안녕하세요.
넥스트도어 장우일입니다.
오늘은 CVPR 2022에 발표된, 3D Pose Estimation 분야 논문인 MHFormer에 대해 소개해드리겠습니다.
코드 : https://github.com/Vegetebird/MHFormer
논문 : https://openaccess.thecvf.com/content/CVPR2022/papers/Li_MHFormer_Multi-Hypothesis_Transformer_for_3D_Human_Pose_Estimation_CVPR_2022_paper.pdf
이 논문은 단안 비디오에서 3D Human Pose를 추정하는 모델로, 여러 그럴듯한 포즈 가설들을 집계해서 모델링하고, 최종 3D Pose를 합성하도록 하고 있습니다.
(Multi-Hypothesis Transformer : MHFormer)
말이 좀 어렵죠?
"다양한 방법(가설)들을 시도해보고, 그 중 효과가 좋은 방법(가설)들만을 활용한다"로 이해하셔도 좋을 것 같습니다.
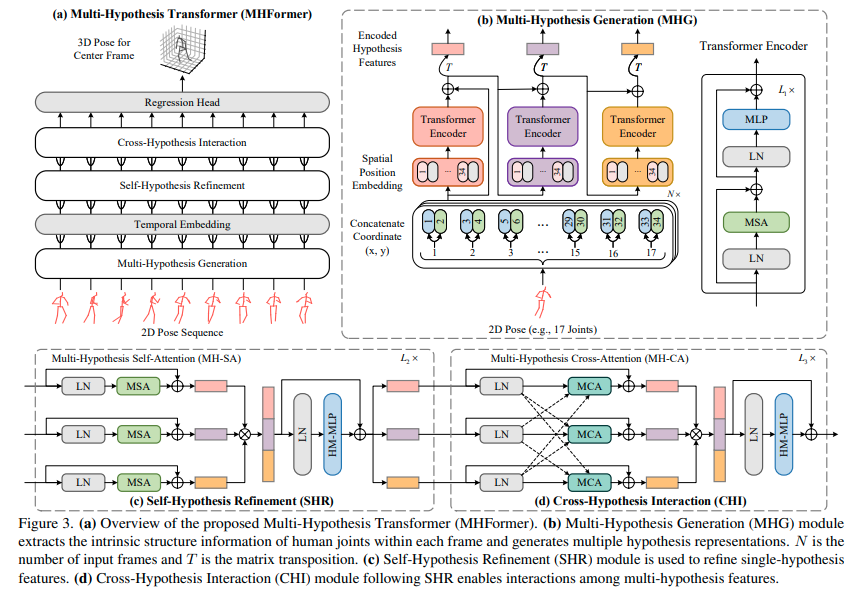
제안된 모델의 전체적인 구조는 그림3의 (a)와 같습니다.
1) 비디오에서 기존의 2D Pose estimator에 의해 추정된 연속적인 2D Pose sequence가 주어지면,
2) 다중 가설 feature 계층에서 공간 및 시간 정보를 최대한 활용해서
3) 중앙 프레임의 3D Pose를 재구성하는 걸 목표로 하고 있습니다.
이 모델에서 중요한 파트가 크게 5가지 정도 되는데요.
하나씩 살펴보겠습니다.
1. Multi-Hypothesis Generation
공간 영역에서 초기 다중 가설 feature를 생성하는 역할.
그림3의 (b) 부분으로, 인간의 관절 관계를 모델링하고, 다중 가설 표현을 초기화하는 역할을 합니다.
구체적으로 보면, 각 프레임별로 관절의 (x,y) 좌표를 연결하고, embedding feature를 MHG의 인코더에 feed 합니다.
MHG의 출력은 다양한 의미 정보를 포함하는 다중 레벨의 feature입니다.
그래서 이러한 feature는 다양한 포즈 가설의 초기 표현값으로 간주될 수 있고, 추후 enhance되어야 합니다.
2. Temporal Embedding
MHG의 feature의 부족한 점들을 보완하기 위해, SHR 및 CHI 모듈을 사용해서, 시간 종속성을 캡쳐하도록 한다. (그림3-c, d)
먼저 공간 영역을 시간 영역으로 변환한 뒤, 학습가능한 시간 위치가 프레임의 위치 정보를 유지하는 데 사용된다.
3. Self-Hypothesis Refinement
1) MH-SA (multi-hypothesis self-attention)
: Multi-head self attention과 유사하게 네이밍한 게 아닌가 싶네요.
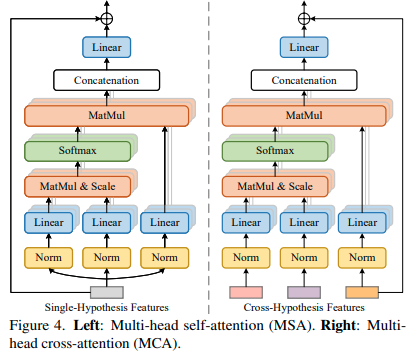
"다른 가설 feature들의 메시지는 feature 향상을 위해 self-hypothesis 방식으로 전달될 수 있다."
라고 합니다만, 그림3의 (c)를 보면 3개의 MSA가 있고, 끝단에서 하나로 합쳐지는 걸 볼 수 있습니다.
여러 개의 가설(여기서는 3개)들을 모두 학습하고, 결국 그들 중 효과가 좋은 가설의 feature가 더 강화되는 형식으로 학습이 진행되지 않을까 싶네요.
2) Hypothesis-Mixing MLP
다중 가설은 MH-SA에서 독립적으로 처리되지만, 가설 간의 정보 교환은 없습니다.
이 문제를 처리하기 위해(가설 간의 정보 교환이 되도록 만들기 위해) MH-SA 뒤에 가설 혼합 MLP를 추가합니다.
(그림3-c의 HM-MLP 부분)
4. Cross-Hypothesis Interaction
3번 과정이 끝난 뒤, MH-CA 및 HM-MLP의 두 블록이 포함된 CHI(그림3-d)를 통해, 다중 가설 feature 간의 상호 작용을 모델링합니다.
1) MH-CA
MH-SA는 상호 작용 모델링을 제한하는, 가설 간의 연결이 부족하다.
그래서 가중 가설 상관관계를 캡쳐하기 위해 병렬로 multi head cross attention(MCA)로 구성된 MH-CA를 제안한다.
(Multi-head self attention -> Multi-head Cross Attention)
MCA : 교차가설 feature 간의 상관관계를 측정하며, MSA와 유사한 구조를 갖는다.
이 구성의 문제는 블록이 더 많이 생성된다는 것에 있는데, 그림4(오른쪽)와 같이 3개의 MCA 블록만 필요하도록 하여, 매개변수 수를 줄이는, 보다 효율적인 전략으로 해결한다.
5. Regression Head
모델의 끝단에 Regression Head가 위치하는데(그림3-a), 3D Pose 시퀀스를 생성하고, 마지막으로 중앙 프레임의 3D Pose를 최종 예측값으로 선택하는 역할을 한다.
(실제 추론 시 이런 과정 때문인지, jittering이 많이 줄어든 걸 볼 수 있었다.)
학습은 1개의 RTX 3090 GPU를 이용해서 했고, 2D Pose Detector는 CPN을 사용했다고 합니다.
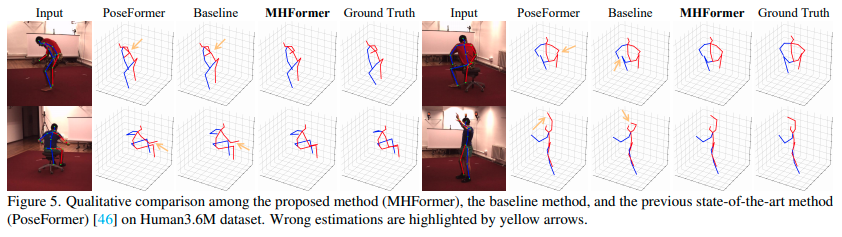
어느 논문이나 그렇듯 결과 이미지는 굉장히 좋습니다.
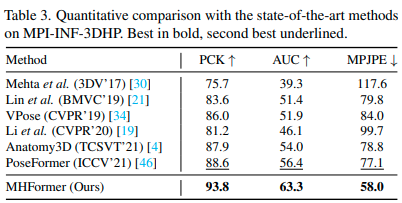
MPI-INF-3DHP 데이터셋에서 타 논문들 대비 큰 수준의 개선이 된 걸 볼 수 있습니다. (MPJPE)
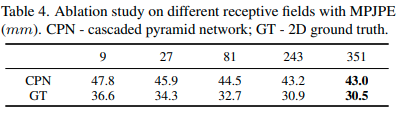
receptive field 크기에 따른 결과 비교입니다.
pretrained model도 receptive field 크기별로 제공하고 있는데,
351 프레임이면 꽤나 큰 수치임에도 제일 클 때가 가장 잘 되네요.
(MPJPE, 에러율 기준이라 낮을수록 좋습니다.)
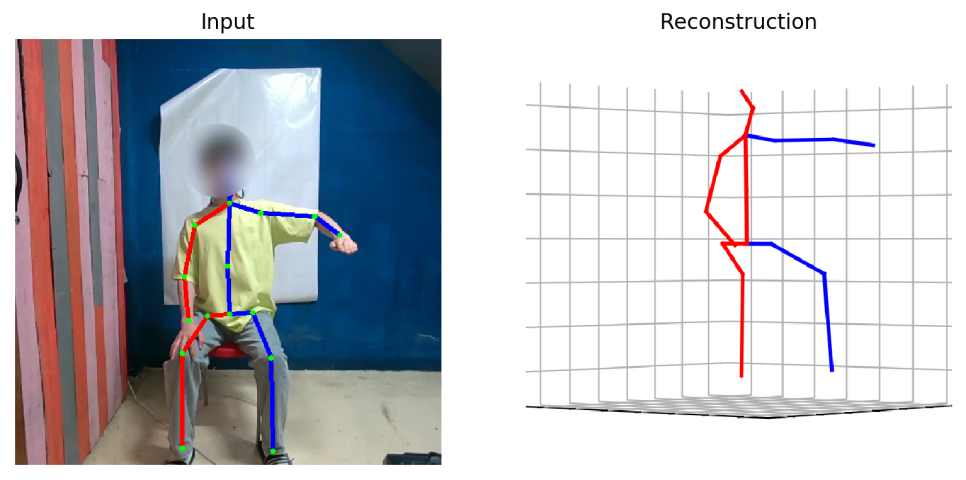
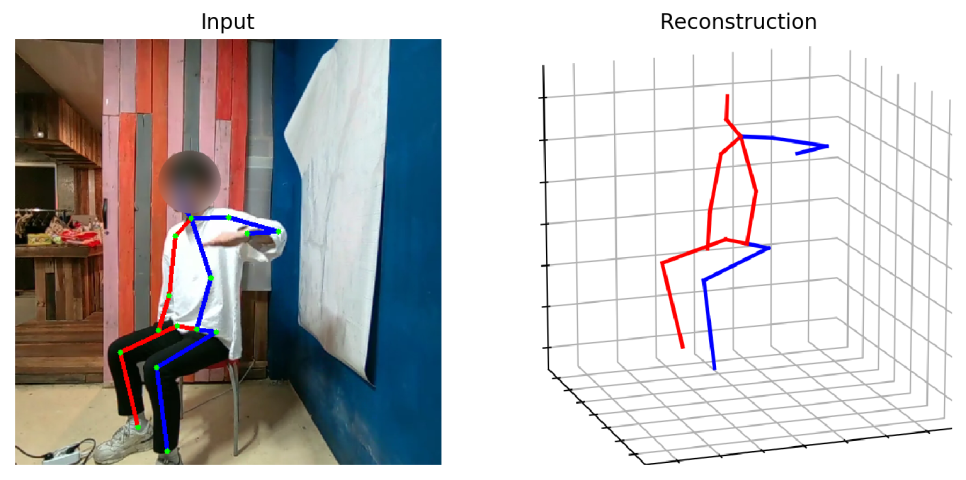
추론 결과 확인 시, 폐색에 약간 취약한 부분이 있긴 하지만 대체로 안정적입니다.
