0. INTRO
- 클라우드상에서 데이터 분석시 이용되는 EMR Cluster는 07:30 - 18:00 까지 User들이 주로 사용을 하고 이 이외 시간에는 사용률이 극히 낮다. 이런 상황에서 과금 발생을 줄이기 위해서는 클러스터에 대한 스케쥴링 작업이 필수적이다.
- EventBridge 서비스를 통해 매일 특정 시각에 Lambda 함수를 Trigger하여 EMR 클러스터를 시작하고 종료시키는 방법으로 스케쥴링이 가능한데 이에 대해 알아보자! 간단한 아키텍쳐는 아래와 같다.
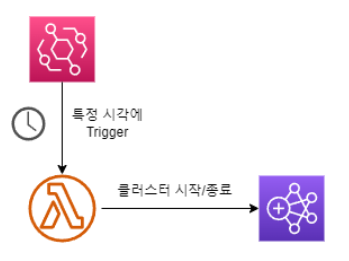
1. EMR CLUSTER 생성
-
EMR 클러스터를 생성하는 Lambda 함수
import boto3 from datetime import date, datetime, timezone, timedelta # 일일 스케쥴링을 위한 date 생성 KST = timezone(timedelta(hours=9)) time_record = datetime.now(KST).strftime('%Y%m%d') _today = time_record[2:] # boto3를 통한 emr client 생성 client = boto3.client("emr") def lambda_handler(event, context): # run_job_flow > EMR Cluster 생성 함수 cluster_id = client.run_job_flow( Name=f"emr_cluster_{_today}", Instances={ "InstanceGroups": [ { "Name": "Master", "Market": "ON_DEMAND", "InstanceRole": "MASTER", "InstanceType": "r5.xlarge", "InstanceCount": 1, "Configurations": [ { "Classification": "spark", "Properties": {"maximizeResourceAllocation": "false"}, }, { "Classification": "spark-defaults", "Properties": {"spark.dynamicAllocation.enabled": "false",}, }, ], }, { "Name": "Slave", "Market": "ON_DEMAND", "InstanceRole": "CORE", "InstanceType": "r5.xlarge", "InstanceCount": 2, "Configurations": [ { "Classification": "spark", "Properties": {"maximizeResourceAllocation": "false"}, }, { "Classification": "spark-defaults", "Properties": {"spark.dynamicAllocation.enabled": "false",}, }, ], }, ], "Ec2KeyName": "SSH-Key Name", # "Placement" : { # "AvailabilityZone" : "ap-northeast-2c" # }, "KeepJobFlowAliveWhenNoSteps": True, "TerminationProtected": True, "Ec2SubnetId": "subnet-xxxxx", }, LogUri="s3://custom/log/path/", ReleaseLabel="emr-6.3.0", VisibleToAllUsers=True, JobFlowRole="EMR_EC2_DefaultRole", ServiceRole="EMR_DefaultRole", BootstrapActions=[ { "Name": "emr_custom_library", "ScriptBootstrapAction": { "Path": "s3://custom/bootstrap/script_path/" } } ], # 만드는 클러스터에 설치되는 app들 정의 Applications=[ {"Name": "Spark"}, {"Name": "Hive"}, {"Name": "Hadoop"}, {"Name": "JupyterHub"}, {"Name": "JupyterEnterpriseGateway"}, ], ) -
EventBridge Rule를 통한 Trigger Scheduling
-
Amazon EventBridge > Rules > Create rule 메뉴를 클릭하여 Event Pattern에 따른 CRON을 설정하여 Rule 생성
-
Lambda Trigger로 해당 Eventbridge Rule 등록
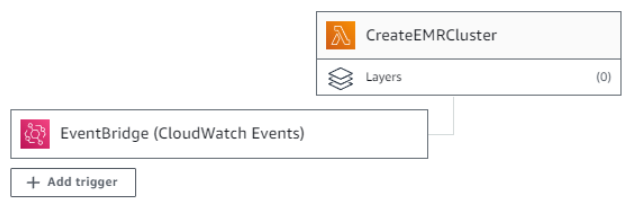
-
- Lambda 함수 Save & Deploy
- EventBridge Rule에 정해놓은 CRON 표현식의 시간에 해당 Lambda 함수가 작동되어 코드에 명시된 Spec과 동일한 EMR Cluster 생성이 시작된다.
2. EMR CLUSTER 종료
-
클러스터 종료의 경우는 종료 시각을 EventBridge Rule에 등록해놓은 후 Lambda Trigger 설정을 해놓는 부분은 위와 동일하다.
-
EMR 클러스터를 종료하는 Lambda 함수
import boto3 from datetime import date, datetime, timezone, timedelta # 일일 스케쥴링을 위한 date 생성 KST = timezone(timedelta(hours=9)) time_record = datetime.now(KST).strftime('%Y%m%d') _today = time_record[2:] cluster_name = (f"emr_cluster_{_today}",) # boto3를 통한 emr client 생성 client = boto3.client("emr") def lambda_handler(event, context): # 현재 상태가 WAITING 혹은, RUNNING인 클러스터들의 목록을 조회한다. page_iterator = client.get_paginator("list_clusters").paginate( ClusterStates=["WAITING", "RUNNING"] ) # 목록을 돌며 이름이 위에 명시한 cluster_name과 동일한 클러스터를 찾아 ID를 추출한다. for page in page_iterator: for item in page["Clusters"]: if item["Name"] == cluster_name[0]: cluster_id = item["Id"] # 특정 ID를 가지고 있는 클러스터의 종료 보호를 해제시킨 후 클러스터를 종료한다. client.set_termination_protection( JobFlowIds=[cluster_id], TerminationProtected=False ) client.terminate_job_flows(JobFlowIds=[cluster_id])
3. OUTRO
-
실제 업무에서 위와 같은 방법으로 클러스터 스케쥴링을 사용하고 있으며 해당 함수가 잘 작동하여 아래와 같이 딱 사용시간중에만 클러스터가 떴다가 업무시간 이후에는 자동으로 종료된 것을 볼 수 있다. 간단하지만 이 기능을 통해 해당 클러스터 사용에 드는 비용을 반 이상 줄일 수 있었다!
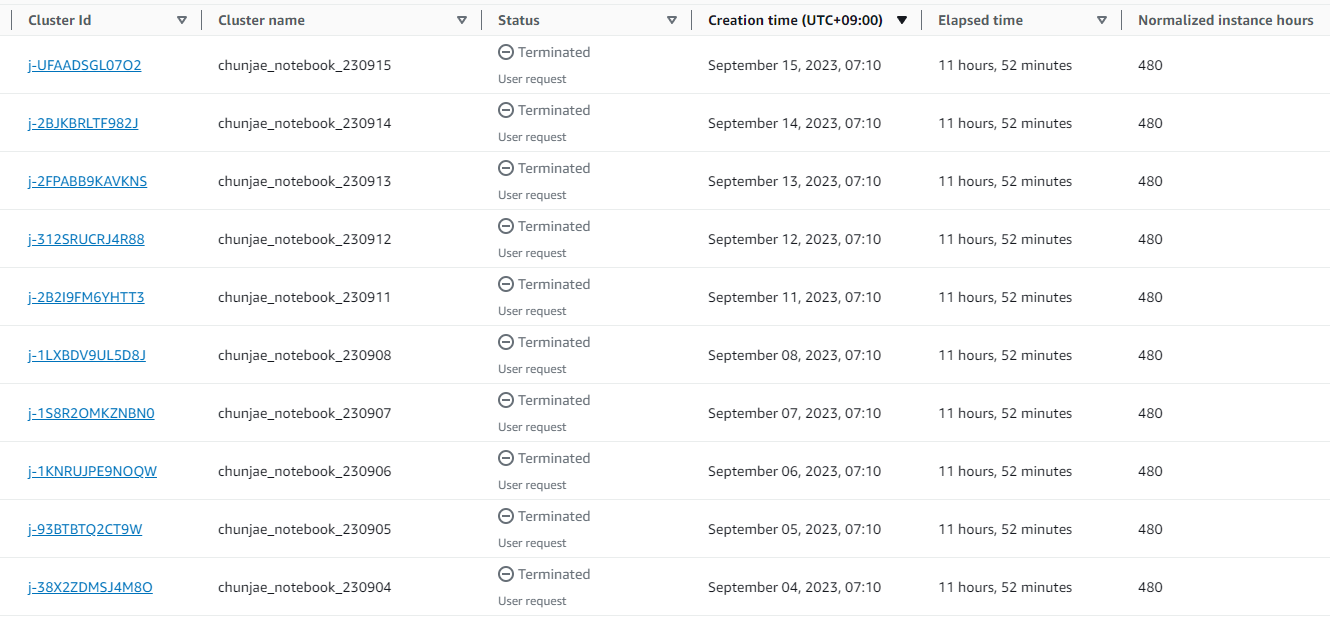
-
기본적으로 SDK를 이용하여 특정 AWS 서비스의 client를 호출할 때는 자격증명을 위해 아래 세가지 정보들을 함께 명시 후 호출을 하여야 한다.
-
AWS_ACCESS_KEY_ID : 유저 개인의 자격증명 Access Key의 ID
-
AWS_SECRET_ACCESS_KEY : 유저 개인의 자격증명 Access Key의 비밀번호
-
REGION_NAME : 유저의 서비스 사용 리전
client = boto3.client('서비스명' , AWS_ACCESS_KEY_ID = '' , AWS_SECRET_ACCESS_KEY = '' , REGION_NAME = '')
-
-
Lambda 서비스를 이용한 client 호출은 AWS 서비스 내에서의 사용이기 때문에 사용자에 대한 자격증명이 기본적으로 되어있다. 따라서 특별한 경우가 아니면
자격증명 관련된 3개 인자를 생략하고 서비스명만 넣어 호출해도 된다.client = boto3.client('서비스명')
