
문제
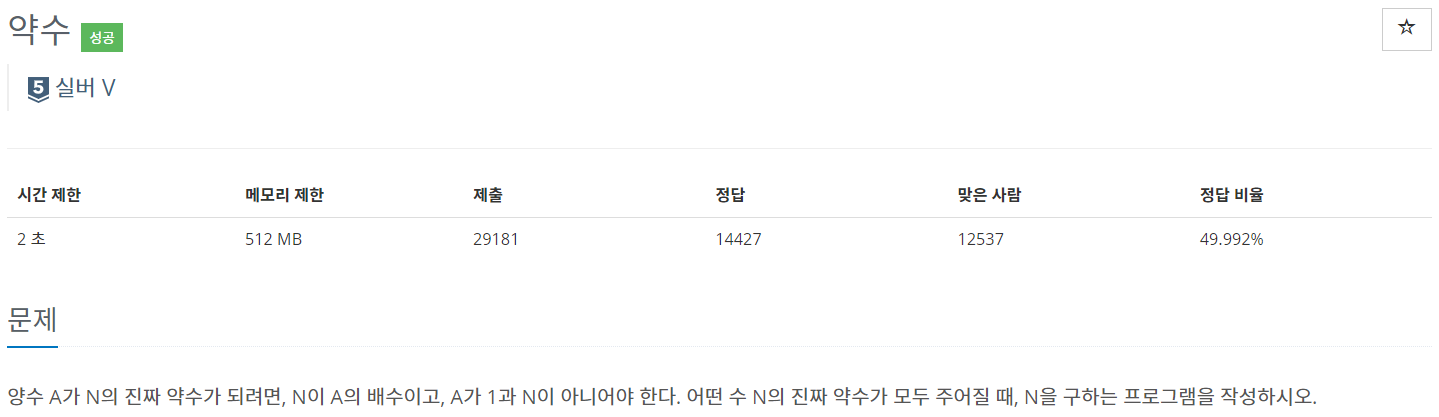
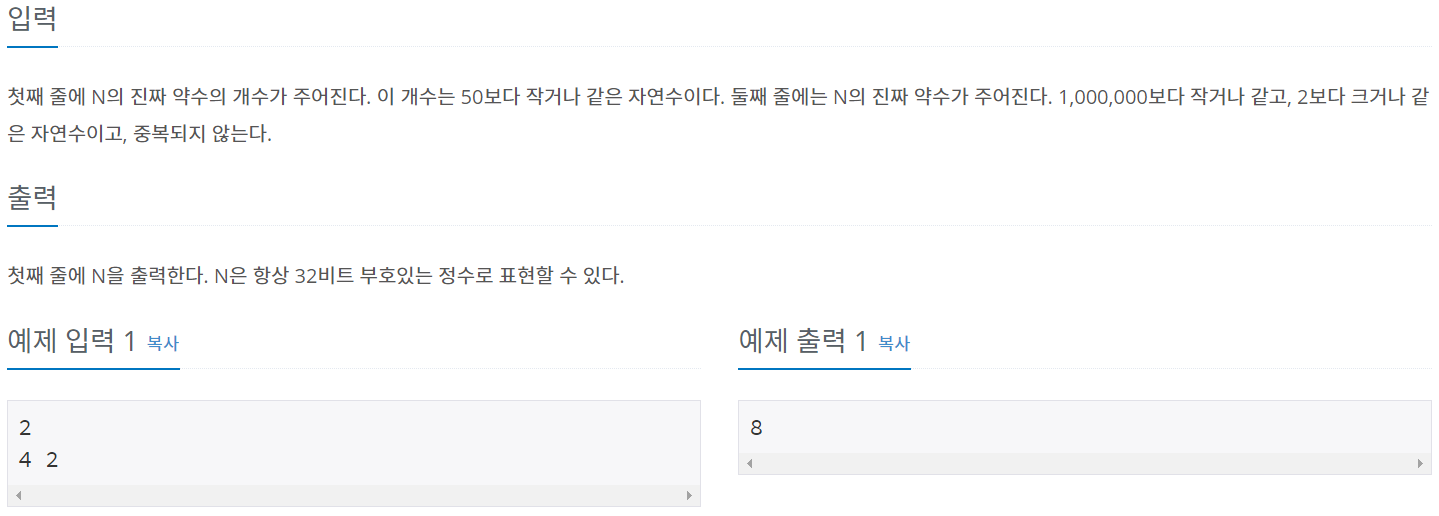
입력 및 출력
풀이
import java.io.*;
import java.util.*;
class Main {
public static void main(String args[]) throws Exception {
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
int count = Integer.parseInt(br.readLine());
StringTokenizer st = new StringTokenizer(br.readLine());
int[] numArray = new int[count];
for (int i = 0; i < count; i++) {
numArray[i] = Integer.parseInt(st.nextToken());
}
int max = 0, min = numArray[numArray.length - 1];
for (int i = 0; i < count; i++) {
if (numArray[i] > max) {
max = numArray[i];
}
if (numArray[i] < min) {
min = numArray[i];
}
}
System.out.println(max * min);
}
}결과 및 해결방법
[결과]

[정리]
StringTokenizer
-
StringTokenizer 클래스는 문자열을 지정한 구분자로 쪼개주는 클래스이다. 여기서, 쪼개어진 문자열을 토큰이라 부른다.
-
StringTokenizer의 생성자에는 총 3가지가 존재한다.
<public StringTokenizer(String str)>
- 매개변수를 기본 delim으로 분리한다. 기본 delimiter는 공백문자이다.<public StringTokenizer(String str, String delim)>
- 특정 delim으로 문자열을 분리한다.<public StringTokenizer(String str, String delim, boolean returnDelims)>
- str을 특정 delim으로 분리시키는데 그 delim까지 토큰으로 포함할지를 결정한다. returnDelims가 true일 경우 포함, false일 경우 포함하지 않는다. -
StringTokenizer의 자주 사용하는 메소드는 총 3가지이다.
<int countTokens()>
- 남아있는 토큰의 개수를 반환한다.<boolean hasMoreElements(), boolean hasMoreToken()>
- 다음 토큰을 반환한다. StringTokenizer는 내부적으로 어떤 위치의 토큰을 사용하였는지 기억하고 있고 그 위치를 다음으로 옮긴다.
- 위 두 메소드는 모두 같은 값을 반환한다.<Object nextElement(), String nextToken()>
- 이 두가지 메소드는 다음의 토큰을 반환한다.
- 두 메소드의 차이점은 리턴 타입이다.
해결방법
-
약수를 구하는 방법은 소인수분해를 이용하는 방법이 있으며 12를 예로 들어 [1 * 12], [2 * 6], [3 * 4] 가 존재한다.
따라서 12의 약수는 총 6개로 1, 2, 3, 4, 6, 12이다. 위의 문제에서 1과 12를 제외한 진짜 약수는 2, 3, 4, 6으로 사용자는 약수의 개수를 첫 번째 줄에 입력하고 진짜 약수를 두 번째 줄에 입력하므로 가장 큰 수와 가장 작은 수를 곱한 값이 N이 될 것이다.
