[K8S] Sidecar container를 사용하여 쿠버네티스 환경에서 Jupyter Lab의 데이터를 Cloud Storage와 연동하기
DOCKER-KUBERNETES
목록 보기
7/11
0. INTRO
- 쿠버네티스에서 데이터를 저장하기 위한 방법에는 여러가지가 있다.(쿠버네티스에서 Volume을 공유하기 위한 방법들 (Volume, PV, PVC, StorageClass)) emptydir를 사용하여 임시로 데이터를 저장할 수도 있고 PV나 NFS 등의 스토리지를 이용하여 더 안전하고 오래 저장하는 방법도 있을 것이다.
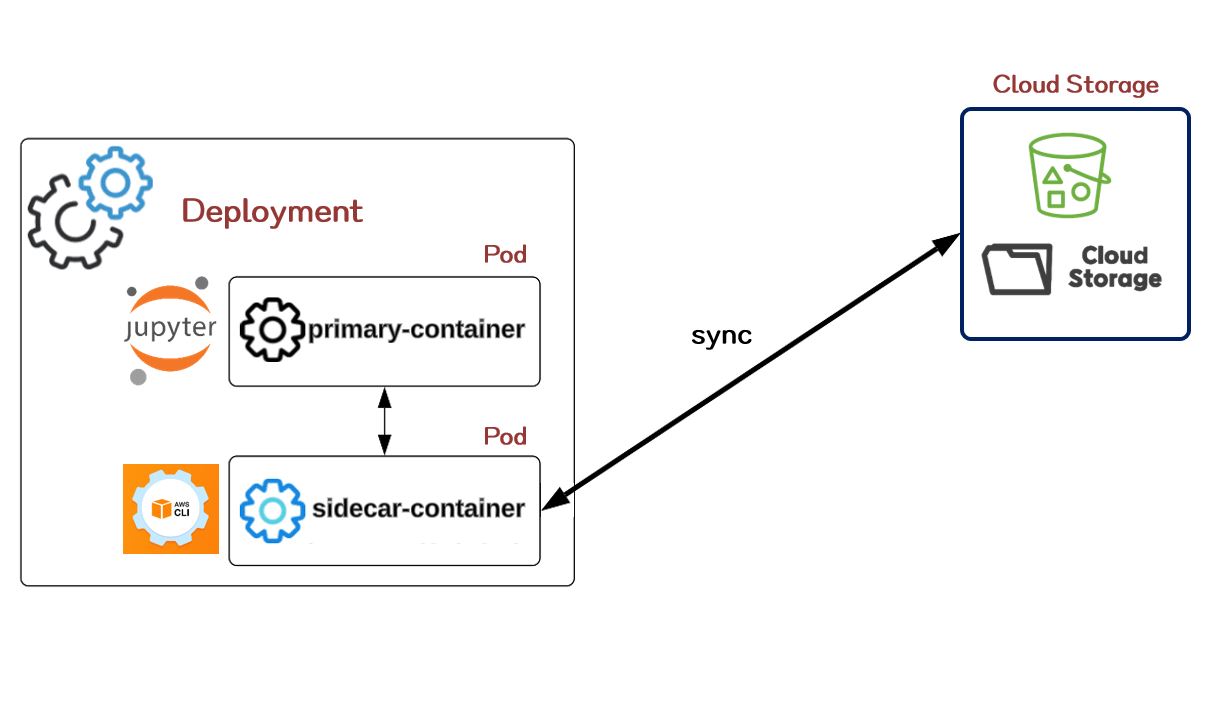
- 그 중에서 이번 글에서 다뤄볼 내용은 데이터를 AWS S3나 Ncloud Object Storage와 같은 Cloud Storage에 데이터를 저장하고 또 변경사항들이 특정 시간이 지나면 지속적으로 반영될 수 있도록 Main Container 옆에 Sidecar Container를 하나 구성해볼 것이다.
- 조금 더 자세히 설명하자면 Jupyter Lab을 Deployment를 통해 올리고 해당 서비스 옆에서 지속적으로 작동되는 sidecar container를 같이 만들어 Cloud Storage 상의 특정 경로와 Jupyter Lab의 특정 경로가 지속적으로 연동되어 데이터가 반영될 수 있도록 하는 것이다.
1. Sidecar pattern에 대하여 (explained by ChatGPT)

- 쿠버네티스에서 Sidecar pattern과 Sidecar container는 컨테이너 기반의 마이크로서비스 아키텍처에서 매우 중요한 개념으로 서비스 컨테이너와 함께 작동하여 다양한 기능을 추가하거나 보완해주는 역할을 한다.
Sidecar 패턴
-
정의 : Sidecar 패턴은 마이크로서비스 아키텍처에서 주요 서비스 컨테이너와 별개로 실행되는 작은 보조 컨테이너를 가리킵니다. 이 보조 컨테이너는 주요 서비스 컨테이너와 함께 동일한 파드 내에서 실행되며, 주로 서비스에 추가 기능을 제공하거나 특정 기능을 분리합니다.
-
용도
- 로그 수집 및 모니터링 : Sidecar 컨테이너는 로그 또는 메트릭 데이터 수집을 담당하여 서비스 컨테이너를 깔끔하게 유지하고, 중앙 집중식 모니터링 도구로 데이터를 전송합니다.
- 보안 : 보안 관련 기능을 제공하며, 서비스 컨테이너를 보호하고 암호화, 인증, 접근 제어 등을 수행합니다.
- 스케일링 : Sidecar 컨테이너는 주요 서비스 컨테이너와 함께 자동으로 스케일링되어 부하를 분산하거나 특정 작업을 처리합니다.
Sidecar 컨테이너
-
정의 : Sidecar 컨테이너는 주요 서비스 컨테이너와 동일한 파드 내에서 실행되는 보조 컨테이너로, 주로 특정 기능을 제공하기 위해 사용됩니다.
-
용도
- 로그 수집 : 주요 서비스 컨테이너의 로그를 수집하고 중앙 집중식 로그 저장소로 전송합니다.
- 모니터링 : 주요 서비스 컨테이너의 메트릭 및 상태를 모니터링하여 중앙 집중식 모니터링 시스템으로 보냅니다.
- 보안 : 주요 서비스 컨테이너를 위한 보안 기능을 추가하고, 인증, 권한 부여, 암호화를 처리합니다.
- 스케일링 : 부하 분산 및 트래픽 라우팅과 같은 스케일링 관련 작업을 처리합니다.
2. Jupyter Lab Deployment + Service 작성
- Cloud Storage와 통신할 수 있는 hadoop-aws 등의 패키지와 pyspark가 설치되어있는 Jupyter Lab custom Docker Image인
hyunsoolee0506/pyspark-jupyter:3.5.0를 사용할 것이다. - 볼륨은 일단 임시적으로 emptyDir 타입으로 설정해준다.
- Service의 경우 기본적으로 export 되어있는 8888포트와 동일한 8888로 매핑을 해주며 NKS에 alb-controller가 설치된 환경이기 때문에 LoadBalancer 타입으로 설정해준다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: jupyter-deployment
spec:
selector:
matchLabels:
app: jupyter
replicas: 1
template:
metadata:
labels:
app: jupyter
spec:
containers:
- name: jupyter-container
image: hyunsoolee0506/pyspark-jupyter:3.5.0
ports:
- containerPort: 8888
volumeMounts:
- name: s3-data
mountPath: /home/jovyan/work
volumes:
- name: s3-data
emptyDir: {}
---
apiVersion: v1
kind: Service
metadata:
name: jupyter-service
labels:
app: jupyter
spec:
type: LoadBalancer
selector:
app: jupyter
ports:
- protocol: TCP
port: 8888
targetPort: 88883. Sidecar Container 코드 작성
- aws credential secret 설정
apiVersion: v1
kind: Secret
metadata:
name: aws-secret-key
stringData:
AWS_ACCESS_KEY_ID: [KEY_ID]
AWS_SECRET_ACCESS_KEY: [KEY_SECRET]- Sidecar container 코드
amazon/aws-cliDocker Image는 AWS CLI를 실행하기 위한 Docker 컨테이너 이미지로 AWS CLI와 관련된 모든 종속성을 포함하고 있으며, 사용자가 Docker를 통해 컨테이너로 실행할 수 있도록 편리하게 패키지된 환경을 제공해준다.- 해당 이미지를 sidecar container의 이미지로 사용하여 Cloud Storage와 Jupyter Lab 경로에 대해 지속적인
aws s3 sync명령을 함으로써 데이터가 지속되고 연동가능하도록 할 수 있다. - 위에서 설정한 secret의 값을 해당 컨테이너의 환경변수로 넘겨주고 spec.spec.args 부분에 s3와 로컬 디렉토리가 sync 될 수 있는 aws cli 코드를 넣어주면 된다. 추가된 sidecar container 코드는 아래와 같다.
jupyter-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: jupyter-deployment
spec:
selector:
matchLabels:
app: jupyter
replicas: 1
template:
metadata:
labels:
app: jupyter
spec:
containers:
- name: jupyter-container
image: hyunsoolee0506/pyspark-jupyter:3.5.0
ports:
- containerPort: 8888
volumeMounts:
- name: s3-data
mountPath: /home/jovyan/work
########################### sidecar container 추가된 부분 ############################
- name: s3-sync
image: amazon/aws-cli
envFrom:
- secretRef:
name: aws-secret-key
command: ["/bin/sh"]
args:
- "-c"
- |
while true; do
aws s3 sync [S3 경로] [컨테이너 내부 경로]
sleep 5;
aws s3 sync [컨테이너 내부 경로] [S3 경로]
sleep 3600;
done
volumeMounts:
- name: s3-data
mountPath: /home/jovyan/work
####################################################################################
volumes:
- name: s3-data
emptyDir: {}kubectl apply -f jupyter-deployment.yaml
- 실행 후 S3 경로와 Jupyter 컨테이너 내부 경로에 대한 sync가 잘 되는지 확인해보면 된다.
4. OUTRO
- 쿠버네티스에 리소스를 올리면서 Sidecar Pattern에 대해서는 활용이 적었는데 이번 실습을 계기로 활용 자유도가 많이 늘어난 느낌이 들었다. 메인 서비스가 하나 떠 있고 그 옆에서 자잘하지만 중요한 작업들을 지속적으로 처리해주는 비서 느낌으로 구동되는 Pod가 하나 있다는게 상당히 효율적이라는 느낌이 들어 앞으로도 종종 활용할 것 같다.

데이터 엔지니어의 작업공간 / #PYTHON #CLOUD #SPARK #AWS #GCP #NCLOUD