[NCP] AWS S3에서 Ncloud Object Storage로 데이터를 이행해올 수 있는 방법들 (Object Migration, Python Function)
Ncloud
목록 보기
1/8
1. 목표
- AWS S3에서 Ncloud Object Storage(이하 NOS)로 효율적이고 안정적으로 데이터를 이행해올 수 있는 방법들에 대해서 알아본다.
2. 로컬에 데이터를 저장하지 않고 이행하는 방법
- AWS 서비스 내에서 동일 계정 혹은 타 계정의 S3간의 데이터 이동은 적절한 IAM 권한 부여만 있다면 awscli의
aws cp명령어를 통해 로컬에 데이터 저장없이 가능하다. Ncloud 역시 AWS 동일한 awscli를 사용하지만 NCP Docs에는 copy 명령어 관련된 내용이 없어 Ncloud에서는 해당 기능 지원이 안되는 것으로 보인다. - Ncloud의
VPC > Object Migration서비스를 사용하여 타 CSP의 Object Storage 데이터를 이관해올 수 있는 솔루션을 제공하고 있다. 사용법은 아주 간단하다.
VPC > Object Migration > Migration 신청클릭- 아래와 같이 포맷을 채워준다.
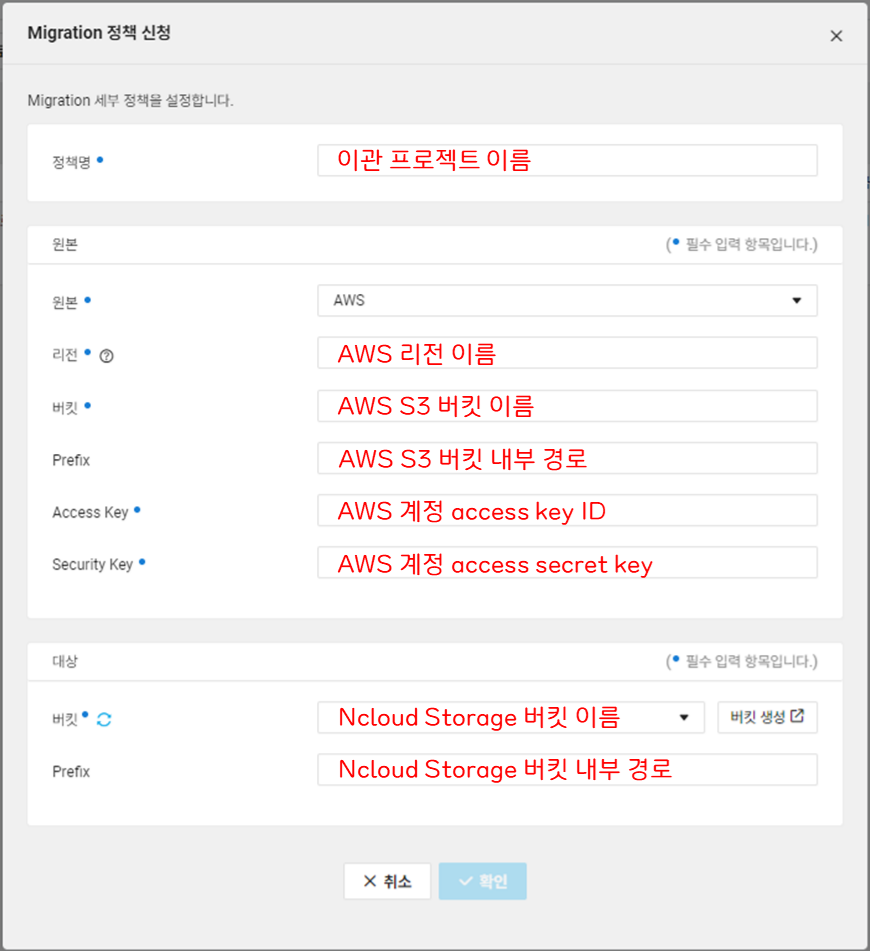
시작을 누르면 S3 -> NOS로 이관이 시작되며 시간이 지나면 이관이 완료된 것을 확인할 수 있다.

3. 로컬에 데이터를 저장한 후 이행하는 방법
- awscli의
sync명령어를 사용하면 데이터가 저장된 폴더 단위로 로컬에 저장 후 해당 폴더 내부 구조를 그대로 유지한 채 다시 NOS로 sync할 수 있다. 따라서 해당 명령어를 사용하여 이행하는 방법이 가장 간편할 것이라 생각된다. - Python을 이용하여 S3 sync 할 수 있는 모듈을 만들어 보았다.
- AWS, NCLOUD에 대한 configure 저장
# 1. AWS 게정에 대한 configure 설정
> aws configure
AWS Access Key ID [****************leLy]: ACCESS_KEY_ID
AWS Secret Access Key [None]: SECRET_KEY
Default region name [None]: ap-northeast-2
Default output format [None]: [Enter]
# 2. Ncloud 계정에 대한 configure 설정
> aws configure --profile ncp
AWS Access Key ID [****************leLy]: ACCESS_KEY_ID
AWS Secret Access Key [None]: SECRET_KEY
Default region name [None]: [Enter]
Default output format [None]: [Enter]- S3 -> NOS 이행 모듈
- AWS 버킷 내부 경로와 동일하게 NOS 경로가 생성되며 데이터가 이관된다.
default_path에 명시된 로컬 디렉토리에 데이터가 임시로 저장된다.
import subprocess, os, shutil, sys, time
def get_size(start_path):
total_size = 0
fin = ''
for dirpath, dirnames, filenames in os.walk(start_path):
for f in filenames:
fp = os.path.join(dirpath, f)
total_size += os.path.getsize(fp)
if total_size == 0:
return 'Directory is empty'
size_suffixes = ['B', 'KB', 'MB', 'GB', 'TB']
size_suffix_index = 0
while total_size > 1024 and size_suffix_index < len(size_suffixes) - 1:
total_size /= 1024
size_suffix_index += 1
return '{:.2f} {}'.format(total_size, size_suffixes[size_suffix_index])
def aws_sync_to_ncp(aws_path, ncp_bucket, remain_data: bool = False):
"""
aws_path : 이행 데이터 위치 S3 URI
ncp_bucket : 이행될 Naver Object Storage 버킷 이름
remain_data : 이행 후 로컬 데이터 삭제가 Default, 로컬 데이터 남기고 싶으면 True
"""
default_path = "/root/aws_sync_storage"
# S3 버킷 내부 경로 생성
aws_prefix = '/'.join([i for i in aws_path.split('/') if i][2:])
# S3 버킷 내부 경로와 동일하게 NOS 버킷의 내부 경로 생성
ncp_path = '/'.join(['s3:/', ncp_bucket, aws_prefix])
# S3 버킷 내부 경로와 동일하게 로컬 내부 경로 생성
local_path = os.path.join(default_path, aws_prefix)
# S3 -> 로컬로 데이터 sync하여 저장
aws_cli = [
'aws',
's3',
'sync',
aws_path,
local_path
]
# 로컬 -> NOS로 데이터 sync하여 저장
ncp_cli = [
'aws',
's3',
'sync',
local_path,
ncp_path,
'--endpoint-url=https://kr.object.ncloudstorage.com',
'--profile',
'ncp'
]
start_time = time.time()
processes = [[aws_cli, 'AWS'], [ncp_cli, 'NCP']]
for process, csp in processes:
try:
result = subprocess.run(process, check=True, stdout=subprocess.PIPE, text=True)
# CLI 실행 후 output이 보고 싶으면 output 변수 print
output = result.stdout
return_code = result.returncode
except subprocess.CalledProcessError as e:
print(f"{csp}CLI ERROR: {e}")
sys.exit(1)
total_time = time.localtime(time.time()-start_time)
total_size = get_size(default_path)
if not remain_data:
shutil.rmtree(default_path)
os.mkdir(default_path)
print("="*100)
print("="*100)
print("DATA HAS BEEN SUCCESSFULLY TRANSFERED FROM S3 TO NAVER OBJECT STORAGE")
print("="*100)
print(f"S3 DATA PATH : {aws_path}")
print(f"NOS DATA PATH : {ncp_path}")
print(f"TRANSFERED DATA SIZE : {total_size}")
print(f'TOTAL TRANSFER TIME : {total_time.tm_min} 분 {total_time.tm_sec} 초')
print("="*100)
print("="*100)
if __name__ == "__main__":
# NOS로 이행해올 S3 데이터 폴더 경로
aws_path = 's3://developer-personal-storage/aaaaa/bbbbb/'
# NOS 버킷 이름
ncp_bucket = 'data-storage'
aws_sync_to_ncp(aws_path, ncp_bucket)- 출력 결과
====================================================================================================
====================================================================================================
DATA HAS BEEN SUCCESSFULLY TRANSFERED FROM S3 TO NAVER OBJECT STORAGE
====================================================================================================
S3 DATA PATH : s3://developer-personal-storage/aaaaa/bbbbb/
NOS DATA PATH : s3://data-storage//aaaaa/bbbbb
TRANSFERED DATA SIZE : 1.41 MB
TOTAL TRANSFER TIME : 0 분 2 초
====================================================================================================
====================================================================================================4. OUTRO
-
Object Migration서비스와 개인적으로 만든 Python 모듈 모두를 사용해봤을 때 아래와 같은 차이점들을 알 수 있었다.비교 항목 Object Migration Python Module 속도 적은 양의 데이터의 경우 보통속도,
데이터 양이 많을수록 상대적으로 빠름데이터 양이 적으면 빠름,
데이터 양이 많을수록 Object Migration에 비해 상대적으로 느려짐편의성 쉬움 보통 유연성 X O 활용 특정 경로 이하 모든 데이터 이행 이행 데이터 경로 Custom 가능 -
따라서 마지막 활용에 언급한 내용과 같이 특정 경로 이하단의 모든 데이터를 다 이행해오길 원하면
Object Migration서비스를 사용하는 것이 더 편하다. 아니라면 경로들마다 migration 정책을 따로 다 만들어주어야 한다. -
특정 경로 이하에 있는 폴더들 일부만 선택하여 이행하거나 데이터가 존재하는 상위 경로가 완전히 다르더라도 Python module에서는 for문을 통해 동일한 로직으로 대응이 가능하다는 장점이 있다.
4. 참고문서

데이터 엔지니어의 작업공간 / #PYTHON #CLOUD #SPARK #AWS #GCP #NCLOUD