🔹 0. INTRO
- 요즘 데이터 엔지니어링의 핵심 트렌드 중 하나는 단연 레이크하우스(Lakehouse)입니다. Apache Iceberg, Delta Lake, Apache Hudi 등 오픈 테이블 형식(Open Table Format)의 등장으로, 파일 기반 데이터 레이크에서도 ACID 트랜잭션, 스키마 진화, 타임 트래블과 같은 데이터베이스급 기능을 사용할 수 있게 되었죠. 하지만 이러한 솔루션들은 복잡한 JSON/Avro 기반의 메타데이터 시스템을 사용하기 때문에, 작은 변경사항 처리나 트랜잭션 관리에서 한계를 드러내기도 합니다.
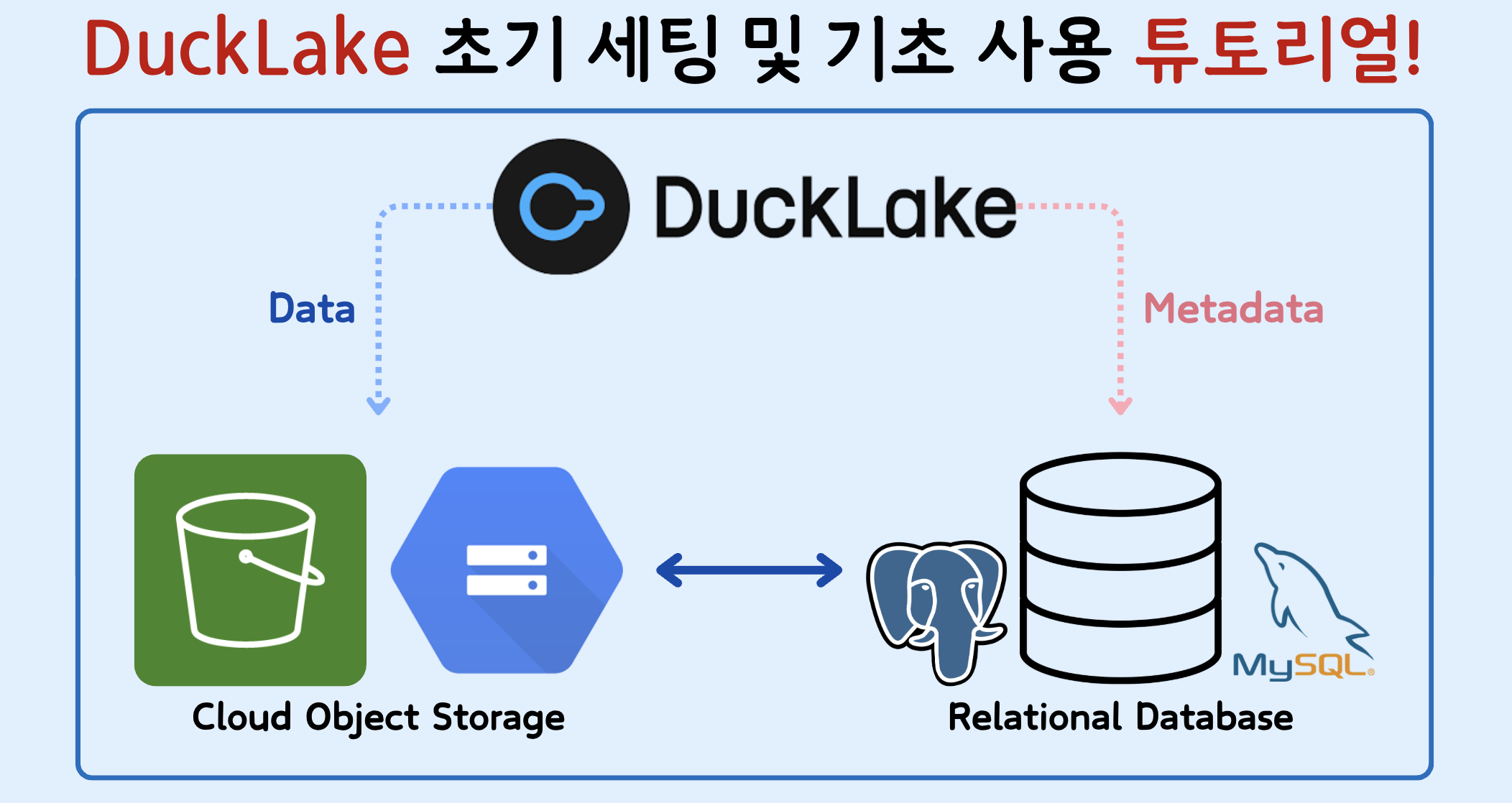
- 이러한 문제를 해결하고자 DuckDB 팀은 DuckLake라는 새로운 오픈 테이블 형식을 제안했습니다. 이는 기존 레이크하우스와 유사한 구조를 가지면서도, 핵심적인 차별점은 모든 메타데이터를 표준 SQL 데이터베이스에 저장한다는 점입니다.
- 이번 글에서는 기존의 솔루션들과 차별화되는 DuckLake의 핵심적인 특징들을 살펴보고 python을 이용해 어떻게 ducklake로 관리되는 환경을 구성할 수 있는지에 대한 실습까지 다뤄보도록 하겠습니다.
🔹 1. DuckLake의 핵심 특징
- DuckLake는 메타데이터를 데이터베이스에 저장함으로써, 파일 기반 레이크하우스가 안고 있던 복잡성과 성능 병목 문제를 해결하고 더 단순하고 유연한 대안을 제공합니다.
1) 성능 최적화
- 메타데이터 쿼리가 단일 SQL로 처리되어 빠름
- 수많은 HTTP 파일 요청 대신 메타데이터 인라인(inline) 저장
- 서브 밀리초 단위의 쓰기 및 작은 파일 문제 해결
2) 강력한 일관성과 트랜잭션 지원
- 관계형 DB의 ACID 속성 활용
- 다중 테이블 트랜잭션 및 트랜잭션 DDL 지원
3) 유연한 메타데이터 및 저장소 구성
- PostgreSQL, MySQL, DuckDB 등 다양한 DB 지원
- S3, GCS, 로컬 디스크 등 다양한 저장소와 호환
4) 스냅샷 및 보안 기능 내장
- 데이터베이스 테이블 기반으로 수백만 개의 스냅샷을 효율적 관리
- 기본 내장 암호화로 지속적인 검증(Zero Trust) 환경 구현
🔹 2. 설치 및 환경 구성
- DuckLake를 활용하기 위해서는 DuckDB가 설치되어 있어야 하고, 메타 테이블이 저장될 데이터베이스가 준비되어 있어야 합니다.
- DuckDB의 경우 pip으로 간단하게 설치하여 파이썬에서 활용이 가능하며, 메타 DB의 경우 Docker Compose를 이용하여 컨테이너 환경에서 운영될 수 있도록 구성할 것입니다.
1) DuckDB 및 관련 패키지 설치
- DuckDB 설치 → 공식 문서
- 파이썬으로 간단히 설치 →
pip install duckdb(반드시 1.3 버전 이상 설치) - DuckDB에서 Extension들을 사용하기 위해서는 각 패키지들에 대한 설치를 해야합니다. 이번 실습에서는 아래 내용들에 대한 설치가 필요합니다.
import duckdb as dd
# In Memory 상태에서 데이터베이스 연결 생성
mem_con = dd.connect()
# Extension들 설치
mem_con.execute("INSTALL postgres")
mem_con.execute("INSTALL mysql")
mem_con.execute("INSTALL ducklake")
mem_con.execute("INSTALL httpfs")2) Meta DB 구성(Docker Compose)
- DuckLake 메타 테이블들이 저장될 데이터베이스는 현재까지는 아래 4가지를 사용할 수 있습니다.
DuckDB,Sqlite,PostgreSQL,MySQL
- 이번 실습에서는
PostgreSQL과MySQL을 각각 활용해보도록 하겠습니다. - 아래 Docker Compose 파일을 실행해주면
PostgreSQL,MySQL컨테이너가 생성됩니다.
services:
mysql:
image: mysql
container_name: mysql_db
ports:
- "3306:3306"
environment:
- MYSQL_ROOT_PASSWORD=123456
- MYSQL_USER=hyunsoo
- MYSQL_PASSWORD=velog
- MYSQL_DATABASE=ducklake_catalog
postgres:
image: postgres:16
container_name: postgres_db
ports:
- "5432:5432"
environment:
- POSTGRES_USER=hyunsoo
- POSTGRES_PASSWORD=velog
- POSTGRES_DB=ducklake_catalog실행 명령 → docker compose up -d
🔹 3. DuckLake 연동
- DuckDB 설치와 데이터베이스 컨테이너 생성이 완료되었다면 기본적인 준비는 다 되었습니다. 이제부터는 아래 두 과정을 추가적으로 진행해주고 본격적인 연동 작업을 진행하면 됩니다.
- 1) 데이터가 저장될 클라우드 객체 저장소와의 자격 증명 내용 저장
- 2) 메타 데이터가 저장될 데이터베이스 연결 내용 저장
1) 객체 저장소 SECRET 생성
- GCS(Google Cloud Storage)의 경우 아래 공식 문서를 참고하여 'HMAC Key' 발급 후 SECRET 생성이 가능합니다.
secret_gcs = """
CREATE SECRET (
TYPE GCS,
KEY_ID 'ABCDE',
SECRET 'ABCDESECRET'
);
"""
mem_con.execute(secret_gcs)- AWS S3의 경우 IAM 장기 자격증명 발급 후 SECRET 생성이 가능합니다.
secret_s3 = """
CREATE SECRET (
TYPE s3,
PROVIDER config,
KEY_ID 'AKIAIOSFODNN7EXAMPLE',
SECRET 'wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY',
REGION 'ap-northeast-2'
);
"""
mem_con.execute(secret_s3)- 생성한 SECRET 목록 확인
mem_con.execute("FROM duckdb_secrets()").df()2) Meta DB SECRET 생성
- DuckLake의 메타 테이블 저장소로 사용되는
PostgreSQL과MySQL역시 SECRET으로 등록해주어야 합니다. - 이번 글에서는 데이터베이스 각각에 대해서 연결하는 코드를 모두 작성하였지만 실제로 DuckLake 사용을 위해서는 하나의 데이터베이스만 선택해서 사용하면 됩니다.
PostgreSQL 등록 → 공식 문서
pg_conn = """
CREATE SECRET (
TYPE postgres,
HOST '127.0.0.1',
PORT 5432,
DATABASE ducklake_catalog,
USER 'codeit',
PASSWORD 'sprint'
);
"""
mem_con.execute(pg_conn)MySQL 등록 → 공식 문서
mysql_conn = """
CREATE SECRET (
TYPE mysql,
HOST '127.0.0.1',
PORT 3306,
DATABASE ducklake_catalog,
USER 'codeit',
PASSWORD 'sprint'
);
"""
mem_con.execute(mysql_conn)3) DuckLake 연동
ATTACH명령어를 통해 DuckLake 설정이 가능하며,DATA_PATH다음에는 DuckLake에서 관리되는 데이터가 저장될 경로를 넣어주시면 됩니다. 아래 예시와 같이 로컬 경로, 클라우드 스토리지 경로 등 사용 환경에 맞게 설정이 가능합니다.- 로컬 경로 예시 :
/home/ducklake/data/ - AWS S3 예시 :
s3://aws_ducklake_bucket/data_dir/ - GCS 예시 :
gs://gcs_ducklake_bucket/data_dir/
- 로컬 경로 예시 :
- 아래 실습에서는 Google Cloud Storage의
gs://hyunsoo_de_bucket/ducklake/postgres/경로를 데이터 저장소로 사용해보겠습니다. - 형식은 아래와 같습니다.
ATTACH 'ducklake:<연결 DB 종류>:dbname=<데이터베이스 이름>' AS <생성할 DB 이름>(DATA_PATH <객체 저장소 경로>);
PostgreSQL을 메타 DB로 사용하는 경우
ducklake_conn = """
ATTACH 'ducklake:postgres:dbname=ducklake_catalog'
AS my_ducklake(DATA_PATH 'gs://hyunsoo_de_bucket/ducklake/postgres/');
"""
mem_con.execute(ducklake_conn)MySQL을 메타 DB로 사용하는 경우
ducklake_conn = """
ATTACH 'ducklake:mysql:db=ducklake_catalog'
AS my_ducklake(DATA_PATH 'gs://hyunsoo_de_bucket/ducklake/mysql/');
"""
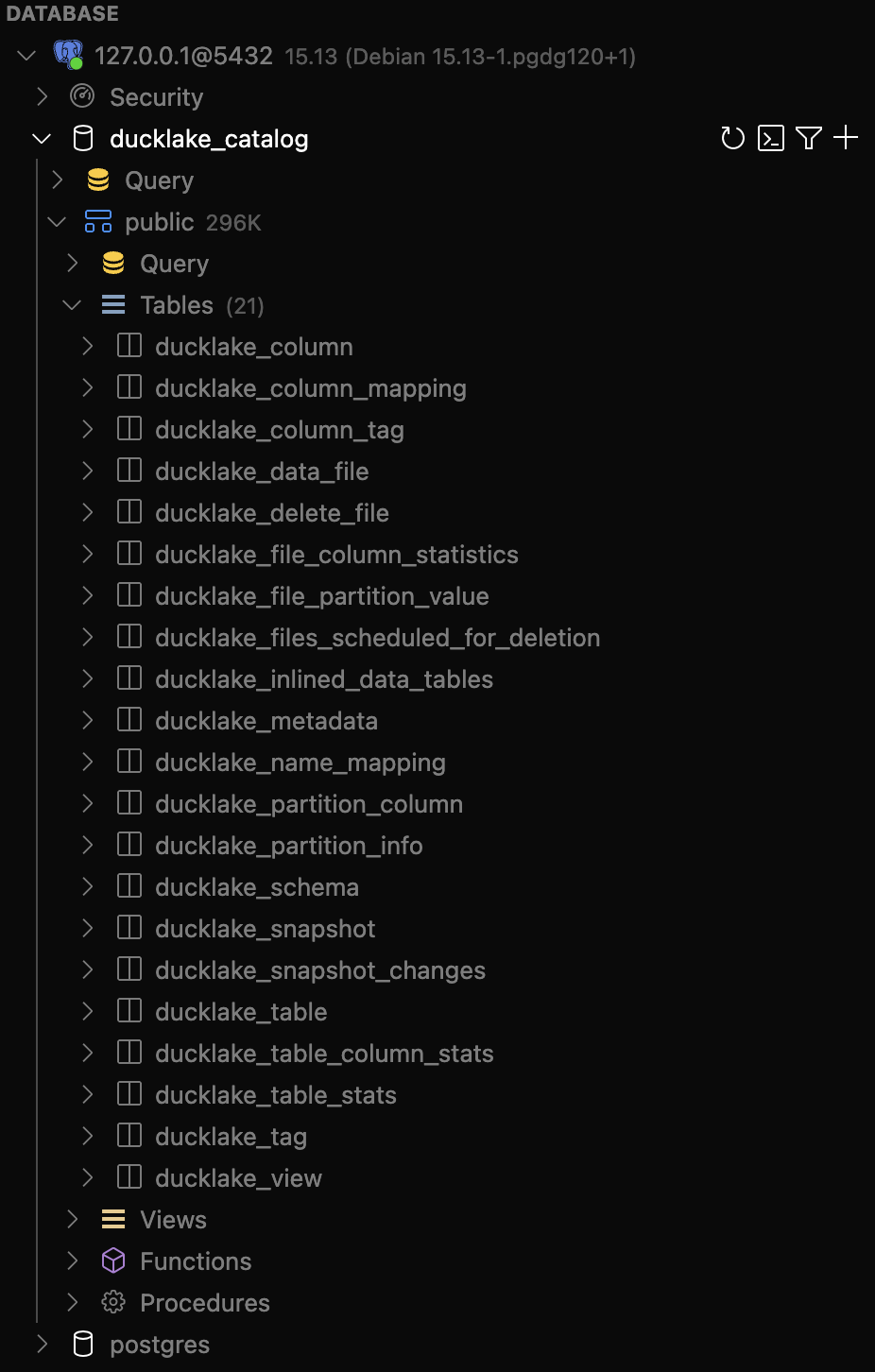
mem_con.execute(ducklake_conn)- 위의 코드가 에러 없이 잘 실행이 되었다면 DuckLake 사용환경 설정이 완료가 되었습니다. 선택한 데이터베이스의
ducklake_catalogDB를 조회해보면 아래와 같이 DuckLake 관련 메타 테이블들이 세팅되어 있는 것을 확인할 수 있습니다.
🔹 4. 데이터 조회 및 테이블 생성
1) Cloud 객체 저장소 데이터 조회
- 등록한 객체 저장소 SECRET을 활용해 객체 저장소에 있는 파일(JSON, parquet, CSV 등) 데이터를 DuckDB로 바로 조회할 수 있습니다.
_query = """
FROM read_parquet('gs://hyunsoo_de_bucket/dataset/emp.parquet')
"""
mem_con.execute(_query).df()2) 데이터베이스 조회
- 데이터베이스를 조회해보면 DuckLake로 관리되는 데이터베이스가 목록에 포함되어 있는 것을 확인할 수 있습니다.
mem_con.execute("SHOW DATABASES").df()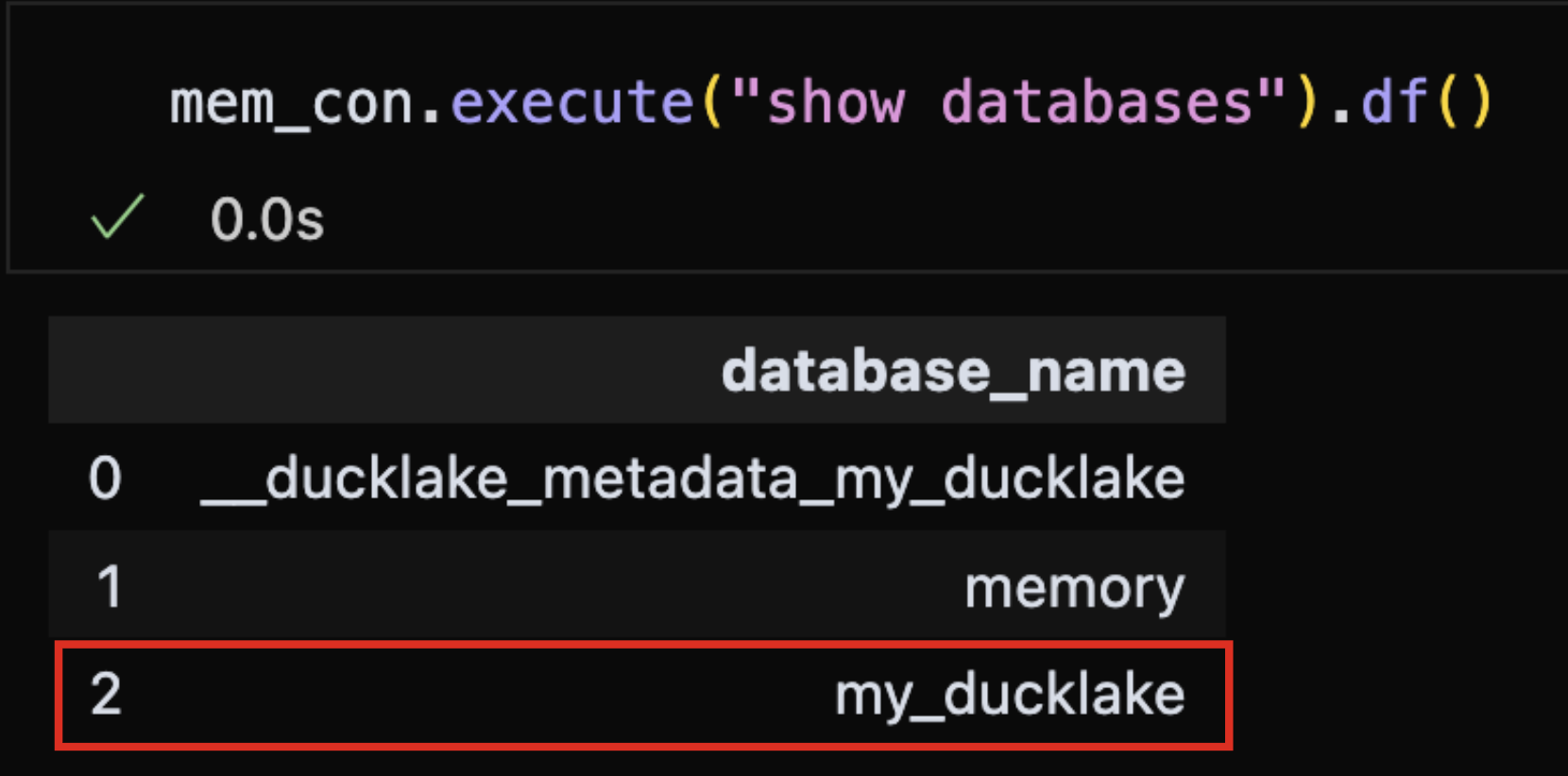
3) DuckLake에 테이블 저장
- 먼저 위에서 생성한
my_ducklake데이터베이스를 선택한 후CREATE TABLE ~ AS쿼리를 통해 기존에 있는 테이블을 기반으로 새로운 테이블을 생성합니다.
## my_ducklake 데이터베이스 사용 설정
mem_con.execute("USE my_ducklake")
## 새로운 테이블 생성
create_table = """
CREATE TABLE duck_emp
AS
SELECT * FROM read_parquet('gs://hyunsoo_de_bucket/dataset/emp.parquet')
"""
mem_con.execute(create_table)-
테이블 생성 후 등록한
DATA_PATH경로를 확인해보면main/<테이블 이름>디렉토리가 새롭게 생성되면서 데이터가parquet파일 형태로 저장이 된 것을 확인할 수 있습니다.
(‼️ 위 저장되는 디렉토리 구조는 MacOS 기준이며, 실습 결과 Windows와 Linux 플랫폼에서는 디렉토리 구조가 약간 달랐습니다. ‼️)
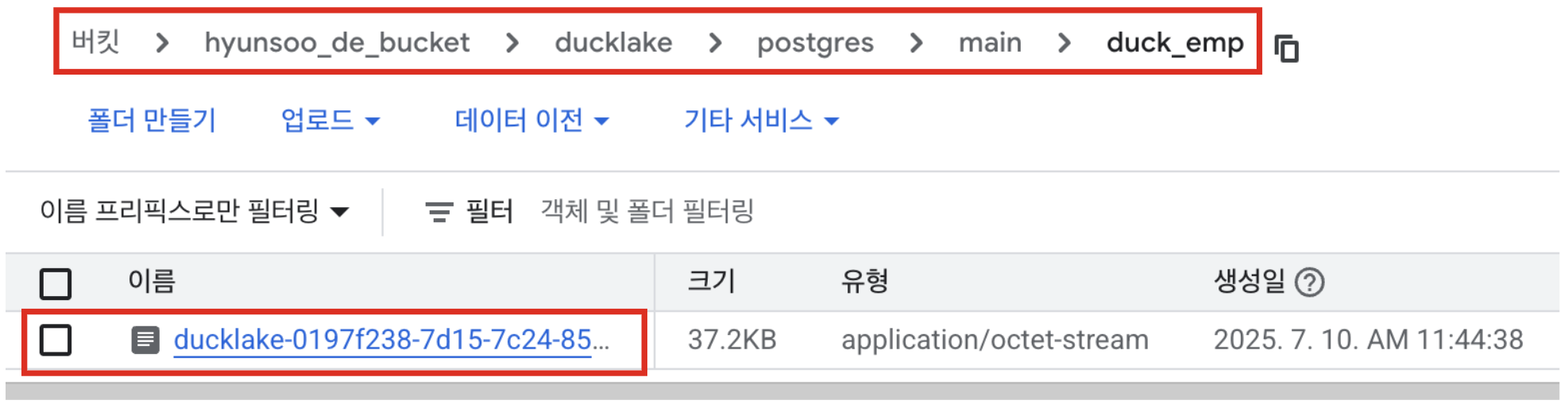
-
또한 메타 테이블의
ducklake_table을 조회해보면 아래와 같이 방금 생성한duck_emp테이블을 확인할 수 있습니다.

🔹 5. 버전 확인 및 Time Travel
1) 테이블 수정
- Time Travel 쿼리를 작성하기에 앞서 데이터를 수정해보도록 하겠습니다.
## 1) 새로운 컬럼 추가(new_col)
mem_con.execute("ALTER TABLE duck_emp ADD COLUMN new_col INT DEFAULT 0")
## 2) UPDATE
mem_con.execute("UPDATE duck_emp SET new_col = 1 WHERE Salary >= 100000")
## 3) DELETE
mem_con.execute("DELETE FROM duck_emp WHERE Salary < 50000")- 테이블 수정 발생시 연결된 객체 저장소에도 parquet 파일이 추가적으로 생성되어 아래와 같이 확인이 가능합니다.
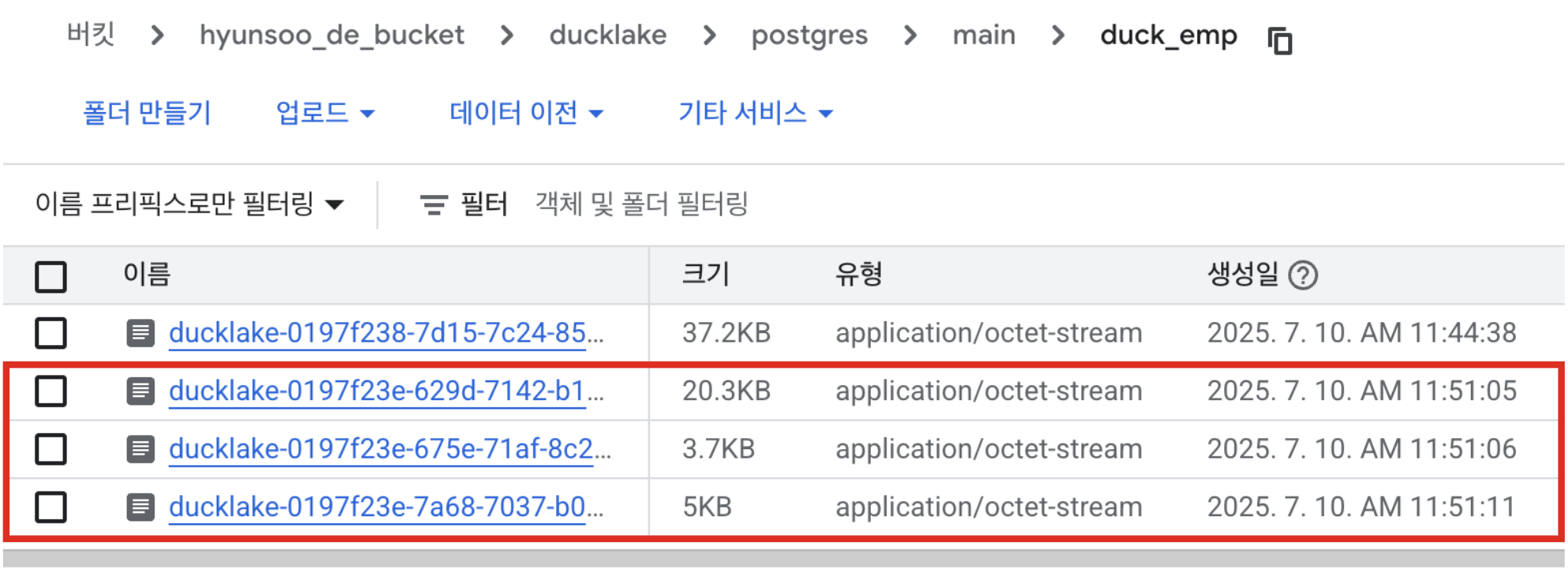
2) 테이블 버전 확인
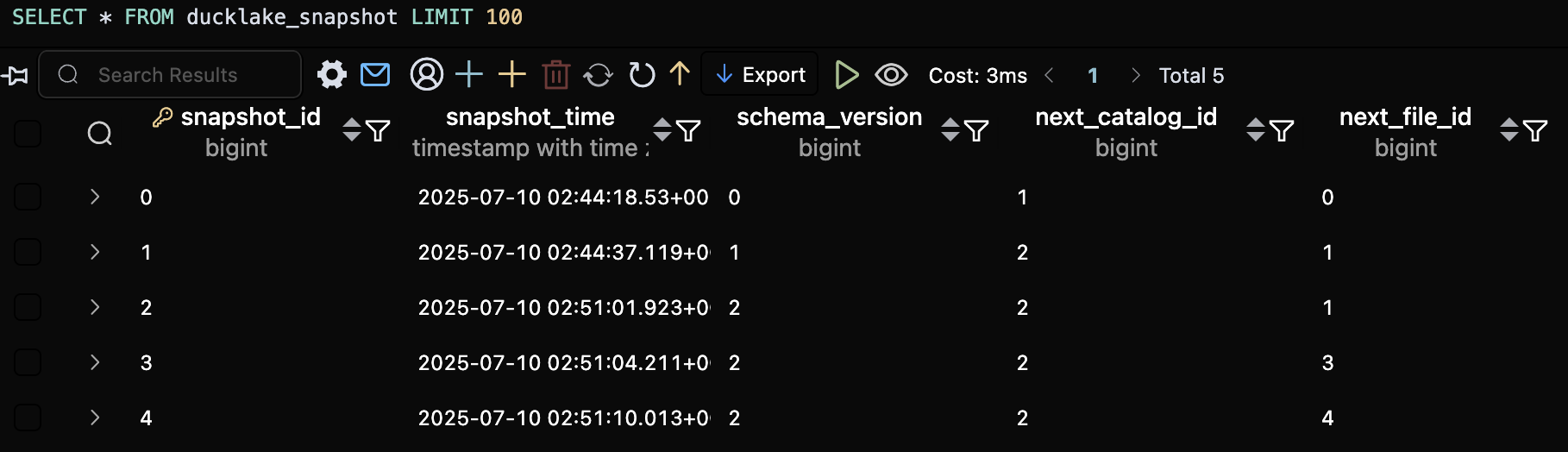
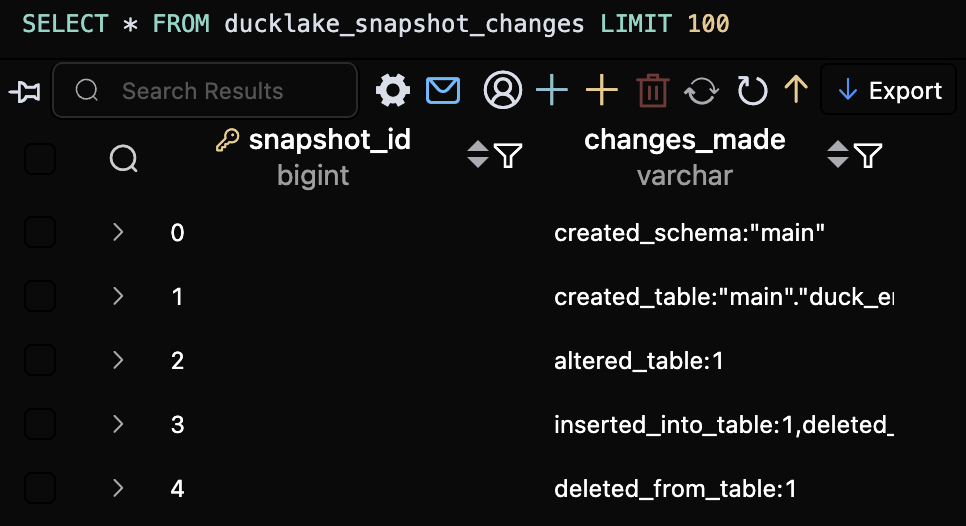
- 테이블 수정 내용 및 버전 확인을 위해서는 메타테이블의
ducklake_snapshot,ducklake_snapshot_changes테이블을 조회해보면 됩니다.
ducklake_snapshot 테이블
ducklake_snapshot_changes 테이블
- 또한 아래 파이썬 코드를 통해서도 확인이 가능합니다.
mem_con.execute("FROM my_ducklake.snapshots()").df()
3) Time Travel 쿼리
버전 기반 Time Travel
- 테이블 스냅샷 기준 3버전 상태로 되돌립니다.
mem_con.execute("SELECT * FROM duck_emp AT (VERSION => 3)").df()시간 기반 Time Travel
2025-07-04 05:43:49.371+00→ 이 시점에서의 테이블 데이터를 보여줍니다.
mem_con.execute("SELECT * FROM duck_emp AT (TIMESTAMP => '2025-07-04 05:43:49.371+00')").df()🔹 6. OUTRO
- 기존에는 Iceberg나 Delta Lake 같은 Open Table Format(OTF)을 사용할 때, 그 구조에 큰 의문을 가지지 않았습니다. 파일 단위로 저장된 데이터가 ACID 트랜잭션, 롤백, 그리고 Time Travel까지 지원된다는 점이 그저 신기하게 느껴졌죠. 동일한 경로에 메타데이터가 파일 형식으로 저장된다는 것도 "이력 관리를 위해서는 당연히 이렇게 저장이 되어야지!" 하고 넘어갔습니다.
- 하지만 DuckLake를 접하고 기존 도구들과의 차이점에 대해 알게 되면서 이런 생각이 들었습니다.
"메타데이터를 꼭 파일로만 저장해야 할까? 왜 DB로 관리할 수 있다고 생각을 못했을까?"
DuckLake처럼 메타데이터를 데이터베이스에 저장하면, 이력 조회나 관리 작업이 훨씬 직관적이고 유연해질 수 있겠다는 가능성을 느꼈습니다. - 물론 아직까지는 기존 OTF만큼 성숙한 생태계를 갖췄다고 보긴 어렵습니다. 하지만 DuckDB의 빠른 발전 속도와 함께 DuckLake 역시 함께 성장한다면, 향후에는 널리 사용되는 차세대 테이블 포맷으로 자리 잡을 수도 있겠다는 생각을 하게 되었습니다.
🔹 7. 참고 자료

데이터 엔지니어의 작업공간 / #PYTHON #CLOUD #SPARK #AWS #GCP #NCLOUD