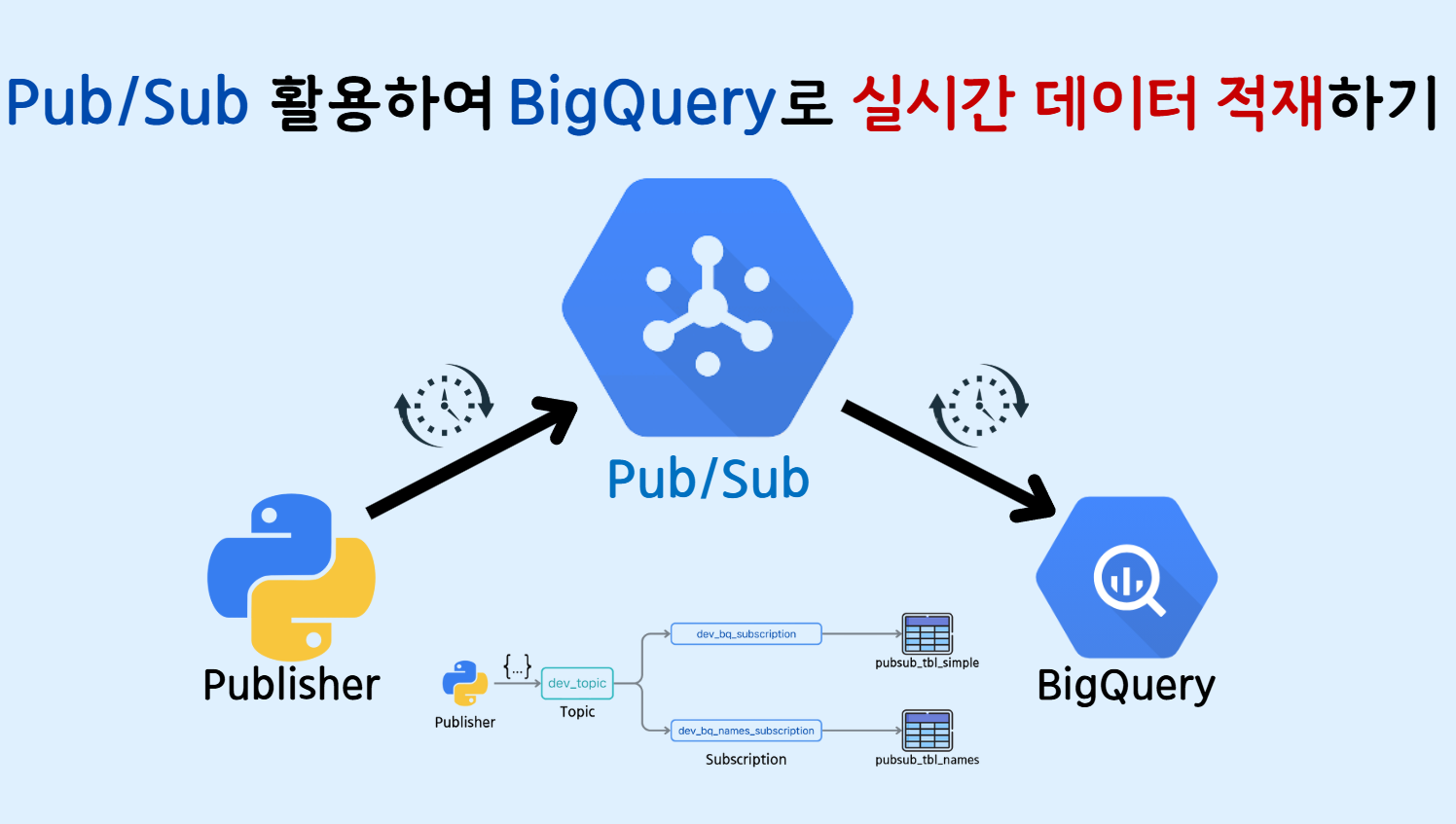
🔹 0. INTRO
- 이전 글 'Google Cloud Pub/Sub 서비스의 핵심 개념과 실습 튜토리얼'에서는 Pub/Sub 서비스의 기초적인 내용을 살펴보았습니다. 이번 글에서는 Pub/Sub 토픽으로 전송된 메시지를 읽어 BigQuery 테이블에 직접 저장하는 방법을 다뤄보겠습니다.
🔹 1. BigQuery 테이블 생성
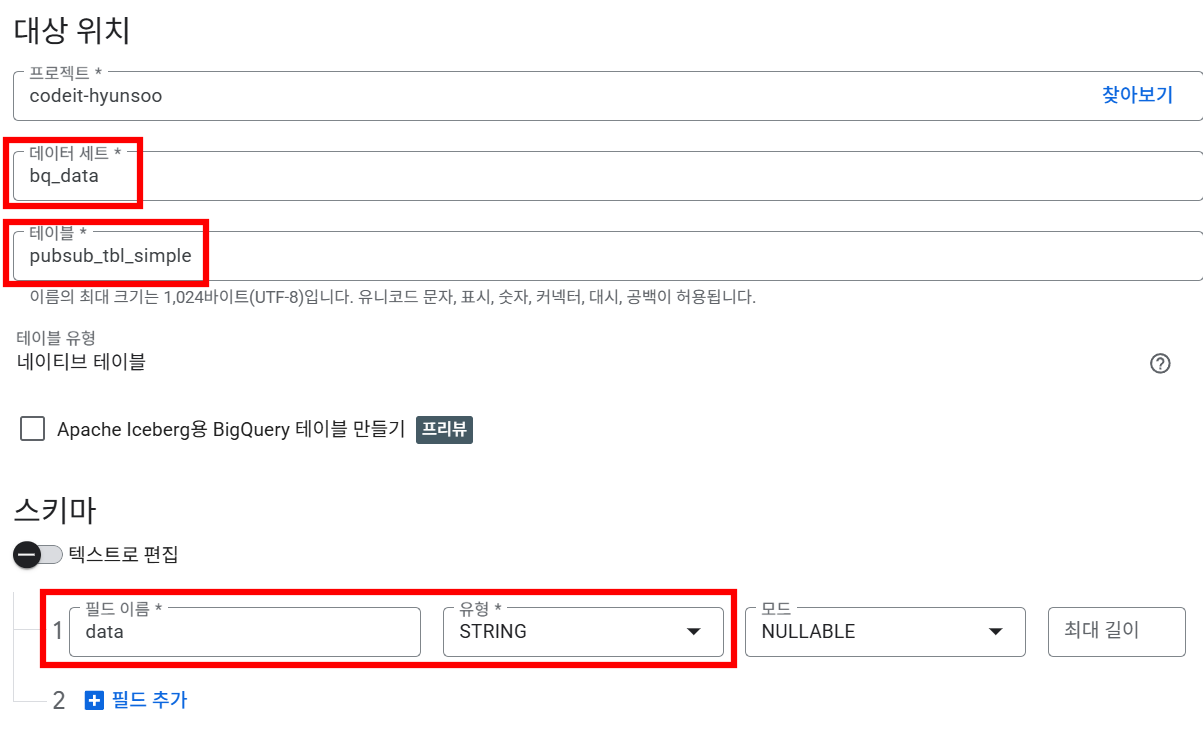
▪ 1) 단일 스키마
-
토픽으로 전송되는 메세지를 저장할 수 있는 빅쿼리 테이블을 생성합니다. 이 때 구독 유형 중
스키마 사용 안함옵션을 선택하게 되면data라는 컬럼 하나가 있는 테이블의 row에 토픽에서 읽은 메세지가 저장됩니다.

-
BigQuery의
bq_data데이터셋에data컬럼 하나만 있는pubsub_tbl_simple테이블을 생성합니다.
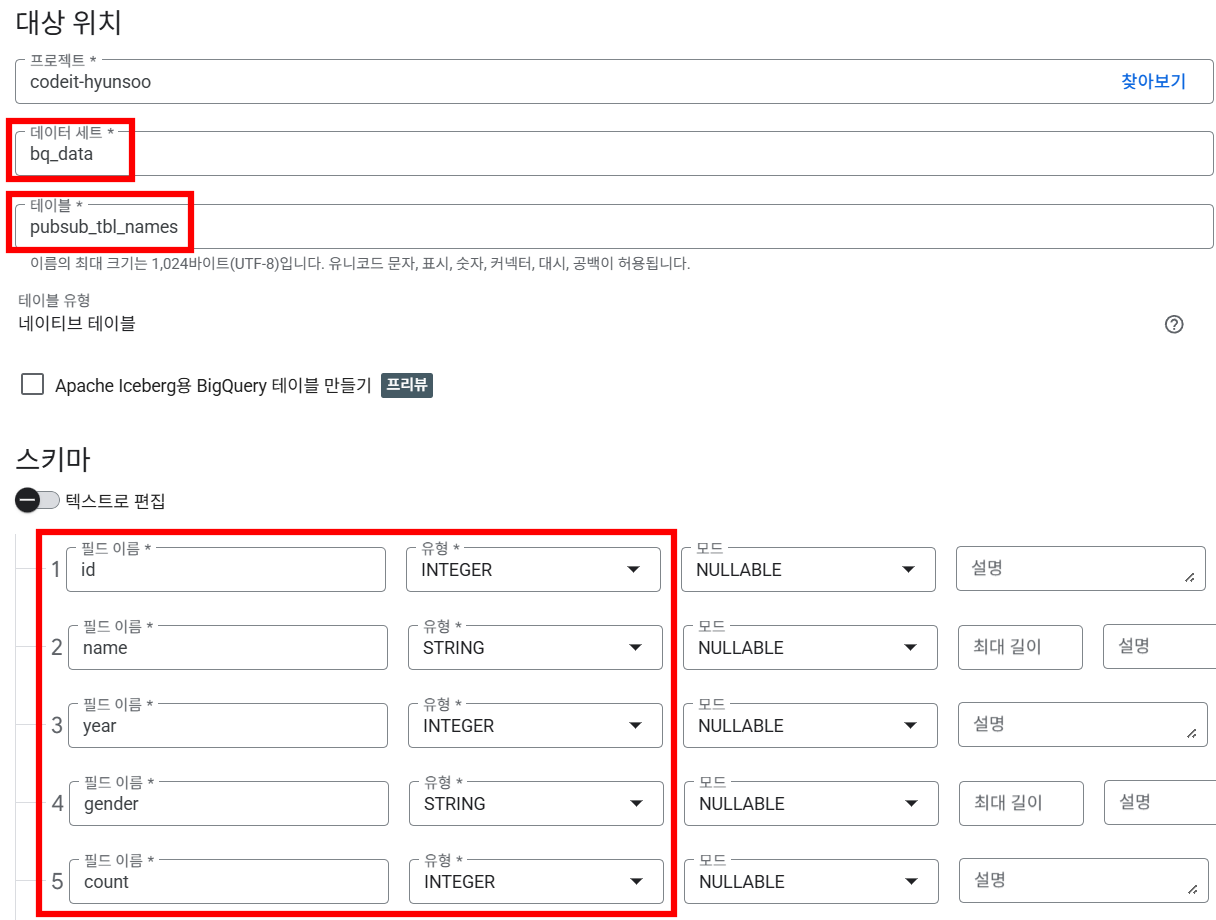
▪ 2) 커스텀 스키마
- 구독 유형에서
테이블 스키마 사용옵션을 선택하면, 생성한 BigQuery 테이블의 스키마에 맞춰 토픽으로 데이터를 전송할 수 있고, 구독은 해당 데이터를 읽어 BigQuery 테이블에 적재합니다.

- 이번 실습에 사용할 테이블은 'Baby Names by year' 데이터셋이며, 스키마는 아래와 같습니다.(살짝 수정)
id int64 name object year int64 gender object count int64 - 실습을 위해 동일한 스키마를 가지는
pubsub_tbl_namesBigQuery 테이블을 생성합니다.
🔹 2. 구독 생성
- 구독의 유형에는 아래 네가지 종류가 있습니다.
가져오기: 메세지를 읽어오기푸시: 메세지를 다른 Endpoint URL로 전송BigQuery에 쓰기: 메세지를 BigQuery 테이블에 저장Cloud Storage에 쓰기: 메세지를 GCS 파일 객체로 저장
그 중 BigQuery에 쓰기 유형의 구독을 생성하여 토픽에 들어오는 데이터를 실시간으로 읽어와 BigQuery 테이블에 저장해보도록 하겠습니다.
Google Pub/Sub 서비스의 토픽·발행자·구독자의 개념 및 토픽 생성 방법은 이전 글(링크)을 참고하시면 됩니다.
생성할 구독은 총 2가지로,
1) 단일 스키마 테이블인 pubsub_tbl_simple로 전송하는 구독
2) 커스텀 스키마 테이블인 pubsub_tbl_names로 전송하는 구독
이렇게 생성합니다.
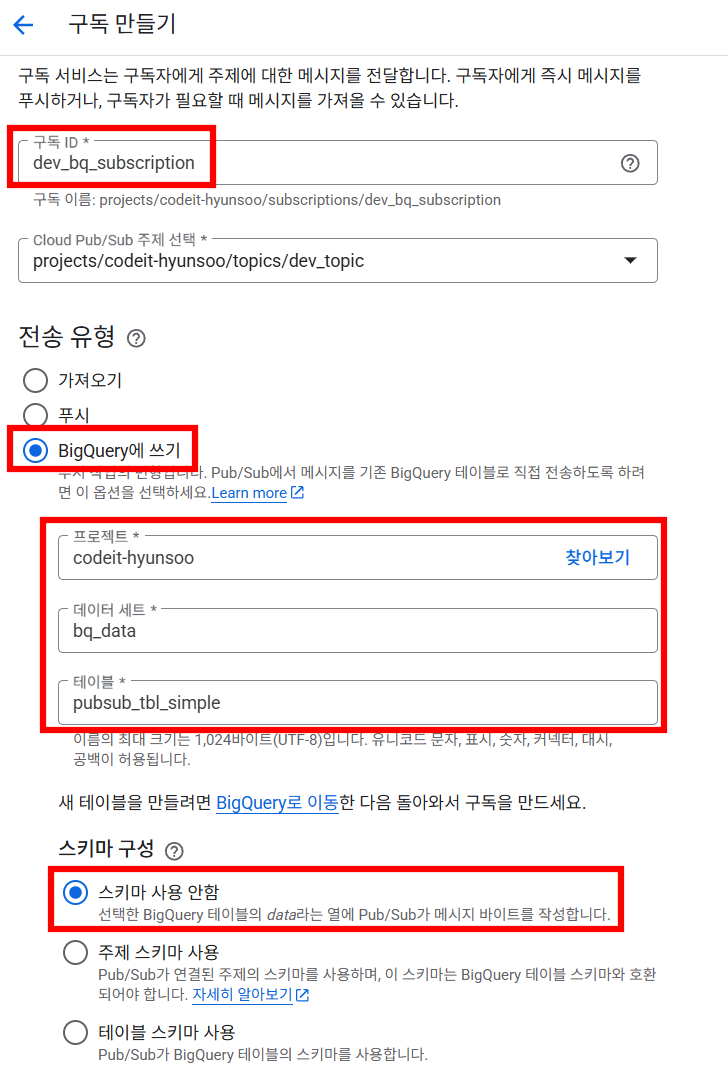
▪ 1) 단일 스키마 테이블에 쓰기
- 위에서 생성한 테이블 중
data라는 컬럼 하나를 가진pubsub_tbl_simple테이블로 데이터를 전송하는 구독을 생성해보겠습니다.- 구독ID :
dev_bq_subscription - 전송 유형 :
BigQuery에 쓰기 - 스키마 구성 :
스키마 사용 안함
- 구독ID :
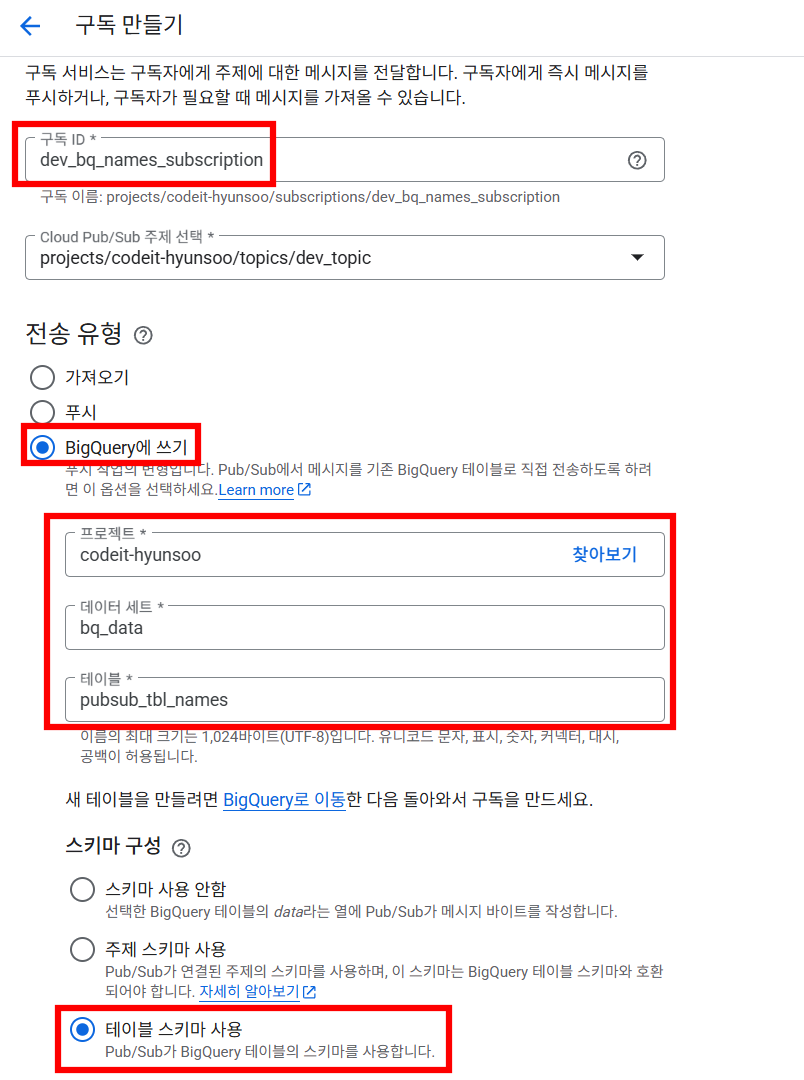
▪ 2) 커스텀 스키마 테이블에 쓰기
- 5개의 컬럼을 가진
pubsub_tbl_names테이블로 데이터를 전송하는 구독을 생성합니다.- 구독ID :
dev_bq_names_subscription - 전송 유형 :
BigQuery에 쓰기 - 스키마 구성 :
테이블 스키마 사용
- 구독ID :
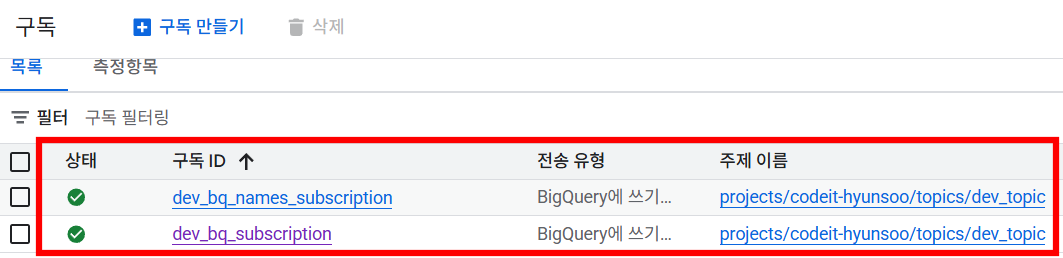
토픽에 들어온 데이터를 받아 각 테이블들로 저장해줄 구독 2개 생성이 완료되었습니다.
🔹 3. 실시간 메세지 전송
- 위에서 생성한 토픽과 구독, BigQuery 테이블의 관계는 아래와 같습니다.
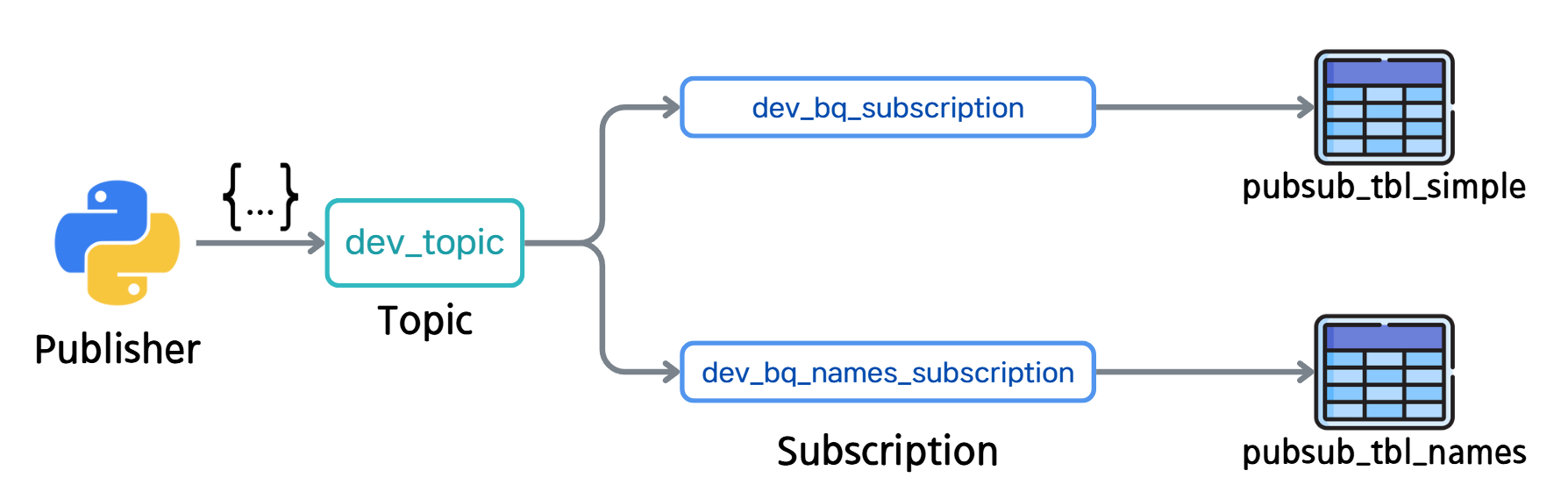
- names 데이터셋을 JSON 형식으로
dev_topic토픽에 전송하였을 때, 빅쿼리 테이블들에 어떤식으로 데이터가 적재되는지 확인해보도록 하겠습니다.
▪ 1) 토픽에 메세지 전송
- 파이썬 코드를 통해
dev_topic토픽으로 데이터가 3초에 한 번씩 전송되도록 합니다.
import pandas as pd
from google.cloud import pubsub_v1
from google.oauth2 import service_account
import json, time
from faker import Faker
## 1. PubSub 토픽 관련 설정
PROJECT_ID = "[프로젝트 ID]"
KEY_PATH = "[서비스 계정 JSON KEY 경로]"
CREDENTIALS = service_account.Credentials.from_service_account_file(KEY_PATH)
TOPIC_ID = "dev_topic"
publisher = pubsub_v1.PublisherClient(credentials=CREDENTIALS)
TOPIC_PATH = publisher.topic_path(PROJECT_ID, TOPIC_ID)
# 2. 보낼 데이터셋을 읽어 JSON 형식으로 변환
df = pd.read_csv('names.csv')
df_dict = df.to_dict(orient='records')
# 3. dev_topic으로 데이터를 3초에 한 번씩 전송
for row in df_dict[:10]:
future = publisher.publish(
topic=TOPIC_PATH,
data=json.dumps(row).encode("utf-8")
)
print(f"보낸 메시지: {row} / 결과: {future.result()}")
time.sleep(3)
--- 출력 결과 ---
보낸 메시지: {'id': 1, 'name': 'Mary', 'year': 1880, 'gender': 'F', 'count': 7065} / 결과: 16021080392424521
보낸 메시지: {'id': 2, 'name': 'Anna', 'year': 1880, 'gender': 'F', 'count': 2604} / 결과: 16021545983015478
보낸 메시지: {'id': 3, 'name': 'Emma', 'year': 1880, 'gender': 'F', 'count': 2003} / 결과: 16022743523116683
보낸 메시지: {'id': 4, 'name': 'Elizabeth', 'year': 1880, 'gender': 'F', 'count': 1939} / 결과: 16022824001573059
보낸 메시지: {'id': 5, 'name': 'Minnie', 'year': 1880, 'gender': 'F', 'count': 1746} / 결과: 16022962397816275
보낸 메시지: {'id': 6, 'name': 'Margaret', 'year': 1880, 'gender': 'F', 'count': 1578} / 결과: 16022437774262030
보낸 메시지: {'id': 7, 'name': 'Ida', 'year': 1880, 'gender': 'F', 'count': 1472} / 결과: 16021982500229449
보낸 메시지: {'id': 8, 'name': 'Alice', 'year': 1880, 'gender': 'F', 'count': 1414} / 결과: 16022962752184659
보낸 메시지: {'id': 9, 'name': 'Bertha', 'year': 1880, 'gender': 'F', 'count': 1320} / 결과: 16022046604942106
보낸 메시지: {'id': 10, 'name': 'Sarah', 'year': 1880, 'gender': 'F', 'count': 1288} / 결과: 16022147167489566▪ 2) 단일 스키마 테이블 확인
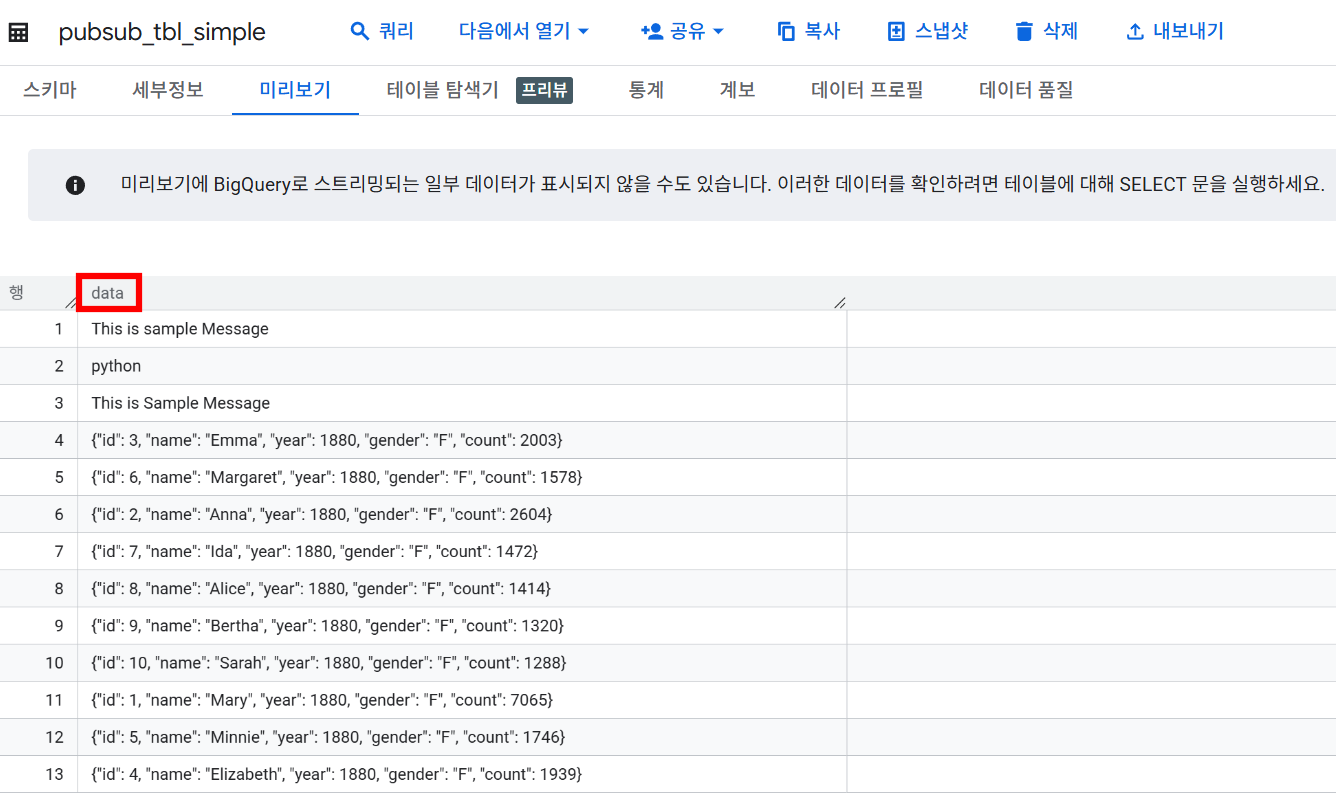
pubsub_tbl_simple테이블의 경우 전송한 JSON 형식의 데이터가data라는 단일 컬럼 안에 STRING 형식으로 저장되는 것을 확인할 수 있습니다. 이렇게스키마 사용 안함유형의 구독은 추후 분석을 위해 테이블에 대한 추가적인 가공이 필요하며, 정형 데이터보다는 비정형이나 TEXT 형태의 데이터를 실시간으로 저장할 때 유용하게 쓰일 수 있을 것 같습니다.
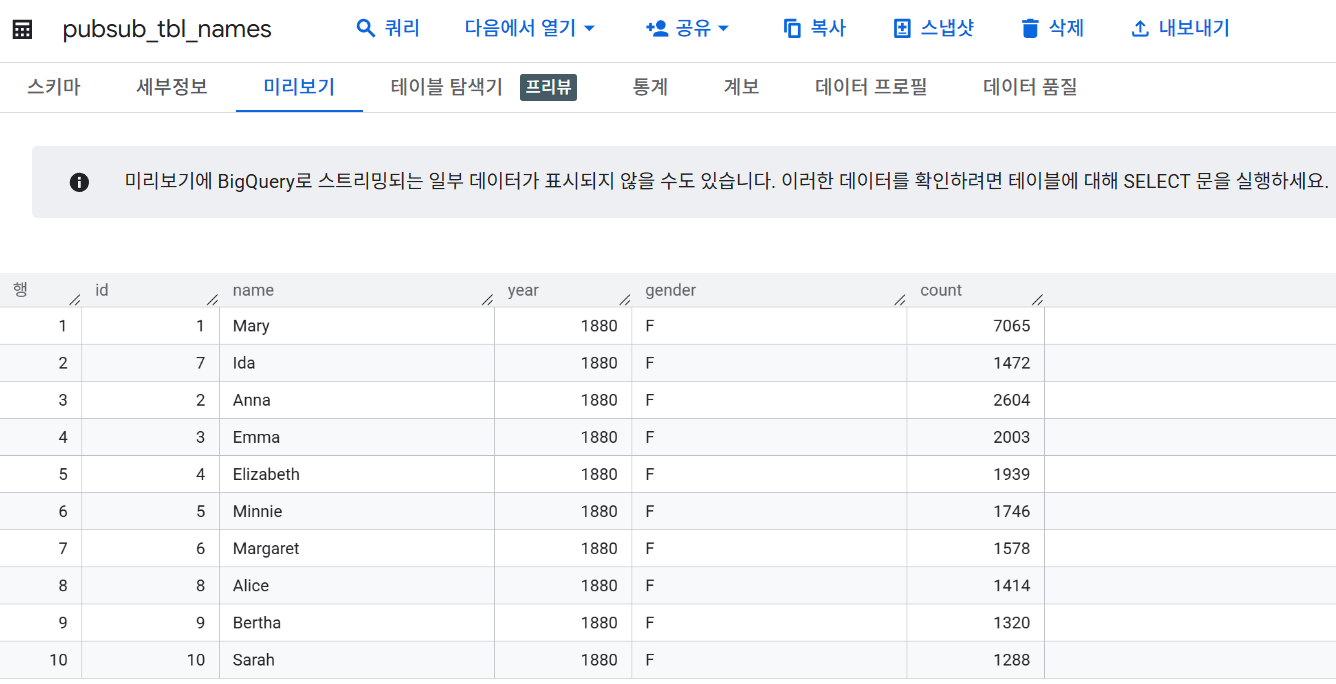
▪ 3) 커스텀 스키마 테이블 확인
pubsub_tbl_names테이블의 경우 테이블 스키마에 맞게 데이터를 전송하면 각 컬럼에 해당 값이 실시간으로 저장되어 분석에 용이한 정형 데이터 테이블 형태로 관리할 수 있습니다.
🔹 4. OUTRO
- 이번 글에서는 토픽으로 받은 메시지를 BigQuery 테이블로 직접 적재하는 방식과 스키마 적용 여부에 따른 차이까지 살펴보았습니다. Pub/Sub의 경우 GCP의 서비스이기 때문에 GCS, 빅쿼리, Data Fusion 등 클라우드 내 서비스들과 원활하게 통합되어 사용된다면 훨씬 더 큰 시너지를 낼 수 있을 것이라 생각합니다.
- 앞으로는 Pub/Sub의 실시간성을 어떻게 데이터 파이프라인 아키텍처에 반영할지 고민해 보는 것이 중요할 것 같습니다.

데이터 엔지니어의 작업공간 / #PYTHON #CLOUD #SPARK #AWS #GCP #NCLOUD