 있도록 도와주는 프레임워크다. JPA의 EntityManager를 직접 다루지 않고도 데이터베이스 작업을 수행할 수 있게 해준다.
JPA
- JPA는 자바 진영의 ORM표준 명세이다.
- Hibernate는 JPA의 가장 대표적인 구현체이다.
- Spring Data JPA는 JPA를 더 쉽게 사용할 수 있도록 추상화한 것이다.
// 인터페이스만 정의
public interface UserRepository extends JpaRepository<User, Long> {
}
// 사용
User user = userRepository.findById(1L).orElse(null);JpaRepository를 상속받는 UserRepository 인터페이스를 정의한 후 서비스 계층에서 해당 의존성을 받아 바로 사용할 수 있다.
Spring Data JPA 사용 이유
1. 반복적인 코드(Boilerplate)의 제거
기본적인 JPA만 사용하더라도 EntityManager를 주입받고, 트랜잭션을 시작하고, persist나 merge를 호출하는 코드를 반복해서 작성해야 한다. Spring Data JPA는 인터페이스 선언만으로 이 모든 과정을 내부에서 자동으로 처리한다.
2. 메서드 이름으로 쿼리 생성 (Query Method)
SQL이나 JPQL을 직접 작성하지 않고도 메서드 이름만 규칙에 맞게 지으면 쿼리가 실행된다.
3. 페이징과 정렬의 단순화
DB마다 다른 페이징 쿼리(Limit, Offset 등)를 고민할 필요가 없다. Pageable 인터페이스 하나로 수천만 건의 데이터를 나누어 조회하는 기능을 아주 쉽게 구현할 수 있다.
Spring Data JPA 특징
1. 쿼리 메서드 (Query Methods)
인터페이스에 메서드를 선언하는 것만으로 쿼리를 생성한다.
- Property Expressions: 엔티티의 필드명을 기반으로 쿼리 생성.
- Keyword 활용: Between, LessThan, Like, After 등의 키워드를 조합 가능.
예: findAllByAgeGreaterThanEqual(int age)
2. @Query 어노테이션
메서드 이름만으로 표현하기 힘든 복잡한 쿼리는 직접 JPQL(또는 Native SQL)을 작성할 수 있다.
@Query("select u from User u where u.email like %?1%")
List<User> findByEmailLike(String email);3. 지연 로딩(Lazy Loading)과 프록시
필요한 시점에만 데이터를 DB에서 가져오는 지연 로딩을 지원하여 성능을 최적화한다.
Spring Data JPA의 동작 원리
개발자가 인터페이스만 만들었는데 어떻게 데이터가 저장되는 걸까? 그 이유는 Spring Data JPA는 프록시 기반으로 동작하기 때문이다.
애플리케이션이 실행될 때, 스프링이 개발자가 만든 인터페이스(예: UserRepository)를 스캔하여 해당 인터페이스를 구현한 프록시 객체를 동적으로 생성한다. 이 프록시 객체 내부에는 SimpleJpaRepository라는 기본 구현체가 들어있어, 실제 DB 호출 로직을 수행하는 것이다.
예를 들어 userRepository.save(user)를 호출했을 때, 다음과 같은 일이 벌어진다.
- 프록시 호출: 우리가 호출한 것은 스프링이 만든 프록시 객체의 메서드이다.
- 전달(Delegate): 프록시 객체는 본인이 직접 로직을 수행하지 않고, 내부적으로 가지고 있는 SimpleJpaRepository 객체의 save() 메서드를 대신 호출한다.
- 실행: SimpleJpaRepository는 가지고 있는 EntityManager를 통해 em.persist(user)를 실행하여 DB에 데이터를 저장한다.
아래는 프록시가 어떻게 생성이 되는지를 관념적으로 표현한 예시 코드이다.
// 스프링이 런타임에 생성하는 프록시 클래스 (개념적 코드)
public class UserRepository$Proxy implements UserRepository {
private final SimpleJpaRepository<User, Long> target;
public UserRepository$Proxy(SimpleJpaRepository<User, Long> target) {
this.target = target;
}
@Override
public User save(User entity) {
// 1. 트랜잭션 시작 (부가 기능)
// 2. 실제 로직은 멤버 변수인 target에게 시킨다.
return target.save(entity);
}
@Override
public List<User> findByUsername(String name) {
// 공통 메서드가 아니므로 target(SimpleJpaRepository)에 시키지 않고
// 프록시가 가진 별도의 쿼리 생성 엔진이 실행함
return queryExecutor.execute("select u from User u where u.username = ?", name);
}
}UserRepository$Proxy 클래스는 UserRepository를 구현하고 있다. save()와 같은 공통 메서드는 SimpleJpaRepository구현체의 메서드를 호출한다. findByUsername()는 공통 메서드가 아니므로 쿼리 생성 엔진으로 실행한다.
SimpleJpaRepository
@Repository
@Transactional(readOnly = true)
public class SimpleJpaRepository<T, ID> implements JpaRepositoryImplementation<T, ID> {
private static final String ID_MUST_NOT_BE_NULL = "The given id must not be null!";
private final JpaEntityInformation<T, ?> entityInformation;
private final EntityManager em;
private final PersistenceProvider provider;
private @Nullable CrudMethodMetadata metadata;
private EscapeCharacter escapeCharacter = EscapeCharacter.DEFAULT;
// findById 부분만 발췌
@Override
public Optional<T> findById(ID id) {
Assert.notNull(id, ID_MUST_NOT_BE_NULL);
// 제네릭, 리플렉션
Class<T> domainType = getDomainClass();
if (metadata == null) {
return Optional.ofNullable(em.find(domainType, id));
}
LockModeType type = metadata.getLockModeType();
Map<String, Object> hints = new HashMap<>();
getQueryHints().withFetchGraphs(em).forEach(hints::put);
return Optional.ofNullable(type == null ? em.find(domainType, id, hints) : em.find(domainType, id, type, hints));
}
}간단히 살펴보면 Jpa 영속성을 관리하는 EntityManager도 보이고 실제 구현된 객체에서 em.find()하는 것을 볼 수 있다.
SimpleJpaRepository 클래스 자체에 @Transactional(readOnly = true) 설정이 되어있다. JPA는 트랜잭션 안에서 동작하기 때문에 Service 단에서 트랜잭션이 시작되지 않더라도 Repository단에서 기본으로 트랜잭션을 가져간다. (참고로, Service단에도 @Transactional이 있다면, 먼저 시작한 Service 단의 트랜잭션에 합류한다. 따라서 Repository작업이 끝나도 Service단의 메서드가 끝날때까지 커밋이 일어나지 않는다.)
추가로 @Repository 어노테이션을 통해 Bean객체로 올려주고 JPA 예외를 스프링이 추상화한 예외로 변환해 줄 수 있다고 한다.
그리고 제네릭을 이용해서 여러 엔티티들을 모두 받을 수 있게 잘 설계 되어있다. Class<T> domainType = getDomainClass();
Spring Data는 스프링 프레임워크의 하위 프로젝트 중 하나로, 데이터 접근 계층을 구현할때 반복되는 코드를 줄여 생산성을 높여주는데 목적이 있다. Spring Data Commons라는 공통 모듈을 기반으로 하여 페이징이나 기본적인 Repository 구조를 정의하고 각 하위 모듈이 이를 상속받아서 특화된 기능을 구현하는 구조이다. 따라서 다양한 DB를 지원하는 하위 모듈이 존재하여 DB가 바뀌어도 일관된 방식으로 사용할 수 있다. Repository를 인터페이스로 선언하면, 실행 시점에 Spring이 해당 인터페이스의 구현체를 자동으로 생성해준다. 그래서 기본적인 CRUD 메서드를 직접 구현하지 않아도 사용할 수 있다. 특정 규칙에 따라 메서드 이름을 지으면 Spring Data가 이를 분석해 쿼리를 자동으로 생성해준다. 이처럼 Spring Data를 사용하면 인터페이스만으로 DAO를 구현할 수 있어 생산성이 올라가며, 쿼리 방식이 표준화 되어있어 유지보수도 용이하다. 또한 비즈니스 로직과 데이터 접근 로직이 분리되어있어 차후에 DB를 교체하거나 확장할 때도 변경 범위가 최소화된다는 장점이 있다. 대표적인 하위 프로젝트로는 Spring Data JPA가 있다. 이는 JPA를 한 단계 더 추상화하여 쉽게 사용할 수 있도록하는 모듈이다. EntityManager를 직접 다루지 않고도 데이터베이스를 사용할 수 있다. JpaRepository를 사용하는 인터페이스가 있으면 스프링은 프록시 객체로 대체를 하고, 내부적으로는 SimpleJpaRepository라는 구현체의 메서드를 호출하여 기본 메서드를 사용한다. 또한 Query 어노테이션으로 메서드 이름만으로 표현하기 힘든 복잡한 쿼리를 직접 JPQL(또는 Native SQL)을 작성할 수 있다.
