
0. INTRO
- Python을 사용하여 특정 Database에 connect 후 데이터를 다루는 방법은 크게 두 가지로 나뉜다.
- 특정 DB에 해당하는 라이브러리를 활용하여 connection 생성 후 SQL 쿼리를 통한 CRUD
- sqlalchemy와 같은 OMR 라이브러리를 활용하여 connection 생성 후 메서드를 통한 CRUD
- 이번 글에서는 PostgresSQL Database에 대해 각각의 방법으로 connection 생성과 테이블에 대한 CRUD하는 방법을 다뤄볼 것이다.
1. PostgresSQL 개별 라이브러리(psycopg2) 활용
- 로컬에 PostgresSQL DB가 설치되어 있다고 가정하고 설치 방법은 따로 다루지 않는다.
-
psycopg2 라이브러리 설치
pip install psycopg2
-
Connection 생성
import psycopg2 # database connection 생성 db = psycopg2.connect(host='localhost', dbname='postgres',user='postgres',password='910506',port=5432) # 커서 생성 cursor=db.cursor() -
SQL 쿼리를 통한 CRUD
# CREATE TABLE create_query = "CREATE TABLE first (id INT PRIMARY KEY, name VARCHAR(32), year INT, gender VARCHAR(32), count INT);" # INSERT DATA insert_query = "INSERT INTO first VALUES(0, 'Tom', 2023, 'M', 1100);" # UPDATA DATA update_query = """ UPDATE first SET id = 1, name = 'HYUNSOO', year = '1991', gender = 'M', count = '1000' WHERE id = 1; """ # DELETE DATA delete_query = "DELETE FROM first WHERE id = 1;" # SQL 쿼리 실행 cursor.execute(create_query) # COMMIT을 통한 변경 내용 확정 db.commit()
2. ORM 라이브러리(sqlalchemy)를 활용
1. ORM(Object Relational Mapping) 이란?
-
Python 객체와 관계형 DB의 data를 매핑해주는 것
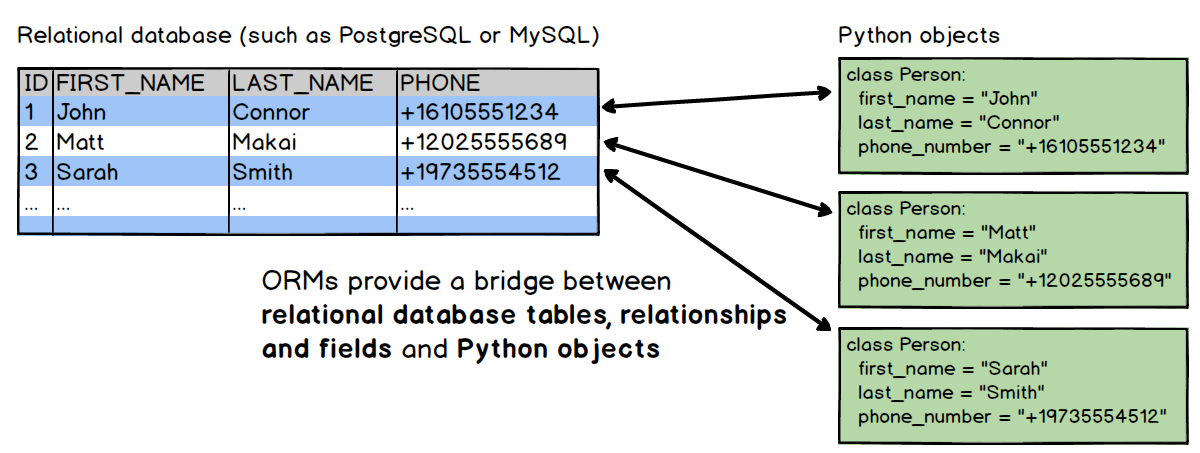
-
장점
- Query가 아닌 코드로 데이터를 조작할 수 있어 개발자가 프로그래밍에 더 집중할 수 있도록 도와준다.
- 재사용 및 유지보수의 편리성이 증가한다.
- DBMS에 대한 종속성이 줄어든다.
-
단점
- 완벽한 ORM으로만 서비스를 구현하기 어렵다.
- 프로시저가 많은 시스템에선 ORM의 객체 지향적인 장점을 활용하기 어렵다.
-
2. sqlalchemy - ORM 사용
-
sqlalchemy 라이브러리 설치
pip install sqlalchemy
-
Connection 생성
from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker engine_name = 'postgresql' user_id = 'postgres' user_pw = '910506' host = 'localhost' ip = '5432' db_name = 'postgres' db = create_engine(f'{engine_name}://{user_id}:{user_pw}@{host}:{ip}/{db}') Session = sessionmaker(db) session = Session() -
본격 ORM 실행
-
Database 내의 Table을 Python Class와 매핑해준다.
from sqlalchemy import declarative_base, Column, INTEGER, VARCHAR Base = declarative_base() class First(Base): __tablename__ = 'first' id = Column('id', INTEGER, primary_key=True) name = Column('name', VARCHAR(10), nullable=False) year = Column('year', INTEGER, nullable=False) gender = Column('gender', VARCHAR(10), nullable=False) count = Column('count', INTEGER, nullable=False) # Create Base.metadata.create_all(db) # Drop First.__table__.drop(db)
-
sqlalchemy 메서드를 이용한 CRUD
# 1) SELECT ALL res = session.query(First).all() for i in res: print(i.id, i.name, i.year, i.gender, i.count) # 2) INSERT data1 = First(name='hyunsoo', year=1990, gender='M', count=1234) session.add(data1) # 3) UPDATE session.query(First).filter(First.name == 'hyunsoo').update({'name':'hyunsoo', 'gender':'F'}) # 4) DELETE session.query(First).filter(First.name == 'hyunsoo').delete() # 결과 저장 session.commit()
3. sqlalchemy - Core 사용
-
Connection 생성
from sqlalchemy import create_engine, Table, Column, Integer, String, MetaData from sqlalchemy.orm import sessionmaker, declarative_base db = create_engine('postgresql://[USER ID]:[USER PW]@[IP]:[PORT]/[DB NAME]') # 세션 : Session = sessionmaker(db) session = Session() meta = MetaData() -
테이블 선언
# 테이블 스키마에 맞게 Column 생성 후 테이블 선언 core_table = Table( 'first', meta, Column('id', Integer, primary_key=True, autoincrement=True), Column('name', String), Column('year', Integer), Column('gender', String), Column('count', Integer) ) meta.create_all(db) -
sqlalchemy core 메서드를 이용한 CRUD
-
SELECT ALL
res = core_table.select() result = session.execute(res) for row in result: print(row) -
INSERT
from sqlalchemy import insert # INSERT 1건 stmt = insert(core_table).values(name="hahaha", year=2023, gender="M", count=654) with db.connect() as conn: result = conn.execute(stmt) conn.commit() ----------------------------------------------------------------------------- # INSERT 다수 stmt = insert(core_table) data_list = [ {"name": "tom", "year": 2023, "gender": "M", "count": 12}, {"name": "ann", "year": 2000, "gender": "F", "count": 32} ] with db.connect() as conn: result = conn.execute(stmt, data_list) conn.commit() -
UPDATE
from sqlalchemy import update stmt = update(core_table).where(core_table.c.name == 'ann').values(year=1990) with db.connect() as conn: result = conn.execute(stmt) conn.commit() -
DELETE
from sqlalchemy import update stmt = delete(core_table).where(core_table.c.name == 'ann') with db.connect() as conn: result = conn.execute(stmt) conn.commit()
-
4. ORM과 Core에 대하여 (참고사이트)
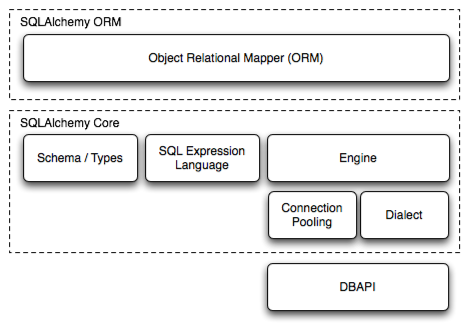
- sqlalchemy 라이브러리는 위와 같이 크게 ORM과 Core로 나누어져 있다.
-
Core
- 단순히 Python Class와 DB를 매핑해주는 것이 아닌, sqlalchemy에서 지원되는 내부 메소드들을 통하여 DB 및 table들과 상호작용 하며 이들을 다루는 기능들이 들어 있다.
- SQL 문법을 파이썬 언어로 표현 가능하게 해준다.
-
DBAPI (Python Database API Specification)
- 데이터베이스 연결 패키지들 간에 공통된 사용 패턴들을 설립한 것.
-
ORM
- Core를 기반으로 한 기능으로 SQL 언어의 관계형 데이터베이스와 프로그래밍 코드 사이의 다리 역할을 하는 라이브러리이다.

데이터 엔지니어의 작업공간 / #PYTHON #CLOUD #SPARK #AWS #GCP #NCLOUD