SQLD 자격증은 있지만, 다 까먹고 다시 공부하기!

작년 12월 SQLD 자격증을 취득했다.
SQLD 합격은 했지만 막상 백엔드 엔지니어로서 프로젝트를 시작하려고 보니 DB 구성을 할 때 어떻게 해야 할 지 감이 안 잡힌다.
1년 전의 기억을 톺아보고자, 데이터베이스 관련 영상들과 그 당시 공부했던 자료들을 다시 보려고 한다. 해당 게시글에 공부했던 것들과 기억나는 것들을 다시 정리하면서 공부해보자!!
- 정규화
참고자료 : 10분CS지식 쉽게 설명하는 데이터베이스 정규화
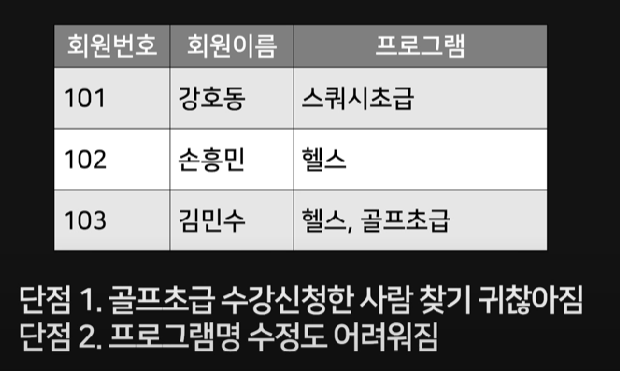
김민수라는 회원이 헬스와 골프초급 프로그램을 신청했을 때, 만약 이 데이터를 한 줄에 정리한다면 다음과 같은 단점이 발생한다. 골프초급을 수강신청한 사람을 찾기 위해서는
WHERE 프로그램 LIKE '%골프초급%' 처럼 검색해야 하는 등 과정이 복잡해진다. 또한 다른 단점으로는 프로그램 수정도 어려워진다.
이를 해결하기 위해, 한 칸에 하나의 데이터만 넣어야하며 이를 제1정규화라고 한다.

위 테이블에서 프로그램마다 가격과 납부여부가 추가 되었다. 만약 헬스 프로그램이 가격이 6000원에서 7000원으로 수정된다면 어떻게 해야할까? 해당 테이블이라면 모든 6000원 테이블을 찾아 7000원으로 수정해줘야한다.(몇 십 만개가 있더라도 말이다!)
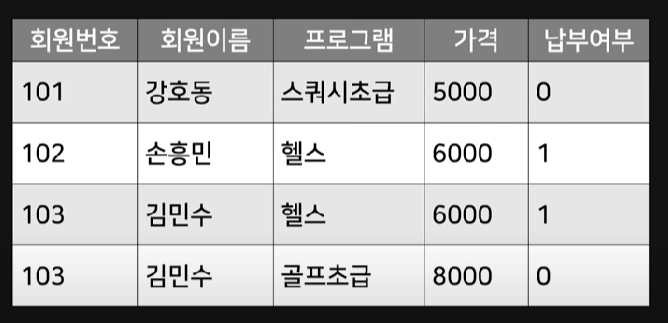
이런 불상사를 해결하기 위한 것이 제2정규화다. 제2정규화는 현재 테이블의 주제와 관련없는 컬럼을 다른 테이블로 빼는 작업을 이야기한다.
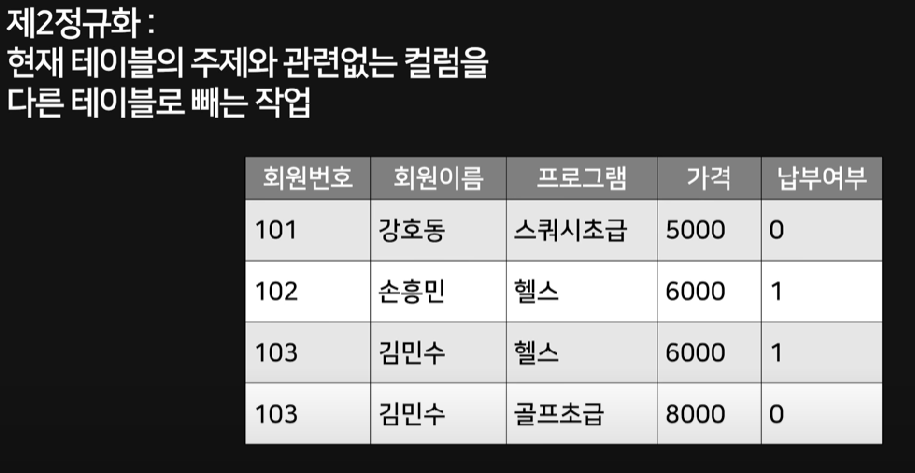
'수강등록현황' 테이블에 프로그램 가격은 관련 있는 데이터가 아니므로 빼버리면 된다. '프로그램' 테이블을 만들면 끝!
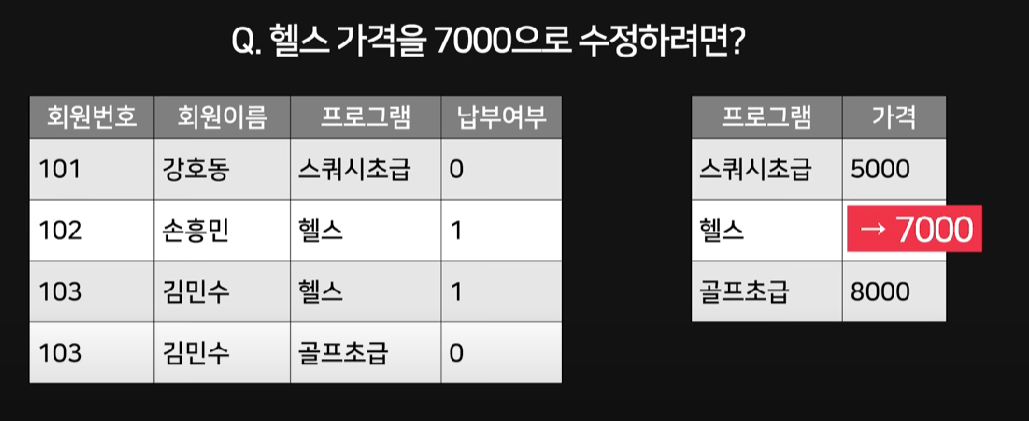
비관계형 DB는 정규화를 안 하는 경우가 많지만 관계형 DB는 정규화를 해줘야 한다.

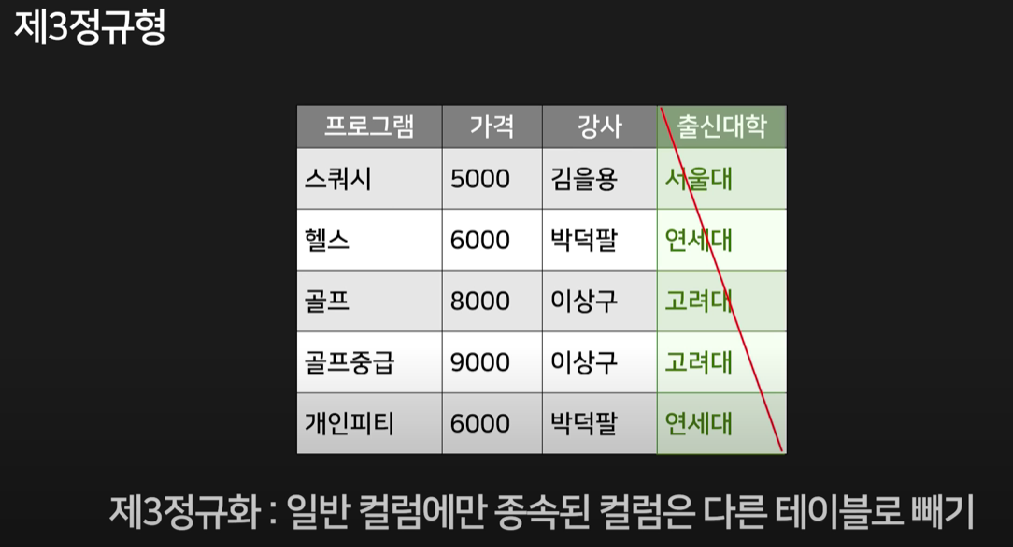
프로그램 테이블에 강사와 출신대학을 추가해보자. 테이블 내 컬럼 간 partial dependency가 존재하지 않기 때문에 제2정규형 테이블임을 확인할 수 있다.

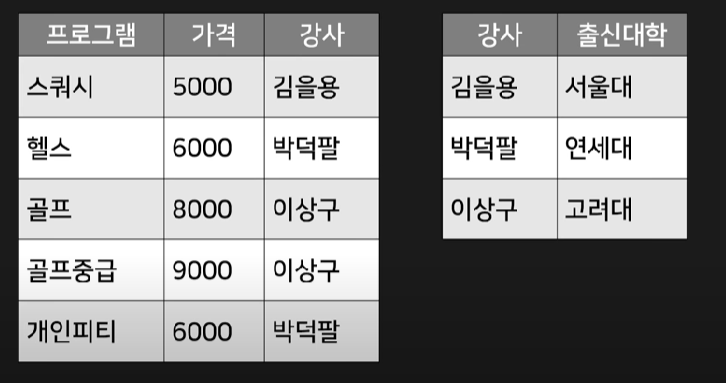
출신대학을 주목해보면, 일반 컬럼(프로그램, 가격)이랑 상관이 없고 특정 컬럼(강사)에만 종속된 컬럼이다. 이렇게 특정 컬럼에 종속된 컬럼은 다른 테이블로 빼는 것을 제3정규화라고 한다.