0. INTRO
-
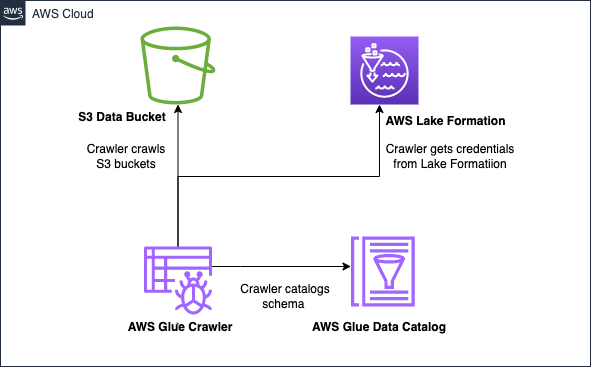
Glue Crawler 생성할 때 Lake formation 자격증명 설정을 통해 동일한 혹은 다른 AWS 계정 내의 기본 Amazon S3 위치가 있는 데이터 카탈로그 테이블 또는 Amazon S3 데이터 스토어에 액세스하도록 크롤러를 구성할 수 있다.
-
이 과정에서 Lake Formation 쪽에 몇가지 설정이 필요한데 이번 글에서는 간단하게 해당 설정 후 크롤러 생성하는 과정을 알아보도록 할 것이다.
1. Lake Formation 설정
-
우선 AWS 공식 DOCS에 해당 과정을 수행하는데 필요한 조건들이 간략히 나열되어 있다.
크롤러가 Lake Formation 자격 증명을 사용하여 데이터 스토어 또는 데이터 카탈로그 테이블에 액세스할 수 있도록 하려면 Lake Formation에 데이터 위치를 등록해야 합니다. 또한 크롤러의 IAM 역할에는 Amazon S3 버킷이 등록된 대상에서 데이터를 읽을 수 있는 권한이 있어야 합니다.
-
Docs에서 말한 조건은 아래 두 가지 이다.
- Lake Formation에 데이터 위치를 등록
- S3 위치의 데이터를 읽을 수 있는 IAM 권한
1. S3 위치의 데이터를 읽을 수 있는 IAM 권한 등록
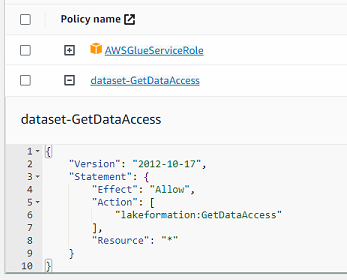
- IAM에서 Glue Crawler 수행을 위한 Role을 만들면
AWSGlueServiceRole권한 하나만 등록되어 있는 것을 볼 수 있다. - 여기에 추가적으로 아래의 권한을 inline policy로 추가하여 연결해주어야 Lake Formation쪽에 등록되어있는 S3 경로에 접근이 가능하다. (Docs)
{ "Version": "2012-10-17", "Statement": { "Effect": "Allow", "Action": [ "lakeformation:GetDataAccess" ], "Resource": "*" } } - 아래 사진과 같이
AWSGlueServiceRole과 따로 설정하여 넣은 inline 권한 이렇게 두 개가 들어간 Role이 만들어진다.
2. Lake Formation에 데이터 위치 등록
-
AWS Lake Formation > Administraion > Data lake location > Register location을 선택하여 Crawling 대상이 되는 Data가 있는 S3 경로를 등록해준다.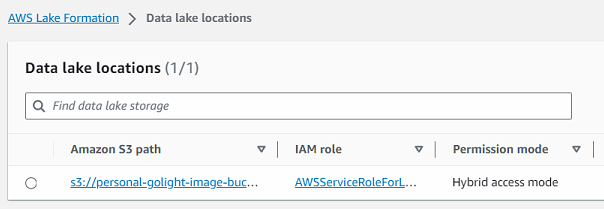
-
AWS Lake Formation > Permission > Data location > Grant를 선택하여 위에서 만든 IAM 역할에 대해 Register location에서 등록한 S3 경로를 볼 수 있는 권한을 부여한다.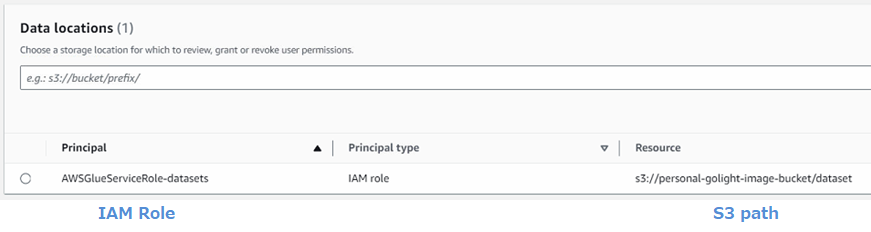
2. Glue Crawler 생성
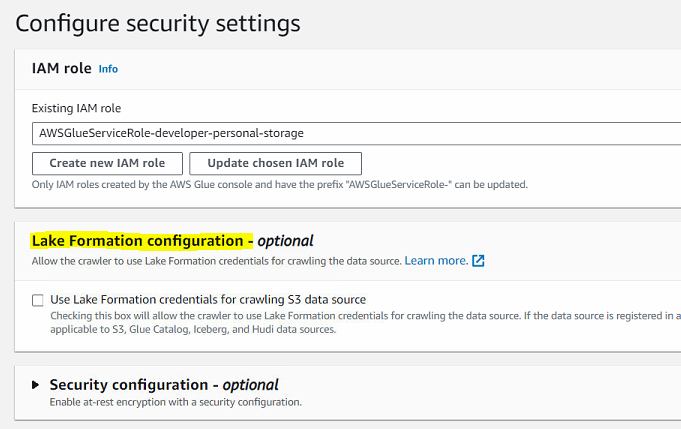
- 위의 Lake Formation 설정 과정을 거친 후, 생성한 Role을 Glue Crawler에 등록하여 생성하게 되면
Lake Formation configuration설정을 선택하여 에러가 나지 않고 Crawler가 잘 만들어지게 된다. - 또한 이렇게 생성된 Crawler는 IAM이 아닌 Lake Formation에서 설정한 권한들에 영향을 받으며 접근 제어가 들어가기 때문에 관리하기에 용이하다.
에러 발생시 참고 Docs -> Troubleshoot Docs
