SELECT 쿼리 실행 순서
FROM, ON, JOIN > WHERE, GROUP BY, HAVING > SELECT > DISTINCT > ORDER BY > LIMIT
- FROM
각 테이블을 확인한다. - ON
JOIN 조건을 확인한다. - JOIN
JOIN이 실행되어 데이터가 SET으로 모아지게 된다. 서브쿼리도 함께 포함되어 임시 테이블을 만들 수 있게 도와준다. - WHERE
데이터셋을 형성하게 되면 WHERE의 조건이 개별 행에 적용된다. WHERE절의 제약 조건은 FROM절로 가져온 테이블에 적용될 수 있다. - GROUP BY
WHERE의 조건 적용 후 나머지 행은 GROUP BY절에 지정된 열의 공통 값을 기준으로 그룹화된다. 쿼리에 집계 기능이 있는 경우에만 이 기능을 사용해야 한다. - HAVING
GROUP BY절이 쿼리에 있을 경우 HAVING 절의 제약조건이 그룹화된 행에 적용된다. - SELECT
SELECT에 표현된 식이 마지막으로 적용된다. - DISTINCT
표현된 행에서 중복된 행은 삭제 - ORDER BY
지정된 데이터를 기준으로 오름차순, 내림차순 지정 - LIMIT
LIMIT에서 벗어나는 행들은 제외되어 출력된다.
실행 순서가 중요한 이유
쿼리를 사용할 때 최종적으로 출력되는 결과만 육안을 확인할 수 있다. 그래서 각 단계에서 어떤 데이터를 읽고 사용할 수 있는지, 실행순서를 모르면 쿼리를 효율적으로 작성하는데 어려움이 있을 수 있다.
ALIAS 사용
1번쿼리 : ORDER BY 절 ALIAS 사용
SELECT
EMPLOYEE_ID
,FIRST_NAME || ' ' || LAST_NAME AS NAME
,SALARY
,JOB_ID AS JOB
FROM EMPLOYEES
WHERE SALARY > 5000
ORDER BY NAME;1번 쿼리에서는 아무 문제가 없다. ORDER BY 절은 맨 마지막에 실행되기 때문에 컬럼의 ALIAS를 사용해도 아무 문제가 없다.
2번쿼리 : WHERE 절 ALIAS 사용
SELECT
EMPLOYEE_ID
,FIRST_NAME || ' ' || LAST_NAME AS NAME
,SALARY
,JOB_ID AS JOB
FROM EMPLOYEES
WHERE SAL > 5000
ORDER BY NAME;2번쿼리는 "Invalid Identifier"에러가 발생할 것이다. 이유는 SELECT 절은 WHERE 절 이후에 실행되기 때문에 WHERE 절이 실행 될때는 SAL 칼럼은 아직 존재하지 않는 컬럼이기 때문이다.
ROWNUM 사용
SELECT
ROWNUM
,EMPLOYEE_ID
,FIRST_NAME || ' ' || LAST_NAME AS NAME
,SALARY
,JOB_ID AS JOB
FROM EMPLOYEES
WHERE SALARY > 5000
ORDER BY NAME;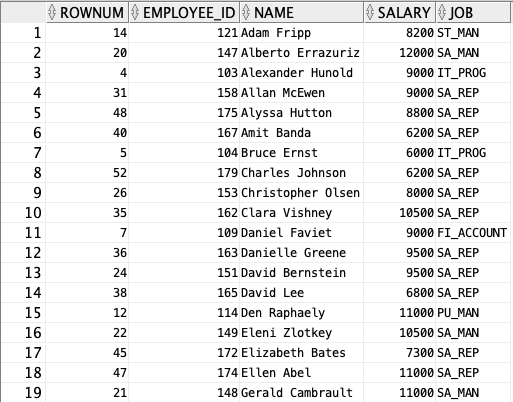
ROWNUM을 SELECT에 포함시켜 결과를 출력해보았다. 1 부터 출력 될것만 같았던 ROWNUM이 뒤죽박죽 섞여 있는데 현재 결과는 NAME 칼럼으로 정렬된 결과이다. 'A' 부터 순서대로 NAME칼럼을 기준으로 데이터를 정렬하여 출력된 올바른 출력결과지만 ROWNUM은 이상하게 섞여 있다. 이 문제도 마찬가지로 실행 순서에 따른 결과이다.
ORDER BY 절은 SELECT 절이 실행된 이후 처리된다. 그래서 ROWNUM은 NAME 칼럼으로 정렬되기 이전의 값에 행을 번호 매긴 순서이다. 우리가 볼 수 있는 출력 결과는 ROWNUM을 매긴 후, NAME 칼럼으로 정렬된 결과 뿐이다.
성능
아래는 SELECT 쿼리의 실행 동작을 시각화한 것이다.
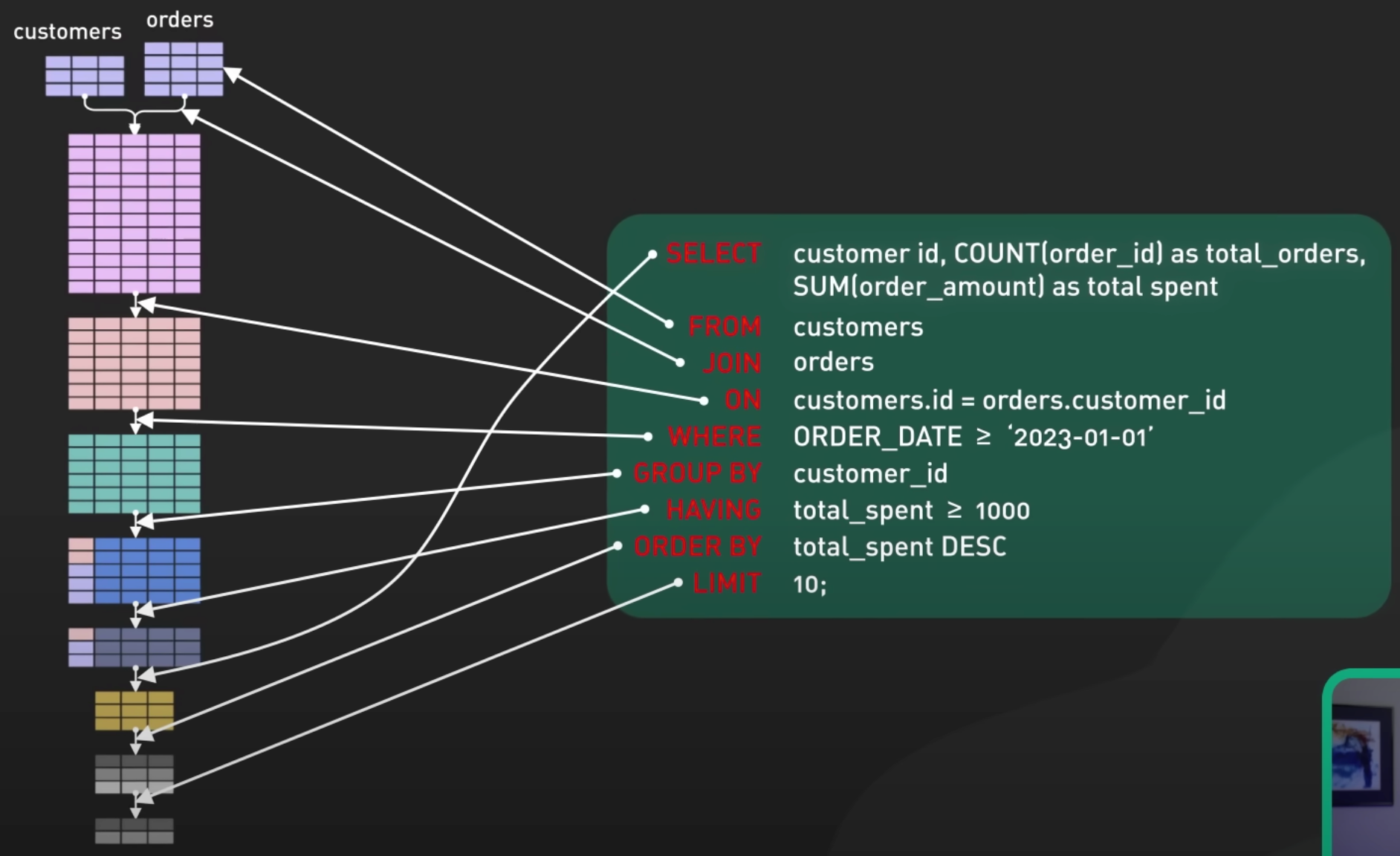
JOIN할 테이블이 많고 레코드도 매우 많다면 수 많은 레코드를 가지고 WHERE, GROUP BY, ORDER BY 등을 수행하게 된다.
SQL 실행 순서를 이해한다면 LIMIT을 포함해 먼저 ID만을 필터링한 후에 복잡한 JOIN을 포함한 나머지 컬럼 조회는 필터링된 레코드의 ID만을 가지고 후속 쿼리에서 실행할 수도 있을 것이다.
그러면 실제로 검색할 때 데이터의 행, 열 모두 크기가 매우 작아지므로 부하가 감소된다. 무거운 쿼리 1개를 가벼운 쿼리 2개로 나눴지만, 실행 시간이나 부하는 10배 개선될 수도 있다.
SQL 실행 순서를 이해하면 쿼리의 성능이 낭비되는 지점이 잘 보이고 튜닝을 할 수 있게 된다.
출처 : https://dev-coco.tistory.com/158
https://myjamong.tistory.com/172
https://jaehoney.tistory.com/191
