안녕하세요, 오늘은 제가 읽은 첫 논문을 리뷰해보려고 합니다.
처음 읽어보는 논문이라 모르는 단어, 표현 등이 많아, 다 읽는데 많은 시간이 걸렸던 것 같습니다...
이 논문에서는 지금까지 제가 학부에서 배웠던 모델들이 아닌 처음 보는 모델이 등장을 합니다.
바로 GNN(Graph Neural Network)입니다.
Graph에 관한 개념은 학부 수업 중에 자료구조를 배우는 수업이 있어 이미 알고 있었습니다만, 이를 활용해 ai 모델을 구현하는 GNN모델이 존재할 줄은 몰랐습니다.
이제 리뷰 시작해보도록 하겠습니다.
1. Abstract
현대 축구에서 라이벌 팀의 전술 패턴을 파악하고 그에 대응하는 적절한 대응 방법을 발전시키는 것은 너무나 중요합니다.
그러나 이를 알고리즘적으로 접근하는 것은 아직 연구 과제로 남아 있습니다.
이 니즈를 충족시키기 위해 이 논문은 TacticAI를 제안합니다. 이는 실제 프로 축구 팀인 Liverpool FC 소속 전문가들과 협력하여 발전시킨 AI 모델입니다.
이 모델은 오직 코너킥 상황에 집중하는데요, 이유가 언급되어 있습니다. 코너킥은 코치들이 직접적인 개입을 하며 발전시킬 수 있고, 경기 결과를 바꿀 수 있기 때문이라고 합니다.
그 근거로,
- 코너킥 상황은 축구 경기에서 높은 빈도로 일어납니다. 각 경기마다 약 10개 언저리의 코너킥 상황이 펼쳐집니다.
- 고정된 상황에서 볼을 차므로 즉각적인 득점 기회를 제공합니다.
코너킥 외 다른 세트피스 상황은 위 근거들을 동시에 만족시키지 못한다고 합니다.
기본적으로 TacticAI 모델의 출력은 predictive(예측적)하고 generative(생성적)한 요소를 포함하고 있습니다. 그 요소는 코치들로 하여금, 코너킥 성공 확률을 높이기 위한 선수들의 더 효과적인 코너킥 셋업(e.g. 포지션)을 찾게 합니다.
또한, 아래의 벤치마크 작업을 실시했다고 합니다.
- Predicting Receivers (볼을 받는 선수 예측)
- Shot attempts (슈팅 시도 여부)
- Recommending player position adjustments (선수 조정 추천)
이 벤치마크 작업은 후에 더 자세하게 다뤄보겠습니다.
2.Introduction
Tactic AI 모델은 기하학적 딥러닝 기법을 통해 gold standard data (가장 정확하고 신뢰할 수 있는 데이터)에 가까운 데이터를 찾는 것을 가능케 한다고 합니다.
학습 데이터는 시공간적 선수들의 추적 데이터입니다.
그리고 Graph 구조를 채택한 것은 고차원의 잠재 선수 표현을 얻기 위함이고 선수들 간의 상호작용을 중요하게 볼 것이기 때문이라고 합니다.
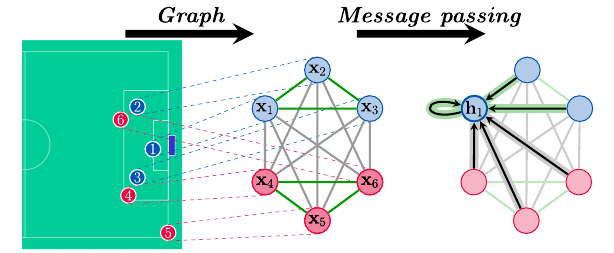
경기 내 선수들의 포지션을 그래프 구조로 표현한 것입니다.
Message passing은 그래프에서 노드 간에 정보를 전달하고 상호작용하는 방법입니다.
경기 내 각각의 선수는 그래프의 노드입니다. Message passing을 통해 이웃 선수들(노드들) 간의 상호작용 정보가 업데이트 될 것입니다.
Graph 구조의 특징 때문에 TacticAI는, 기하학적 딥러닝 기법을 통해 경기장의 여러 "대칭"을 고려하여 명시적으로 선수 표현을 할 수 있습니다.
논문에서 symmetry(대칭) 이라는 용어가 많이 등장을 하는데요.
이에 대해 설명을 해보자면, 축구 경기장은 직사각형입니다. 학습 단계에서 모델이 선수들의 위치를 포함하여 다양한 정보를 학습할 것입니다. 그런데 직사각형 모양의 경기장을 수직으로 뒤집거나, 수평으로 뒤집었을 때 학습하는 정보가 다르면 안됩니다. 그래서 이러한 대칭적인 여러 view들은 equivalent하다고 가정을 하는 겁니다. 아래 그림을 보겠습니다.
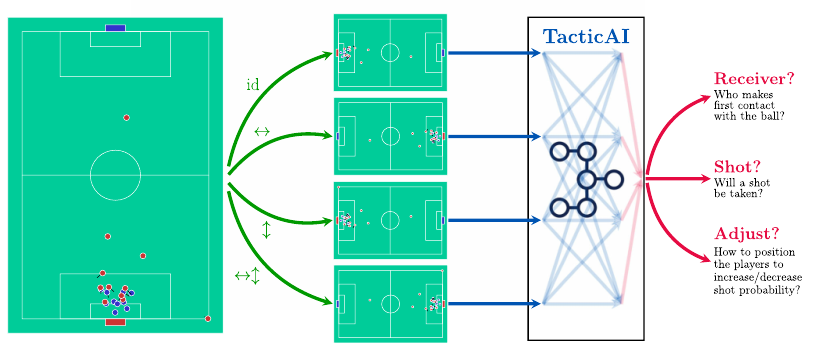
TacticAI의 출력이 수직, 수평 반사에 굳건함을 보장하기 위해, 입력되는 모든 코너킥 상황의 reflections(반사)를 반영합니다. 그것이 위 그림 중앙의 4가지 views(원본, 수직반사, 수평반사, 수직+수평반사)입니다. 하나의 코너킥 장면을 4개의 반사된 버전으로 모델에 입력하는 것이죠. 따라서 TacticAI의 코너킥 상황의 선수 표현은 이러한 반사들 사이에서 동일하게 계산되도록 보장합니다.
그렇게 모델이 학습하여 나오는 출력이 그림에서 보이는 빨간 글씨 Receiver, Shot, Adjust 등에 대한 것입니다.
지금까지 간략한 TacticAI에 대한 설명이었는데요, 이를 바탕으로 모델은 코너킥 결과에 대한 다양한 질문들에 대해 답을 할 수 있다고 합니다. 몇 가지 예를 들어 보겠습니다.
1. 볼을 가장 먼저 터치하는 선수가 누구인지?
2. 슈팅이 발생했는지?
위와 같이 대답만 하는 것이 아닌, 아래 다른 기능들도 제공을 한다고 합니다.
1. retrieval system(검색 시스템): 특정 선수들의 표현과 유사한 코너킥 상황을 검색함
2. generative recommendation system(생성 추천 시스템): 슈팅 확률을 조정하기 위한 선수들의 위치 조정 및 속도를 추천함
그리고 저자는 Liverpool FC 소속 전문가들과의 case study를 통해 얻은 수치적인 근거들을 기반으로 TacticAI가 손쉽게 유용하고 현실적이고, 정확한 전술적 제안들을 제공함을 알 수 있었다고 합니다.
이제 methods 섹션에서 어떻게 모델을 구현했는지 살펴보겠습니다.
3. Methods
기본적으로 TacticAI는 기하학적 딥러닝 구조를 기반으로 고안되었습니다.
크게 보면, 먼저 라벨링된 시공간적 축구 데이터를 그래프 표현으로 가공한 후, classification(분류) 혹은 regression(회귀)을 목적으로 하는 벤치마킹 작업을 바탕으로 훈련하고 학습시킵니다.
Raw corner kick data
원시 데이터 셋은 프리미어리그(EPL) [2020-21, 2021-22, 2022-23(~1월)]시즌의 9693개의 코너킥 장면으로 구성되었습니다. Liverpool FC 측에서 이 데이터 셋을 제공해 주었다고 하네요.
이 데이터 셋은 4가지의 데이터 소스로 구성되는데요,
1. spatio-temporal trajectory frames:
이것은 각 경기마다 피치 위의 모든 선수들과 볼을 추적한 경로 프레임이고, 초당 25프레임입니다.
2. event stream data:
패스, 슈팅, 골 등의 이벤트들을 가리키는 데이터입니다.
3. line-up data:
해당 경기의 선수 라인업 데이터입니다. 선수들의 몸무게, 키, 역할 등을 포함하고 있습니다.
4. miscellaneous data:
경기 당일 날씨, 경기장 정보, 피치의 크기 등 형형색색의 경기 외적 데이터입니다.
Graph representation and construction
전체적인 input graph 구성에 대한 설명입니다.
아래와 같은 그래프 구조가 있다고 가정해봅시다.
G = (V, ε)
노드 V와 ε ⊆ V × V 인 엣지로 구성됩니다.
축구는 22명의 선수가 경기를 하죠?
그래서 V(노드)는 피치 위 22명의 선수들입니다.
그리고 ε(엣지)는 모든 선수들 간의 상호작용이 가능하다고 가정하고
ε = V × V 라고 하겠습니다.
추가적으로, 그래프가 적절히 featurised 되어 있다고 가정하고
node feature matrix인 X ∈ R^(|V|×k),
edge feature tensor인 E ∈ R^(|V|×|V|×l),
graph feature vector인 g ∈ R^(m)
을 둡니다.
이러한 객체들의 적절한 항목은 노드, 엣지, 그래프의 input features를 제공합니다.
예를 들면,
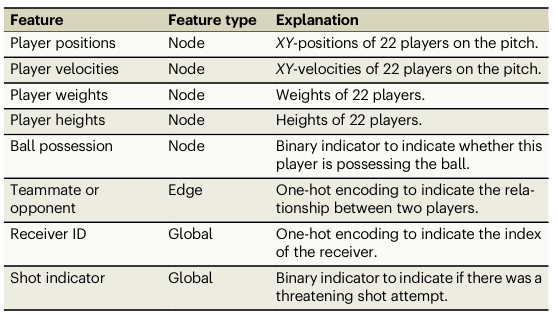
- x_u ∈ R^(k): 개개의 선수들 u ∈ V 의 특징들을 제공,
e.g. 선수의 포지션, 키, 몸무게 등 - e_uv ∈ R^(l): 특정한 한 쌍의 선수들 (u,v) ∈ ε 의 특징들을 제공,
e.g. 선수 간의 거리, 같은 소속 팀인지? 등 - g: global한 특징들을 저장하는 데 사용,
e.g. 게임 시간, 현재 스코어, 볼의 위치 등
이 있겠습니다.
input graph를 만드는 데 사용된 정확한 정보는 아래와 같습니다.
앞서 서술했듯이 코너킥 장면은 9693개였습니다.
그런데 데이터 전처리가 빠지면 절대 안되겠죠?
실제로, input graph를 만들기 위해 4개의 데이터 소스를 정렬시켜 결측값(e.g., tracking frames, event labels)이 포함된 데이터들을 걸러냈습니다.
그렇게 해서 나온 2517개의 invalid 코너킥이 필터링 되었고,
최종적으로는, 7176개의 적절한 코너킥 데이터를 사용할 수 있었다고 합니다.
더 자세한 데이터 전처리 내용이 있었지만 제가 공부하려고 하는 포인트에서 벗어나기 때문에 생략하겠습니다.
Graph neural networks
TacticAI의 중심 모델은 graph neural network (GNN)입니다.
이웃 노드들 간의 상호작용 정보를 바탕으로 그래프 내에서 잠재 표현을 계산하는 것이죠.
N_u = {v|(v,u) ∈ ε}
한 노드의 이웃을 N_u라고 정의합시다. 여기서 이웃은 노드 u의 모든 인접 노드의 집합을 말합니다.
GNN 한 개의 층은 이웃 노드들 사이에서 message passing을 통해 노드 features를 변환합니다.
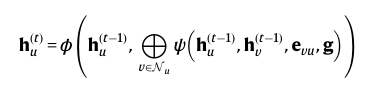
이 수식을 보겠습니다.
여기서
ψ: R^k × R^k × R^l × R^m → R^k' 와 Φ: R^k × R^k' → R^k' 는
learnable function입니다.
(learnable function은 다층 퍼셉트론과 같이 가중치와 편향을 포함하는 학습 가능한 함수를 말합니다.)
h_u^(t)는 t개의 GNN 층을 통과한 후의 노드 u의 features입니다.
⨁는 permutation-invariant aggregator입니다.
(permutation-invariant aggregator는 순서를 생각하지 않는 sum, max, average와 같은 집계함수를 말합니다. 즉, 이웃 노드들의 순서가 바뀌어도 같은 출력을 내는 집계함수인 것입니다.)
이제 h_u^(0)=x_u라고 세팅합니다. 그 후 위 수식을 반복하여 시행합니다.
H = f_ζ^(X,E,g) = H^(T)를 GNN으로부터 나온 final node embeddings라고 하겠습니다.
node embedding이란? 그래프 데이터에서 각 노드(node)를 고정된 차원의 벡터(vector)로 변환하는 기법입니다. 노드의 특성을 딥러닝 모델이 이해할 수 있도록 수치 벡터로 바꿔주는 것이죠.
위에서 말한 H는 결국 우리가 원하는 특성 행렬이 됩니다.
논문에서는 위 수식이 잘 알려진 식이라고 하는데요, 저는 처음 봤습니다...
이 수식이 Transformers와 같은 유명한 모델들을 표현하는데 사용될 수 있다고 하네요. 심지어는 모든 이산적 딥러닝 모델들이 이 형태로 표현될 수 있다는 주장도 있다고 합니다.
어쨌든 이 수식으로 인해 GNN을 선수-선수 간의 상호작용을 모델링하기 위한 완벽한 프레임워크로 만들어준다고 합니다.
ψ, Φ, ⨁ 를 다르게 선택하면 다른 구조를 만들 수 있습니다.
이 논문에서는 a(attentional mechanism)를 이용합니다.
attentional mechanism은 입력 데이터에서 중요한 부분에 가중치를 부여하여 집중하는 방법입니다. 자연어 처리(NLP)에서도 사용되고 있죠.
그래서
a: R^k × R^k × R^l × R^m → R:
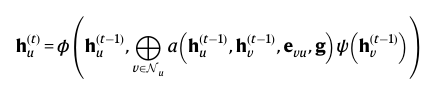
이런 수식이 나오게 되는데요.
이 수식이 바로 graph attention network (GAT)입니다.
TacticAI 모델을 만들 때는 조금 더 나아가 GATv2를 사용했다고 하는데요,
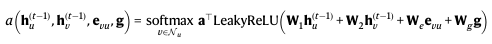
바로 이 수식입니다.
attention mechanism에 대해 2개 층인 multilayer perceptron을 사용합니다.
무엇이 더 개선되어 GATv2가 등장했을까요?
개선점
기존의 GAT는 노드 u와 이웃노드 v 간의 중요도를 다음과 같이 계산합니다.
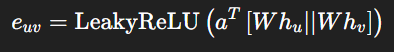
h_u와 h_v를 선형변환(W)을 적용한 후에 둘을 결합하여 중요도(어텐션 값)를 계산합니다. 그런데 이렇게 되면 어텐션 값이 항상 가중치 W에 의해 제약되게 됩니다.
결과적으로는 GAT의 표현력이 제한되는 것이죠.
그런데 어텐션 연산 공식은 순서를 고려하지 않습니다.

그래서 이렇게 어텐션 값을 먼저 계산한 후 선형변환(W)을 적용할 수 있습니다. 이렇게 하면 어텐션 연산이 더욱 자유로워지고 유연한 학습이 가능하게 됩니다. 유연한 학습이 가능하면 성능이 좋아진다는 말이 되고, 이어서 표현력이 향상된다는 뜻이기도 하죠.
이렇게 개선점을 확인해봤습니다.
추가로 저는 LeakyReLU 함수를 이 논문을 통해 처음 접했는데요,
- LeakyReLU란?
ReLU는 음수인 값을 아예 죽여버렸다면, LeakyReLU는 그렇지 않습니다. 음수 값은 작은 기울기를 유지하도록 합니다. 즉, 죽이는 뉴련은 없는 것이죠.
다시 GATv2로 돌아오겠습니다.
이 GATv2의 메커니즘은 각 쌍의 연결된 노드들(u, v)의 상호작용 계수를 계산합니다. 그 값은 scalar value가 되죠.
그 후, softmax를 적용하여 노드 u의 모든 이웃들 사이에서 정규화합니다.
지금까지의 내용을 보면, 저자가 GAT 모델을 중심으로 작업을 진행한 것을 알 수 있습니다.
Geometric deep learning
그러나 위에서 언급한 GNN 수식이 강력함에도 불구하고, ψ와 Φ가 대량의 parameters를 가지고 있기 때문에 이를 full로 일반화하면 overfitting이 발생하기 쉽다고 합니다.
이 문제는 특히 축구 분석에 치명적일 수 있죠.
안그래도 EPL(English Premier League)은 매 시즌마다 수백 경기밖에 열리지 않는데, 그 중에서도 최고 품질의 코너킥 gold-standard data는 굉장히 드뭅니다. 코너킥 성공 확률이 매우 낮기 때문입니다.
대량의 parameters와 적은 데이터 수는 당연히 overfitting을 유발할 수 있습니다.
이를 해결하기 위해 GDL(Geometric Deep Learning)을 활용합니다.
GDL에 대해 설명해보겠습니다. 간략하게, GDL은 데이터의 대칭성(symmetry)이나 변환 불변성을 수학적으로 반영해 과적합을 줄이고 일반화 성능을 높이기 위한 GNN 설계 전략입니다.
쉽게 이야기해보죠, 앞에서 계속해서 언급했었던 대칭성(symmetry)이 축구 경기에 중요하게 작용하는데, 이를 이용하겠단 의미입니다.
예를 들어 보겠습니다. 코너킥을 왼쪽에서 오른쪽으로 차는 것과 이에 대칭되는 오른쪽에서 왼쪽으로 차는 것을 같다고 본다는 겁니다.
물론 페널티 박스 내 선수들의 포지션 등 디테일은 차이가 있겠지만, 큰 범위에서 이러한 수학적 대칭과 변환에 대해 같은 것이라고 보면 학습할 parameters 수가 줄어들 것이라는 거죠.
아래 수식을 볼까요?
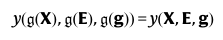
X는 노드 피쳐, E는 엣지 피져, g는 그래프의 글로벌 피쳐(구조적 정보)입니다.
※ 변환 g는 연하게, 그래프 구조 g는 진하게 표현하겠습니다.
여기에 어떤 변환 g를 적용해도 변하지 않습니다.
이러한 조건을 G-invariance 라고 합니다.
g(X)는 그러면 X에 변환 g를 적용한 결과가 되는 것이죠.
그런데, GNN 역시 GDL 관점에서 유도할 수 있다는 점은 주목할 만합니다. 노드들의 순서가 섞이더라도 그래프 의미는 같다는 대칭성을 반영하는 겁니다.
위에서 언급했던 GNN 수식 덕분에,
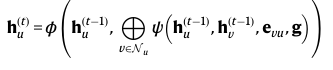
input 그래프의 노드 순서 즉, 순열에 의존하지 않게 됩니다.
바로 이러한 GDL 관점을 활용하면,
같은 의미를 가지는 다른 모양의 데이터를 하나의 패턴으로 처리할 수 있습니다. 이는 데이터 수를 줄이는 것이 아닙니다! 저도 공부하다 헷갈렸던 부분이었는데, 데이터 수가 아닌 필요한 parameters 수가 줄어드는 것입니다.
그러면 overfitting을 방지할 수 있죠.
Frame averaging
Frame averaging은 간략히 설명하면, 노드 순서를 랜덤하게 바꿔서 입력 후 그 결과의 평균을 취하는 것입니다.
이는 G-invariance를 강화하기 위한 목적입니다. 즉, 어떠한 변환에 대해서도 강건한 모델을 만들고 싶다는 것이죠.
예를 들어 이해해볼까요?
Frame averaging을 함으로써,
여러 상황의 코너킥 패턴을 평균적으로 학습할 수 있습니다.
그래서 G-invariance가 강화되고,
변환이 있어도 같은 전략으로 인식할 수 있는 것입니다.
이를 반영하겠다는 겁니다.
이것을 표현한 것이 바로 아래 수식입니다.
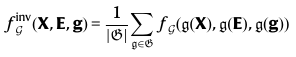
놀랍게도 우리가 잘 알고 있는 알파고(AlphaGo) 모델은, 이러한 접근법을 변형시켜 반영한 모델이라고 하네요? 마찬가지로 바둑판의 대칭성을 활용한 것인데, 처음 알았습니다.
이 연구에서는 G = D_2 = {id,↔,↕,↔↕} 라고 정의합니다.
경기 원본, 좌우 대칭 변형, 상하 대칭 변형, 상하좌우 대칭 변형 입니다.
이 변형들로부터 모델을 강건하게 만들어줍니다.
Group convolutions
Frame averaging은 변환된 여러 입력을 평균내므로 대칭성을 보장하긴 하지만, 각 변환된 버전 간의 정보 상호작용은 제한된다고 합니다.
이것을 해결하기 위해 G-equivariance라는 조건을 사용합니다.
G-equivariance란 무엇일까요?
이는 입력 또는 출력에 변환을 적용해도 결과가 동일해야 한다는 수학적 성질을 의미합니다.
저는, 정보 상호작용이 필요한데 G-equivariance가 왜 필요한지 이해가 되질 않았습니다. 그런데 아래 수식을 보겠습니다.
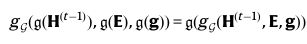
이때의 H^(t)입니다.
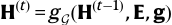
G-equivariance 조건을 만족하면, 입력 데이터가 G의 다른 변환 상태라고 하더라도 동일한 방식으로 정보가 흘러야 합니다.
이 말은 곧, 모든 G-변환된 뷰들 간의 관계성을 유지하며 연산을 수행하는 구조가 되므로, 그들 사이에 정보 상호작용이 자동으로 일어나게 됨을 의미합니다.
쉽게 G-equivariance를 만족하는 구조가 되면, 상호작용이 유도된다는 것이네요.
앞서 이 연구에서는 G = D_2 = {id,↔,↕,↔↕} 라고 정의했죠.
D_2-equivariance를 만족하려면 Group convolution 접근이 필요하다고 합니다. 말이 어려워서 그렇지, 기존의 합성곱(convoultion)을 G-equivariance를 만족하는 합성곱으로 발전시켰다고 보면 될 것 같습니다.
아래 수식을 보겠습니다.
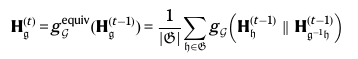
H^(t)를 재정의하여 H_g^(t)로 즉, t개의 층에서 g-변환된 뷰를 나타낸다고 정의합니다. 간결함을 위해 E, g를 제거하고 수식을 나타낸 것입니다.
이렇게 Group convolution을 수행할 수 있다고 합니다.
|| 기호는 concat 연산입니다. 열 단위로 2개의 노드 feature matrix를 합칩니다.
그런데 이때, g^(-1)은 g의 역변환을 뜻하며, g^(-1)h는 두 변환의 조합입니다.
이 수식을 디테일하게 이해하진 못했습니다만, 논문에서는 이렇게 밝히고 있습니다. 그룹의 크기가 커지면 연산량이 기하급수적으로 증가할 수 있다고 합니다.
그래서 이 연구에서 사용되는 4가지 D_2 = {id,↔,↕,↔↕}같은 작은 그룹에 적합한 방법이라고 하네요.
Network architectures
저자가 말하길, 3가지 benchmark tasks는 모델의 글로벌한 특성에서 조금씩 차이를 보이지만 신경망 모델은 같은 encoder-decoder 구조를 가지고 있다고 합니다.
자세하게는,
encoder 구조는 모두 같고 decoder 구조는 각 task마다 맞춤형으로 적용된다고 합니다.
Benchmark tasks
- Receiver prediction
- Threatening shot prediction
- Guided generation of team positions and velocities
오리지날 input 그래프에 대해서 identity view라고 하고,
나머지 3개의 D_2-변환된 그래프들을 reflected views라고 하겠습니다.
이렇게 4가지 views가 준비되면,
GATv2 기반 모델로 4개의 group convolution 층을 통과시킵니다.
각각의 GATv2의 layer은 8개의 attention heads를 가지고 있습니다.
여기서 attention head는 한 layer 안에서 attention 연산을 병렬적으로 여러 번 수행하는 구조입니다. 즉, 8개의 heads라면 동일한 노드 관계에 대해 8가지 다른 방식으로 attention을 학습하는 것이죠.
그렇게 모든 선수 개인 마다 4가지 잠재 특성을 계산한 후,
우리는 H ∈ R^(4×22×4) 를 얻습니다.
- 1번째 차원: 4가지 변환-뷰
- 2번째 차원: 22명의 선수들
- 3번째 차원: 각 선수 노드의 4가지 잠재 표현
decoder에사 이것이 어떻게 사용될지는 구체적인 예측 과제에 따라 달라진다고 합니다.
한 개씩 살펴보겠습니다.
1) receiver prediction
볼 받는 선수 예측입니다. 볼을 받는 선수는 변환된 뷰에 대해서 불변이어야 합니다. 쉽게, 뷰를 상하로 반전시켰다고 해도 실제로 볼을 받는 선수는 변하지 않는다는 뜻이죠. 모든 뷰에 대해서 frame averaging을 수행합니다.
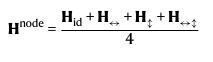
이렇게 말이죠.
이제, H^(node)의 행에 대한 node-wise classifier을 학습합니다.
각 노드 별로 학습 후, 따로 결과를 내는 것입니다.
더 나아가서 H^(node)를 logit vector O로 decode합니다.
softmax cross entropy loss를 계산하기 직전 상태입니다.
2) shot prediction
슈팅 예측입니다. 마찬가지로 변환된 뷰에 대해 슈팅 확률은 불변입니다.
global한 그래프 표현을 얻기 위해 모든 선수의 feature 벡터를 평균냅니다.
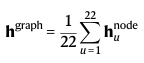
이렇게 h_22^(graph) 벡터를 얻을 수 있죠.
이번엔, binary classifier를 학습합니다.
그 후, 똑같이 logit을 계산하는데 이 은닉 벡터를 하나의 선형층으로 통과시켜 단일 logit을 구합니다.
더 나아가서 logit과 label(정답)을 비교해서 sigmoid binary cross-entropy loss를 계산까지 하게 됩니다.
3) guided generation (position/velocity adjustments)
선수 조정 추천입니다. 코너킥 상황 선수의 포지션과 속도를 추천해주는 task입니다. 코치들의 관심사에 해당하는 특정 결과를 잠재 feature matrix의 행에 대한 예측 결과로 내놓는 것입니다.
원문을 그대로 해석해보려고 했는데 쉽게 풀어쓰진 못했네요.
원문의 예시로 설명해보겠습니다.
모델이 수비 팀 입장에서, 공격 팀의 슈팅 확률을 낮출 수 있는 수비적 setup을 조정할 수 있다는 뜻입니다.
모델의 결과는 현재
[√] equivariant
[ ] invariant
즉, 입력에 대해 변환이 있으면 출력도 변환되는 상황입니다.
그런데 코치에게 정확한 위치와 속도를 추천해줘야 하는데, view가 뒤집히는 등의 reflect된 결과를 추천해주면 안되겠죠?
그래서 원본 즉, identity view(H_id)의 특성만 활용함과 동시에 frame averaging을 수행할 수 없습니다.
H_id의 각 행(한 명의 선수)으로부터 우리는 해당 선수의 position과 velocity를 모델링하는 conditional distribution(조건부 확률 분포)을 학습할 수 있습니다.
이를 위해 기존 방식의 decoder를 확장시킨 conditional variational autoencoder (CVAE)를 사용합니다.
처음 들어보는 용어인데, 쉽게 말해서 어떤 조건이 주어졌을 때 그에 맞는 출력 샘플(여기서는 position, velocity)을 생성하게 해주는 구조라고 합니다.
구체적으로 보겠습니다.
H_id의 u번째 행인 h_u는 2차원 Gaussian distribution N(μ_u,σ_u)의 평균과 표준편차로 변환됩니다. 그리고 이 분포에서 위치와 속도 벡터를 샘플링합니다.
학습할 때는, 위 샘플링 과정에서도 역전파를 흘릴 수 있도록 reparameterisation trick을 사용합니다. 또 다시 처음 보게 되는 용어입니다.
제가 공부해 본 바로 설명해보겠습니다.
CVAE에서는 잠재변수 z를 확률분포에서 샘플링 합니다.
그런데 이 샘플링은 랜덤(비결정적)하기 때문에 역전파가 되질 않습니다.
그래서 확률적 샘플링을 결정론적인 함수로 바꾸는 것이 아이디어라고 합니다.
z = μ+σ⋅ϵ, ϵ∼N(0,1) ← 이렇게 말이죠. (ϵ는 샘플링 과정에서 noise입니다.)
요약하면, 샘플링한 것을 함수화 하겠다 라는 것입니다.
다시 돌아와서,
이에 대한 loss 함수 수식입니다.
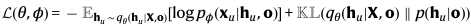
이 loss 함수는 두 항으로 구성됩니다.
log-liklihood와 KL divergence죠.
h_u는 H_id의 u번째 행에 해당되는 선수의 잠재 벡터입니다.
x_u는 실제 입력(선수의 실제 position, velocity)입니다.
KL divergence는 두 확률분포 간의 차이를 측정하는 척도입니다.
참고) 여기서 ρ_Φ는 decoder입니다.
손실함수의 첫번째 항은 "h_u로부터 x_u를 잘 복원했는가?"를 평가합니다.
두번째 항은 h_u의 분포가 다변량 가우시안 분포와 가깝도록 규제합니다.
즉, model의 encoder가 만든 잠재 분포가 너무 복잡하거나 편향되지 않도록 regularization을 적용한다고 보면 될 것 같습니다.
그래서 이에 대한 전체적인 요약을 그림으로 표현하면 이렇습니다.
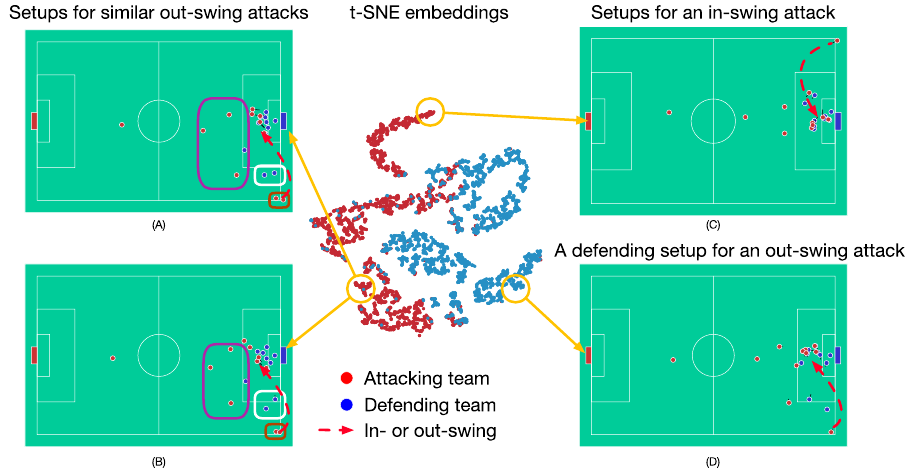
이 그림이 TacticAI 모델의 잠재 공간에서 형성된 코너킥 표현입니다.
그림에서 (A),(B),(C)는 공격 팀 입장, (D)는 수비팀 입장입니다.
총 1024개의 코너킥 장면에 대해, 공격, 수비팀의 잠재 표현을 t-SNE 기법으로 시각화했다고 합니다.
t-SNE 기법은 차원 축소 기법으로, 고차원 데이터를 2D, 3D로 줄여서 시각화하는 기법입니다.
하나의 코너킥 샘플에서 팀의 잠재 embedding은,
동일 팀에 소속된 선수들의 잠재 embedding 평균값으로 계산됩니다.
코너킥 (A)를 기준으로 하고, 잠재 공간에서 가장 가까운 거리로 계산된 또 다른 코너킥 샘플 (B)를 검색할 수 있습니다.
이때 (A)와 (B)의 빨간 화살표를 보면 알 수 있듯이 두 장면 모두 아웃스윙(out-swing) 코너킥이며, 공격 전술 패턴이 유사함을 관찰할 수 있습니다.
※ 주의: 빨간 화살표는 인스윙(in-swing)과 아웃스윙(out-swing) 킥을 구분하기 위한 것이므로 실제 공의 궤적은 아닙니다!
보라색 사각형으로 공격 팀의 유사한 전술 패턴을 강조해놨는데요, 선수들의 실제 position과 velocity는 두 장면에서 미세하게 다를 순 있겠습니다.
반면 (C) 장면은 인스윙(in-swing)킥을 시도한 코너킥이므로, (A)와 (B) 장면과는 멀리 떨어져 있는 것을 확인할 수 있습니다.
논문에서 얘기하는 "거리"에 대해서는, 정확히 어떻게 계산했는지 나오지 않습니다. 추측으로는, 유클리드 거리일 가능성이 높아 보입니다. 찾아보니, t-SNE로 시각화 할 때 유클리드 거리를 기본적으로 사용한다고 하네요.
유클리드 거리는 L_2-norm(절대값)을 이용하여 계산합니다.
Ablation study
여기서는,
저자가 모델의 잠재 표현이 receiver predition에서 더 나은 성능을 낼 수 있을 것이라고 가정한 후 ablation study를 진행했네요.
그래서 이를 구체화하여 4가지 질문을 던집니다.
- factorized 그래프 표현이 도움이 되는가?
-> 그래프 표현을 사용하지 않는 CNN 모델과 비교합니다.- 그래프 구조 자체가 도움이 되는가?
-> 인접 노드의 정보를 고려하지 않는 Deep Sets 모델과 비교합니다.- attentional GNN이 좋은 전략인가?
-> GATv2가 아닌 일반 GNN(MPNN)과 비교합니다.- 대칭성을 고려하는 것이 도움이 되는가?
-> 대칭성을 group convolution만 수행, frame averaging만 수행, 또는 둘다 수행하지 않은 경우로 나누어 비교합니다.
이러한 각각의 모델은 50,000번의 training steps만큼 훈련되었습니다.
훈련된 모델의 top-k receiver prediction 정확도입니다.
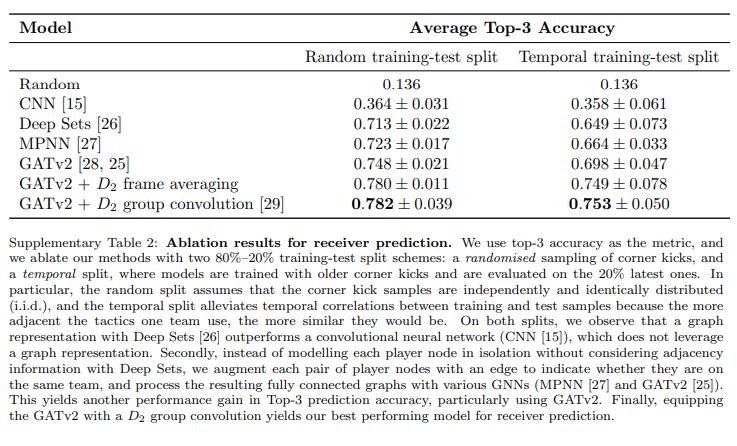
후에 Results 섹션에서 다루겠지만, 전체 그래프 구조를 사용하는 것과 대칭성을 고려하는 것은 분명한 이점이 있다고 합니다. Results 섹션에서 이에 대한 이점이 설명되니 후에 확인해보겠습니다.
또한, MPNN을 사용하면 GATv2에 비해 약간의 overfitting이 발생된다고 합니다.
그러므로 attention기반의 GNN 모델이 더 좋은 결과를 낼 수 있다는 것이죠.
추가로 저자가 shot prediction task에 대한 ablation study 자료를 첨부했네요.
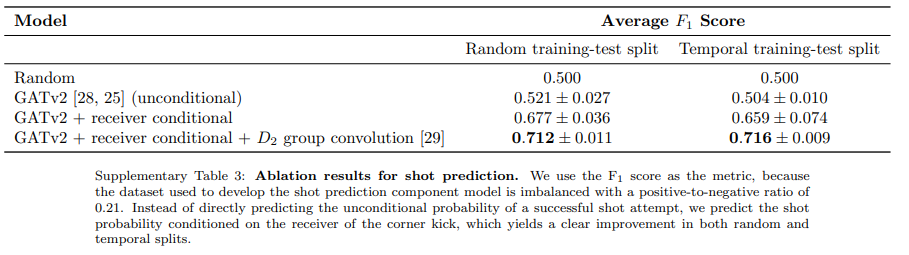
역시나 GATv2 + D_2 group convolution인 모델의 F1 score가 가장 높습니다.
Training details
훈련 세부사항에 대해 언급되어 있는 섹션입니다.
- GPU: NVIDIA Tesla P100 GPUs
- L^2 norm penalty로 규제
- Optimizer: Adam stochastic gradient descent
- Hyperparameter ->
message passing 횟수: {1, 2, 4}
초기 learning rate: {0.0001, 0.00005}
batch size: {128, 256}
L^2 규제 계수: {0.01, 0.005, 0.001, 0.0001, 0}
보충 자료에서 Hyperparameter 자료를 첨부합니다.
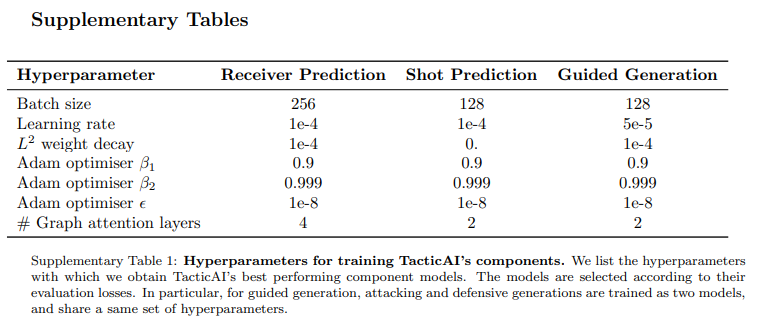
4. Results
이제 Results 섹션입니다. 이 섹션에서는 수치 분석을 통해 TacticAI 모델의 성능을 입증하고 전문가들과의 평가가 이루어집니다.
원문에서 Methods 섹션보다 Results섹션이 먼저 쓰여있지만, Methods를 먼저 공부하고 Results를 읽으면 더 수월하게 이해할 수 있을 것 같아 순서를 좀 바꿔봤습니다. 그래서 중복되는 내용이 종종 나올 수 있겠습니다.
Benchmarking TacticAI
TacticAI는 3가지 기능을 가지고 있다고 했습니다.
1. Receiver prediction
2. Shot prediction
3. Guided generation
이 3가지 기능에 대한 벤치마킹 작업이 이루어지는 것이 자연스러운 과정입니다.
2020/2021 시즌 Premier League의 7176개의 코너킥을 dataset일 때,
랜덤하게 섞고, training(80%)과 test(20%) set로 나누었습니다.
계속해서 설명 해온대로, TacticAI는 그래프 기반 모델입니다.
그래서 각 코너킥 상황을 그래프로 표현하구요, 각 노드는 선수에 해당하죠.
각 노드에 연관된 특성들은
선수의 움직임(position, velocity), 신체 정보(키, 몸무게)입니다.
이 특성들은 코너킥 상황에서 키커가 볼을 차는 그 순간의 상태를 기점으로 encoding됩니다.
그래프는 fully-connected 이므로, 모든 선수 쌍마다 하나의 엣지를 가지게 됩니다. 이때, 각 엣지에는 그 묶인 두 선수가 같은 팀인지, 다른 팀인지의 여부를 나타내는 이진값이 encoding됩니다.
이제 각 벤치마크 작업에 대해 node/edge/graph 특성과 해당하는 라벨(정답)을 포함한 데이터셋을 생성했습니다.
그래프를 만들 때는 최소한의 특성들만 사용했다고 하는데요, 예를 들어,
공의 움직임 혹은 선수 간의 거리 등은 encoding하지 않았다고 합니다.
그렇게 한 후, 동일한 train-test split을 사용하여 개별적인 요소들 뿐 아니라 요소들 사이의 상호작용까지 벤치마킹할 수 있었다고 합니다.
Accurate receiver and shot prediction through geometric deep learning
볼 받는 선수와 슈팅 예측은 TacticAI의 key 예측 모델이라고 언급하고 있습니다. 볼을 받는 선수는 정확하게는, 코너킥이 차여진 후 처음으로 볼을 터치하는 선수입니다.
그래서 먼저 receiver prediction에 대해, TacticAI 기반 여러 다른 모델들로 벤치마크 작업을 수행했다고 합니다. 그 중에서 가장 좋은 퍼포먼스를 보인 모델은 50,000번의 training steps를 거친 후 top-3 test 정확도가 0.782±0.039였다고 합니다. 이 수치는 위에서 한 번 다뤘죠? GATv2+D_2 group convolution 모델이었습니다.
그런데 receiver prediction은 상당히 어려운 작업이라고 합니다. 모델에 의해서도 보이지 않는 여러 요소들 때문인데요, 선수의 피로도와 몸상태, 실제 볼 궤적 등이 있습니다.
그럼에도 불구하고 정확도가 0.782±0.039라는 것은 TacticAI가 높은 수준의 receiver prediction 능력을 갖추었다는 것을 입증합니다.
shot prediction에 대해서는, 기본 TacticAI 구조를 사용하여 관찰했다고 합니다. probability P(shot|corner)를 직접 모델링하려 했는데,
이에 대한 F1-score는 0.52±0.03였습니다.
F1-score란?
정밀도(precision)와 재현율(recall)의 조화 평균(harmonic mean)입니다.
슈팅 예측처럼 데이터가 불균형한 binary classification 문제에 많이 사용됩니다.
F1-score 설명을 보면 알 수 있듯이 1에 가까울수록 precision과 recall의 균형이 좋다는 뜻이므로 좋은 점수입니다.
그러므로 0.52에 가까운 위의 점수는 그리 좋은 점수는 아닐겁니다.
방법이 없을까요?
여기서 receiver prediction이 좋은 성능을 보였던 것에 주목합시다.
저자는 receiver prediction의 결과를 사용하여 슈팅 여부를 판단 할 수 있다고 말합니다.
이 부분이 저는 인상깊었네요. 슈팅이 나온다는 것은, 공을 받는 선수가 존재한다는 뜻이니까요, 좋은 접근이었던 것 같습니다.
그래서 P(shot|corner)를 분해합니다.
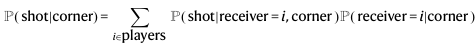
이렇게 말이죠.
식에서 P(receiver=i|corner)가
모델의 receiver prediction을 통해 나온 계산된 학률입니다.
그리고 P(shot|receiver=i,corner)는
특정 선수와 공의 첫 접촉 후의 조건부 슈팅 확률입니다.
그래서 shot prediction을 위해 receiver 정보를 추가적인 입력으로 제공했음을 알 수 있습니다.
이렇게 2단계로 나누어서, 조건을 달아준 후의 F1-score는 0.68±0.04로 향상되었습니다.
shot prediction은 슈팅 발생 여부를 정확히 맞추려고 하기보다, 코너킥 전술을 조금씩 바꿨을 때 슈팅 확률이 어떻게 바뀌는지를 비교하는 용도로 사용된다고 합니다.
추가적으로, TacticAI 모델은 receiver prediction 기능 하나만 학습했음에도 불구하고, 전술적으로 유사한 팀들의 setups이 군집화된다는 사실을 관찰했다고 합니다.
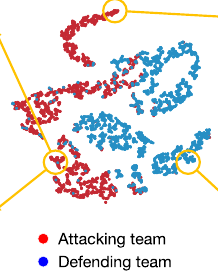
위에서 봤었던 잠재 공간 이미지입니다. 이렇게 군집화된다는 것입니다.
input 공간에서 raw data는 뚜렷한 군집화가 보이지 않았다는 점과 비교하면 TacticAI의 성능을 확인할 수 있다고 말합니다. 그림을 보면 바로 알 수 있죠.
Controlled tactic refinement using class-conditional generative models
이제 guided generation에 대해 알아볼 차례입니다.
코너킥 결과와 관련하여 TacticAI를 활용해 전술을 조정할 수 있다고 합니다. 전술 조정을 통해 특정 이벤트 발생 확률을 높이거나 낮추기 위한 용도인 것이죠.
예를 들어, 공격 팀은 슈팅 확률을 높여 득점할 수 있는 전술로 조정을 해야할 것이고, 이와 반대로 수비 팀은 슈팅 확률을 낮추어서 실점을 줄이는 전술로 조정을 해야할 것입니다.
실제 경기에서는 두 팀이 서로의 움직임에 동시에 반응합니다. 그러나 이 연구에서는 한 팀의 움직임을 적절히 조정하여 전술에 반응하지 않는 선수들을 식별하는 데 중점을 둔다고 합니다.
그래서 한 팀은 고정시키고, 다른 한 팀만 조정하는 방식으로 단순화합니다.
그래서 이 모델은 입력 위치 좌표를 재구성하는 autoencoder 구조입니다.
이 autoencoder-based 모델은 기존의 예측 시스템과는 별개의 독립적인 요소입니다. 이 부분은 이미 methods 섹션에서 다뤘습니다. receiver prediction, shot prediction, guided generation 3가지 시스템은 같은 encoder 구조를 사용하지만, decoder 구조는 다르다고 했었죠.
전술 조정 시스템 예시를 그림으로 살펴보겠습니다.
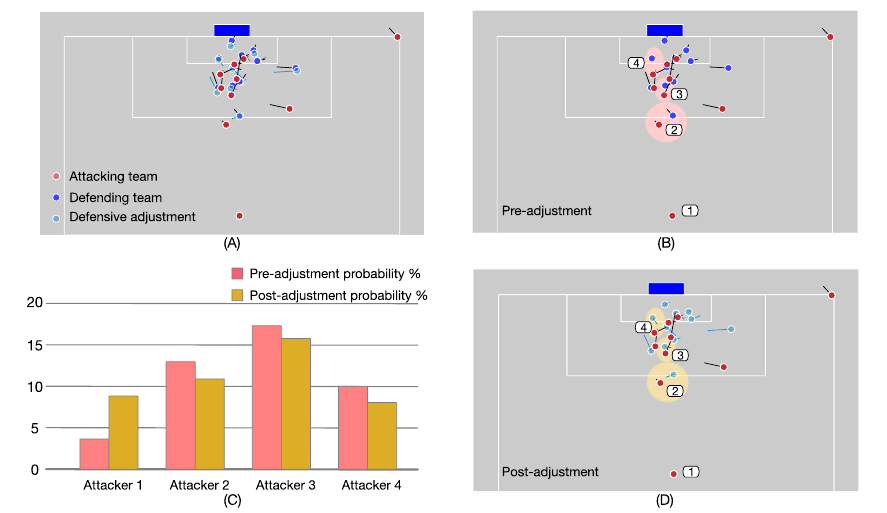
그림 (B)는 실제 슈팅이 나온 상황입니다. 그림 (D)는 TacticAI가 추천해준 수비 전술 조정입니다. 이 둘을 겹쳐서 잘 보이게끔 그림 (A)로도 표현했네요. 이런식으로 실제 코치들이 생성된 다양한 전술 옵션을 시각적으로 확인할 수 있습니다.
그림 (C)를 보면, 수비 전술 조정 후 상대 공격수들의 receiver 확률이 대부분 줄어든 것을 알 수 있습니다. 그런데 Attacker 1의 receiver 확률은 높아졌네요. 만약 박스 내의 수비를 더 강화하는 것을 목적으로 전술을 조정한 것이라면, 박스 밖에서 원터치로 중거리 슈팅을 노리는 공격수는 놓칠 수도 있습니다.
축구에서는 모든 확률을 다 높이거나 다 낮추는 것은 불가능합니다. 그래서 특정 merit를 얻으려고 한다면, 다른 risk가 생기는 것은 자연스러운 현상이죠. Attacker 1의 receiver 확률이 높아진 점에 오해의 소지가 있을 수 있어, 저의 개인적인 의견을 적어봤습니다.
이후, 저자는 TacticAI가 생성한 전술 조정안이 실제 코너킥 데이터와 유사한지 평가했다고 합니다.
200개의 실제 코너킥 데이터와 이에 대한 전술 조정안을 비교해서 MLP 분류기로 평가했습니다. F1-score는 0.53±0.05로 random chance level이었습니다. 즉, 분류기가 생성 데이터와 실제 데이터의 차이를 구별하지 못했다는 것입니다.
그래서 상당히 좋은 성능을 냈다는 것을 밝히고 있구요.
제안된 전술 조정안이 효과적인지 평가하기 위해 shot prediction 기능을 이용했다고 합니다.
그래서 위협적인 슈팅이 발생한 100개의 코너킥 샘플을 분석했습니다. 그리고 shot feature가 0이 되도록 세팅 즉, 슈팅이 안나오게끔 하는 전술 조정안을 생성했습니다.
결과는, 실제 코너킥 장면의 슈팅 확률이 0.75±0.14였던 반면, TacticAI의 수비 전술 조정안을 적용한 경우는 0.69±0.16으로 감소했다고 합니다 (z=2.62, p<0.001).
이와 반대로, 공격팀 입장에서 공격 전술 조정안을 적용하면 슈팅 확률이 올라갔다고 합니다. 0.18±0.16에서 0.31±0.26으로 증가했죠? (z=−4.46, p<0.001).
이를 통해 TacticAI의 전술 조정안의 효과를 알 수 있습니다.
Case study with expert raters
위에서는 TacticAI의 수치적인 평가가 좋았다는 것을 알 수 있었습니다. 그러나 이 모델을 상용화하려면 전문가들의 평가가 뒤따라야 할 겁니다. 그래서 이를 위해 Liverpool FC (LFC)의 전문가들과 case study를 통해 평가를 했다고 합니다.
구제척으로 5명의 전문가들과 함께 진행했는데요,
데이터 과학자 3명, 비디오 분석가 1명, 코치 1명으로 구성되었습니다.
총 4가지의 task를 진행했습니다.
(1) TacticAI의 전술 조정 제안의 현실성
(2) TacticAI의 receiver prediction의 타당성
(3) TacticAI의 유사 코너킥 상황 검색에 대한 효율성
(4) TacticAI의 전술 조정 제안의 유용성
먼저 (1)과 (2)를 동시에 진행했습니다.
50개의 코너킥 샘플을 준비하고, 평가자들에게 주어진 샘플이 실제인지, TacticAI가 생성한 것인지 구별하도록 요청했습니다. 그리고 코너킥 샘플에서 공을 받는 선수가 누구일지(receiver) 명시해보라고 요청했습니다.
real vs generated samples task에서 평가자들의
F1-score는 0.64±0.04(개인 점수: F1_A=0.54, F1_B=0.64, F1_C=0.65, F1_D=0.62, F1_E=0.56)에 불과했습니다.
이 말인 즉슨, 실제와 모델의 생성 코너킥을 구별하기 어려웠다라는 것입니다.
identifying receivers task에서는 평가자들이 고른 receiver가 TacticAI가 고른 receiver top-3 안에 들면 맞춘 것으로 정했습니다.
이때, 정확도는 0.79±0.18였습니다. 이는 TacticAI 개발 단계에서 따로 빼놓은 test-data에서 기록한 정확도와도 유사합니다.
따라서 평가로 얻은 결과는 TacticAI의 기본적인 성능과도 잘 부합한다는 것을 알 수 있습니다.
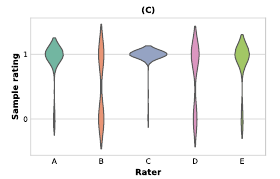
이 그림은 5명의 평가자들이 예측한 receiver 분포가 통계적으로 유의미하게 다름을 알려주는 그림입니다.
구체적으로는, 사람 평가자들이 예측한 receiver들 사이의 유사도를 ANOVA 검정으로 분석했습니다. 그 결과를 보여주는 그림입니다.
즉, 이를 통해 Liverpool FC (LFC)에 속한 전문가들은 직책에 따라 보는 관점 혹은 기준이 다르다는 것을 알 수 있습니다.
이것이 중요한 포인트인데, 이렇게 관점 혹은 기준이 다름에도 불구하고 TacticAI가 높은 top-3 정확도를 보였다는 것은 코너킥 전술의 핵심 패턴을 잘 파악했고 전문가들의 선호와 잘 맞아떨어졌다라는 뜻입니다.
이제 (3)을 보겠습니다.
50쌍의 코너킥을 준비합니다, 각 쌍의 코너킥은 기준 코너킥 1개, 검색된 코너킥 1개로 구성됩니다. 평가자들은 각 쌍의 코너킥을 보고 유사하다고 판단되면 점수를 주는 방식으로 평가했습니다.
먼저, baseline 모델과 TacticAI의 비교를 중점으로, 평가했다고 합니다.
baseline 모델은 어떤 것을 말하는 지 잘 모르겠네요. 기존에 사용되었던 모델이거나, 딥러닝 뼈대의 기본 모델이라고 개인적으로 생각합니다.
어쨌든, baseline의 점수는 0.36±0.10, TacticAI의 점수는 0.59±0.09였습니다.
이를 통해 TacticAI는 상대 팀의 전술을 분석하는 강력한 도구가 될 수 있음을 시사한다고 합니다.
이후, 평가자들 간의 대답 일치도를 평가했다고 합니다.
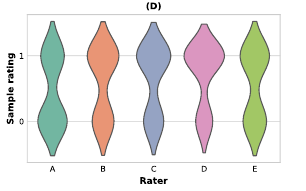
이 그림에서 알 수 있듯이, 5명의 평가자들이 TacticAI의 성능에 대해 대체로 비슷한 평가를 했음을 알 수 있죠.
마지막 (4)입니다.
평가자들에게 마찬가지로 50쌍의 코너킥 샘플을 보여줍니다.
각 쌍의 코너킥은 기준 코너킥 1개, TacticAI의 조정안 1개로 구성됩니다.
평가자들은 코너킥이 의미있게 조정되었으면 점수를 주는 방식으로 평가했습니다.
5명의 평가자들의 평균 점수는 0.7±0.1였습니다.
또한, 50쌍 중에서 45쌍의 코너킥 상황에서 평가자들의 과반수가 모델의 조정안을 긍정적으로 평가했다고 합니다.
여기에 추가로, 5명의 평가를 평균하고 그 평균값이 0보다 큰지 t-test(t-검정)까지 실시했다고 하네요.
그 결과, 유의미한 긍정적 반응(t_49=9.20, p<0.001)이라는 것을 알 수 있었답니다.
사실, 이 부분도 논문을 읽으면서 인상깊었네요. 평가의 신뢰성, 타당성을 주기 위해 여러가지 방면에서 검정을 실시하는 부분이요. 제 생각보다 더 디테일하게 평가합니다.
다시 돌아와서, 여기서도 평가자 간 대답 일치도까지 검정하니, 모두 일관된 긍정적 반응이었다고 합니다. 이렇게 서로 다른 배경과 직책을 지닌 전문가들 사이에서도 모델의 전술 제안 능력이 유용하다고 인정받은 것이죠.
그래서 평가자들이 선정한 가장 의미있는 전술 조정 제안 4개를 그림으로 첨부합니다.
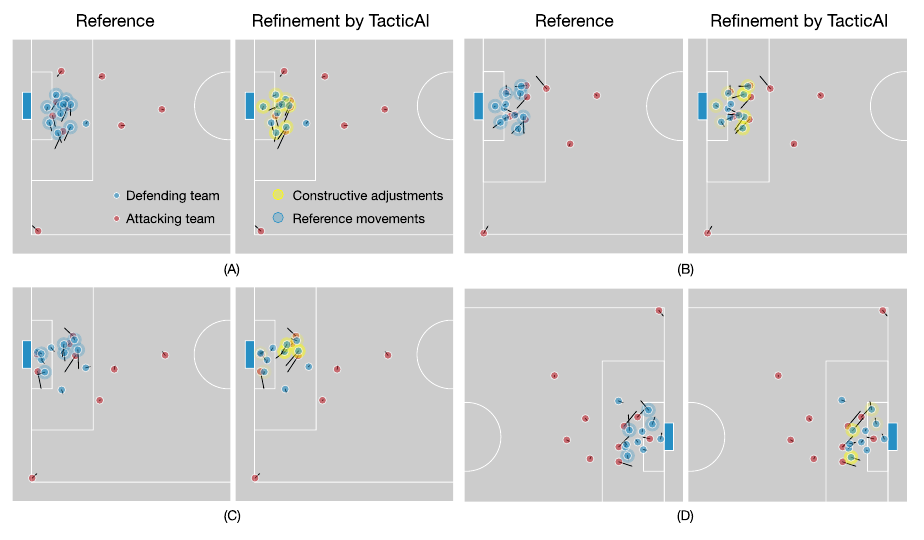
노란 원 밀도 표시가 TacticAI가 조정한 위치입니다. 이러한 조정들을 평가자들이 긍정적으로 평가했다고 합니다.
Discussion
이렇게 TacticAI의 구조와 그 성능까지 알아보았습니다.
정리해보면,
TacticAI는 receiver prediction, shot prediction, guided generation, retreival system의 기능을 탑재하고 있고, 지금까지의 연구를 통해 그 성능을 확인할 수 있었습니다. 또한, 디테일한 축구 지식 혹은 복잡한 특성 공학을 크게 필요로 하지 않습니다.
이어서, TacticAI는 스로인 상황이나 프리킥 상황처럼 다른 세트피스 상황에서도 활용될 가치가 있습니다. 추가로, 경기 흐름이 중단되는 룰이 있는 다른 스포츠에서도 활용할 수 있다고 하네요. 농구의 드로인 상황이 그 예시가 될 수 있겠네요.
그러나 저자는 한계 또한 언급하는데요. 딥러닝 분야에서 항상 나오는 문제이죠. 바로 데이터 품질입니다. 고품질 데이터는 빅 리그(최상위 리그: EPL, Laliga 등)에서만 얻을 수 있다는 것입니다. 방송용 영상을 사용하면, 데이터 범위를 늘릴 수 있지만, 노이즈가 증가할 수 있다는 단점이 있구요.
다시 돌아와서, TacticAI의 전체적인 구조는 향후 자연어 인터페이스(NLP 인터페이스)와의 통합 연구에도 기반을 마련해 준다고 합니다. 저는 아직 NLP를 배우지 않아 어떤 유사도가 있는지 자세하게는 모르겠습니다.
마지막으로, 저자는 TacticAI가 차세대 축구 전술 AI 어시스턴트의 기반을 마련했다고 믿습니다.
이렇게 리뷰가 끝이 났습니다..
분량이 많고, 이해도 완벽하지 않아 글이 상당히 길어진 것 같습니다.
이 논문은 모델을 구성하는 수학적 개념과 이론적 배경은 잘 설명해 놓았다고 생각합니다. 그러나 상업적 이유 때문인지, 연구 과정의 code는 공개하지 않고 있다고 합니다. 당연한 부분입니다만, 개인적으로 이 부분이 아쉽게 느껴졌습니다. 2023년에 쓰여진 논문인데, 현재 상업화가 되었는지는 잘 모르겠습니다. 구글 딥마인드가 리버풀과 혁력하여 만든 모델인데, 성능 자체는 좋을 것으로 예상되네요.
Github에 GNN 기반의 축구 분석 코드가 있는지 찾아보고 있는데, 이와 관련해서도 찾은 정보가 있으면 포스팅해보도록 하겠습니다.
읽어주셔서 감사합니다.
