오늘은 CVPR 2020에 발표됐던 2D Pose Estimation 논문인 UniPose를 살펴보려 합니다.
이 논문은 image sequence 데이터를 입력으로 처리하고, 다양한 크기의 receptive field를 지원하도록 설계해서 영상에 비춰진 Object(사람)의 크기에 상관없이 포즈를 잘 인식할 수 있도록 했습니다.
UniPose 논문에서 특징이 되는 '다양한 크기의 receptive field를 지원'하는 부분은 ASPP(Atrous Spatial Pyramid Pooling)라는 방법을 사용했습니다.
이 방법을 먼저 알아보겠습니다.
ASPP(Atrous Spatial Pyramid Pooling)란?
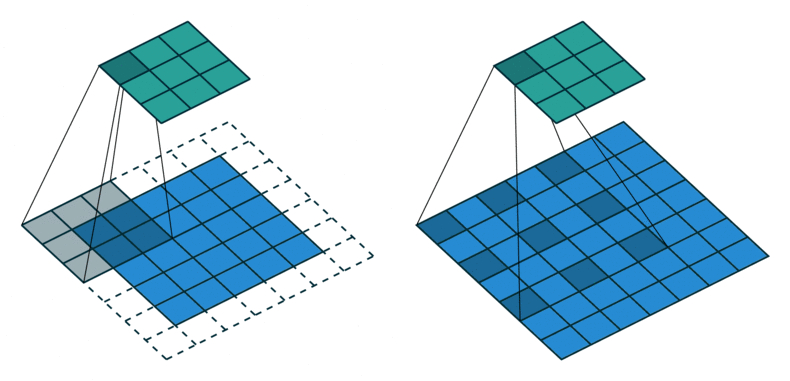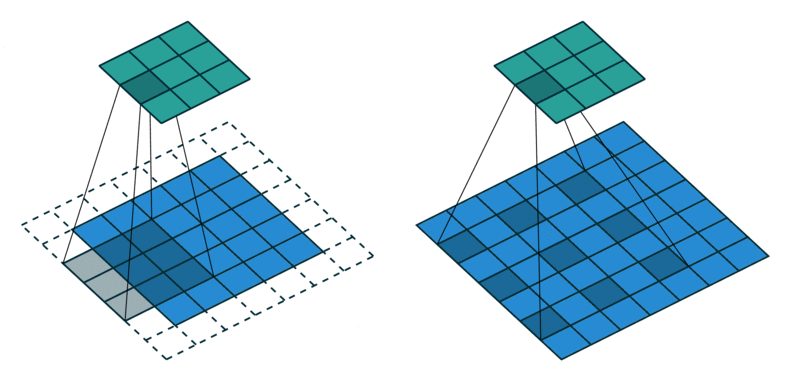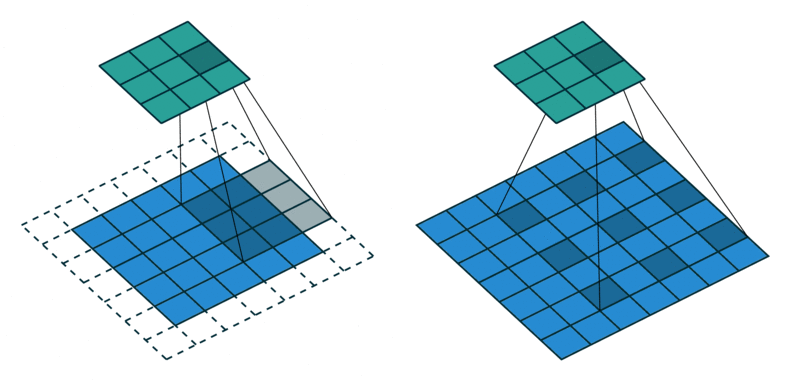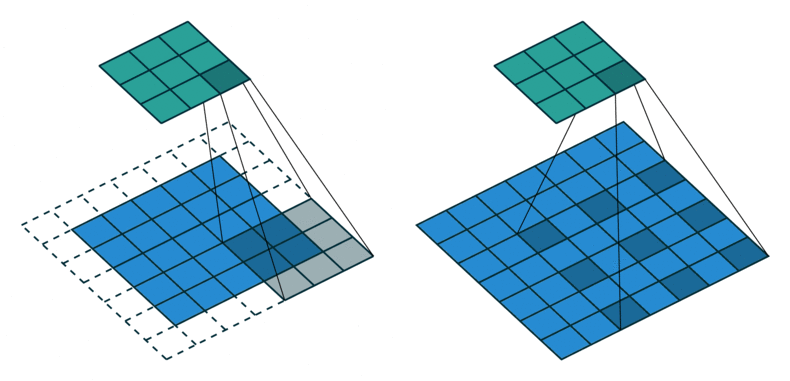
출처 : https://gaussian37.github.io/dl-concept-dilated_residual_network/
ASPP를 알기 위해서는 Atrous Convolution이 뭔지를 먼저 알아야 하는데요.
위의 그림을 보면 쉽게 이해하실 수 있습니다.
일반적인 convolution과 atrous convolution(=dilated convolution)입니다.
위 그림에서 볼 수 있듯이 Atrous convolution은 간격을 넓혀서 receptive field가 크게 만들지만, 파라미터 갯수는 늘어나지 않기 때문에 연산량 관점에서도 효율적인 연산 방법입니다.
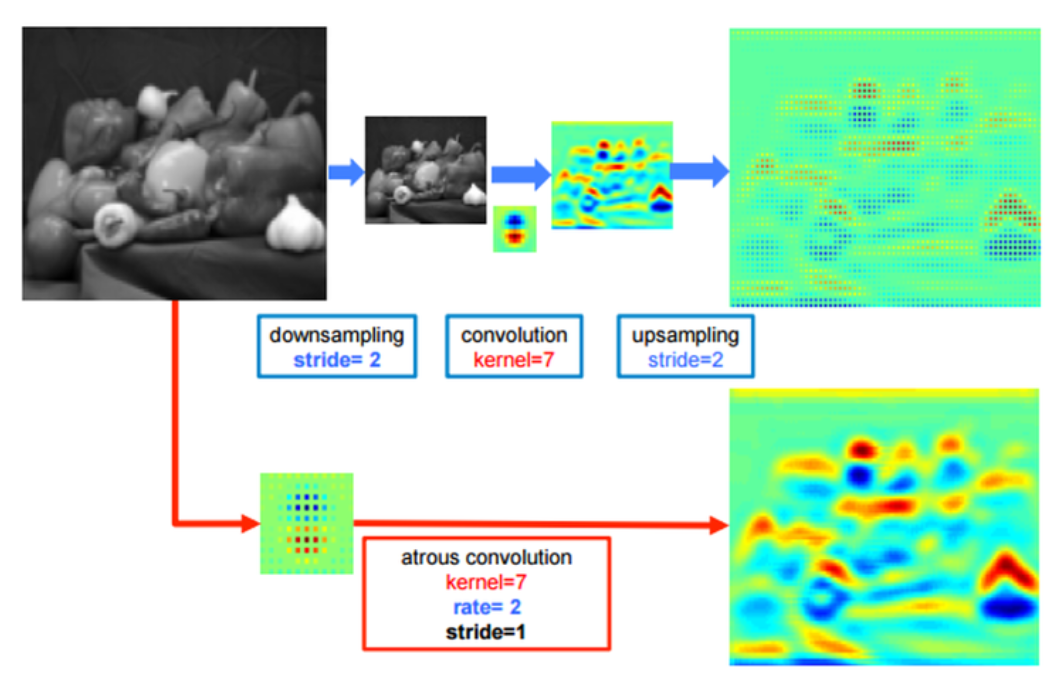
기존의 방법으로 넓은 receptive field를 보려면, input 이미지를 downsampling하고, convolution을 실행한 뒤, upsampling을 해야 합니다 (이미지의 위쪽 부분).
이 경우, upsampling과정에서 얻은 결과는 디테일이 떨어지고 이렇게 되면 모델의 최종 성능에 영향을 미칠 수도 있습니다.
반면, 아래쪽의 atrous convolution의 경우는 heatmap도 상대적으로 명확한 걸 볼 수 있고, 이는 그만큼 특징을 잘 인식한다는 걸 의미합니다.
...
출처 : https://gaussian37.github.io/vision-segmentation-aspp/
다시 ASPP로 돌아왔습니다.
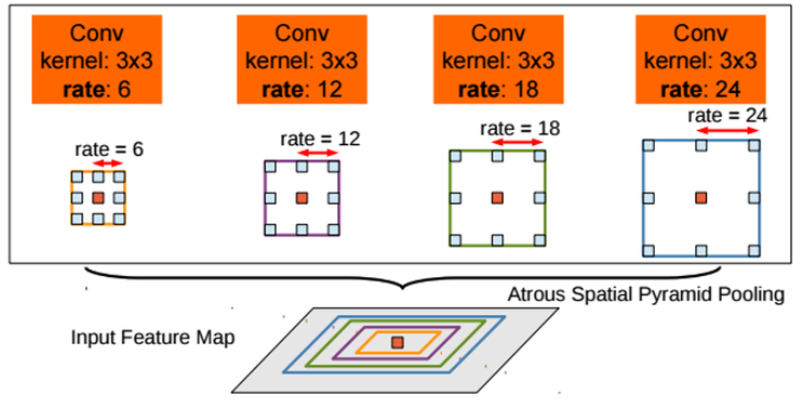
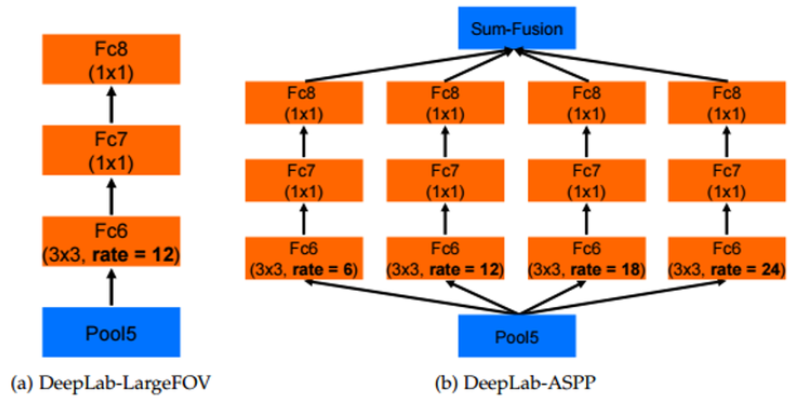
- ASPP에서는 위에서 소개한 Atrous Convolution 방법을 이용해서, multi-scale에 더 잘 대응이 가능하도록 atrous convolution에 대한 확장계수(간격)로 6,12,17,24를 적용하고 위의 그림처럼 합쳐서 사용합니다.
- 이로인해 다양한 receptive field를 활용할 수 있게 되죠!
- 파라미터 수나 계산량을 늘리지 않고 더 큰 FOV를 가지게 된다는 게 큰 장점이라고 볼 수 있습니다.
...
UniPose
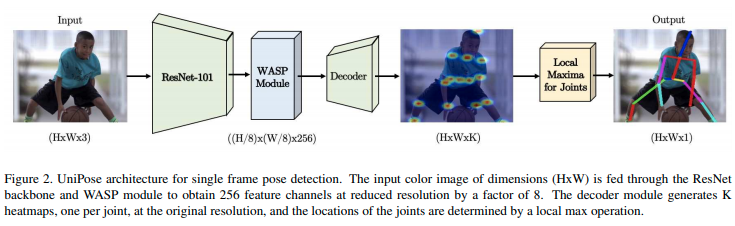
- 앞의 ASPP를 활용한 Pose 추출 모델인 UniPose의 아키텍처는 위의 그림과 같습니다.
- Input 이미지를 받아 CNN(ResNet-101)으로 feature를 추출한 뒤 WASP 모듈을 거쳐서 Decoder로 joint heatmap을 뽑아내는데요.
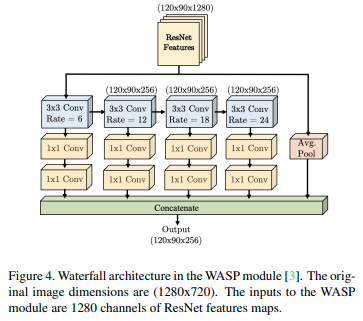
- UniPose 모델의 핵심 부분인 WASP 모듈입니다.
- WASP 모듈은 ASPP 구성으로 설계해서, 더 큰 FOV와 계단식 접근 방식의 축소된 크기를 모두 활용할 수 있도록 했습니다.
- 위 그림에서 보여지는 4개의 분기는 서로 다른 FOV를 가지며 하나씩 거쳐가도록 배열되어 있습니다.
- WASP의 atrous convolution은 6,12,18,24로 지속적으로 증가하도록 설계되었습니다.
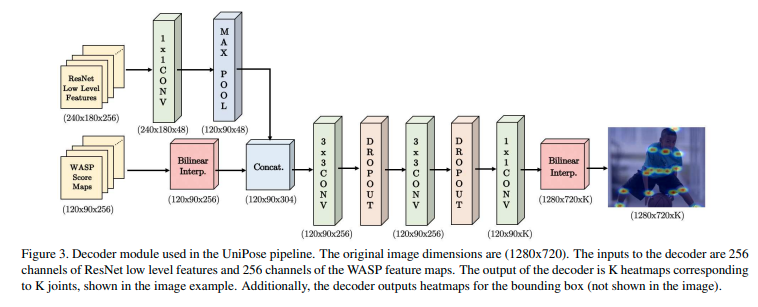
- 그 다음으로 WASP 모듈의 결과 score map과 ResNet의 Feature를 받아 처리하는 디코더입니다.
- 디코더는 WASP과 ResNet의 feature를 받아 신체 관절 및 bounding box에 해당하는 히트맵으로 변환하는 역할을 합니다.
- 디코더는 WASP에서 256개의 feature map을 받고, ResNet backbone의 첫번째 블록에서 256개의 low level feature map을 받습니다.
- 입력 차원을 일치시키기 위해 Max pooling 작업 후 feature map을 concat하고, 원래의 입력 크기로 조정하기 위해 Convolution, dropout layer 및 bilinear interpolation을 통해 처리됩니다.
- 디코더의 출력은 K개의 관절에 해당하는 K개의 히트맵으로 구성됩니다.
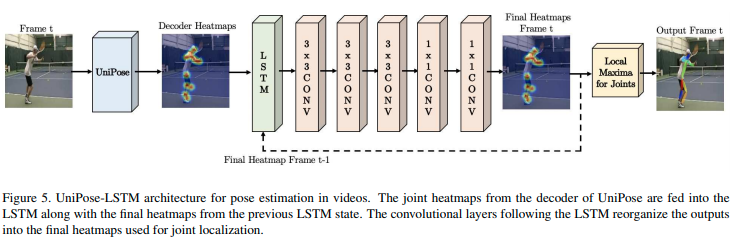
- 그리고 이러한 UniPose의 형태를 영상 포즈 추정에 확장시키기 위해 LSTM 모듈을 활용합니다.
- 위의 그림을 보면, 현재 프레임의 디코더 히트맵과 이전 프레임의 최종 히트맵을 받아서 LSTM 모듈로 처리하는 걸 볼 수 있습니다.
- LSTM에 최대 5개 프레임을 통합할 때의 정확도가 제일 좋은 걸로 확인됐다고 합니다.
- 이를 통해 sequence 이미지에서 더 잘 포즈 추정이 되도록 개선하였고, 3D Pose로 확장해서 Unipose+ 라는 논문도 냈는데 코드는 아직 출시 예정이라고만 나와있는 상태입니다.
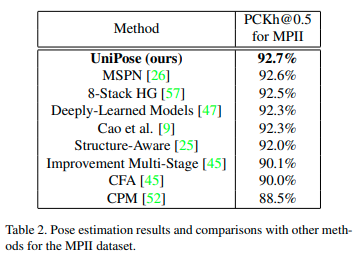
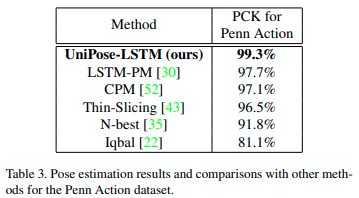
결과를 보시면 Pen Action, MPII에서 가장 좋은 성능이 나온 걸 볼 수 있습니다.
넥스트도어 장우일이었습니다.
긴 글 읽어주셔서 감사합니다.
부족하거나 궁금한 부분이 있으시면 댓글 부탁드리겠습니다.
참조
