BOJ - 케빈 베이컨의 6단계 법칙
알고리즘 스터디를 하면서 이 문제를 풀다가 최단거리 알고리즘를 다시 공부해야겠다는 생각이 들었다.
이전에 정리했던 내용을 토대로 복습해보았다.
최단거리 알고리즘
- Shortest Path Algorithm. 주로
그래프와 함께 사용되는 알고리즘이다. - 최단거리를 구할 수 있는 다양한 알고리즘이 존재하는데, 가장 많이 쓰이는
BFS부터Dijkstra,Floyd-Warshall,Bellman-Ford,A*,SPFA등이 있다.
왜 많은가?
가장 좋은 것을 고를 수 있었다면 좋겠지만, 성능에서 완벽히 비교우위를 점하는 알고리즘이 없기 때문이다.
아래는 ChatGPT에 물어본 각 알고리즘의 비교표이다.
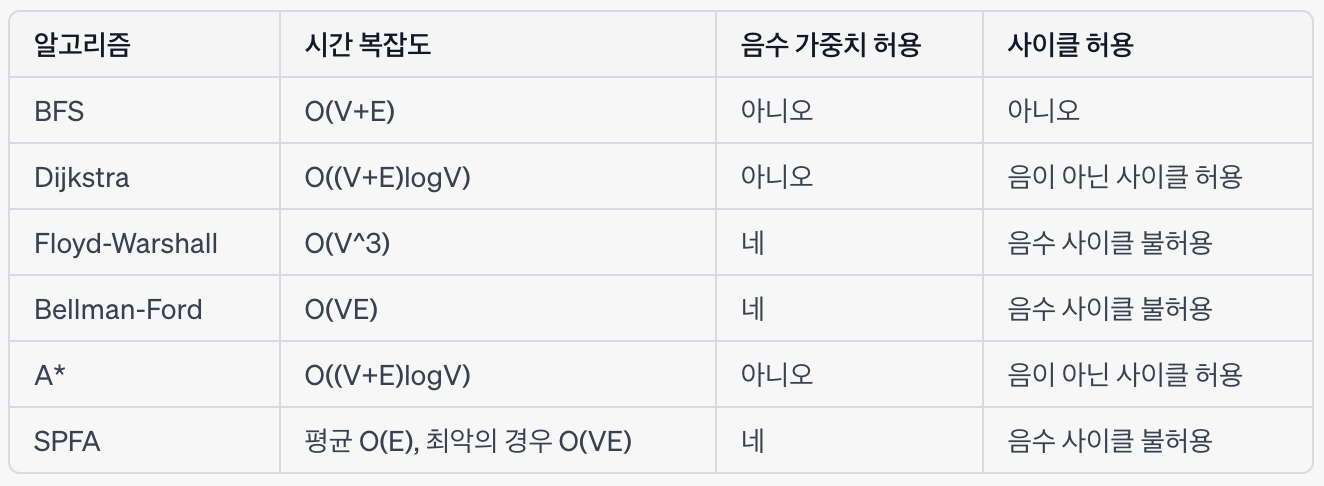
정확한 내용인지는 확실하지 않다...
표를 보면 상황별로 다른 알고리즘을 써야겠다는 생각이 들 것이다.
bfs는 많이 사용해봤으니, Dijkstra, Floyd-Warshall, Bellman-Ford 세 가지에 대해서만 살펴보겠다.
Dijkstra
- 매 단계에서 가장 비용이 낮은 노드를 선택하여 최단거리를 구하는
그리디 알고리즘이다. - 간선의 가중치가 음수만 아니라면 사용가능하다.
- 주로
한 노드를 기준으로 다른 노드들로 가는 최단 경로를 한번에 찾을 때 사용한다.
동작 방식
메인 아이디어는 아는 정보들로 새로운 정보(탐색 후보)를 갱신하는 것이다.
- 모든 노드의 최소 비용을 'INF'로 설정
- 시작 노드의 비용을 0으로 설정
- 현재 노드의 모든 이웃에 대해 비용 계산
- 비용이 현재 기록된 비용보다 적으면 갱신
- 방문하지 않은 노드 중 최소 비용을 가진 노드를 선택
- 모든 노드를 방문할 때까지 3,4를 반복
이렇게 하면 이전까지 탐색한 노드들은 최소 비용을 갖는다는 사실이 보장된다.
여기서 방문하지 않은 노드 중 최소 비용을 가진 노드를 선택할 때, 어떤 자료구조를 사용할 것인지가 중요하다.
최소 비용을 가진 노드를 계속해서 확인할 수 있는 자료구조에 가장 적절한 것은 Priority Queue이다.
Python에서는 'Heapq'라이브러리를 사용해서 구현할 수 있다.
from collections import heapqHeapq를 매우 간단하게 설명하면 가장 작은 값이 맨 앞에 오는 자료구조(파이썬 기준)이다.
주의할 점은 음의 가중치가 있어서는 안된다.
코드 예시
- 1번 노드를 기준으로 다른 노드들까지의 최단거리를 구하는 코드이다.
import heapq
import sys
INF = sys.maxsize
n, m = tuple(map(int, input().split()))
adj = [[] for _ in range(n + 1)]
for _ in range(m):
s, e, w = list(map(int, input().split()))
adj[s].append((e, w))
# 1. 모든 노드의 최소비용을 INF로 설정
dist = [INF] * (n + 1)
# 2. 시작 노드의 비용을 0으로 설정
source = 1
dist[source] = 0
q = []
heapq.heappush(q, (0, source)) # 우선순위 큐에 시작 노드 추가
while q: # 큐가 빌 때까지 실행
# 4. 방문하지 않은 노드 중 최소 비용을 가진 노드를 선택
distance, cur = heapq.heappop(q)
if dist[cur] < distance: # 이미 최단 거리를 찾은 경우 pass
continue
# 3-1. 현재 노드의 모든 이웃에 대해 비용 계산
for v, w in adj[cur]:
cost = distance + w
# 3-2. 비용이 현재 기록된 내용보다 적으면 갱신
if cost < dist[v]: # 더 짧은 경로 발견 시, 경로 갱신
dist[v] = cost
heapq.heappush(q, (cost, v)) # 우선순위 큐에 추가Floyd-Warshall
모든 정점 사이의 최단거리를 한 번에 구하기위한DP에 가까운 알고리즘이다.- 음수 가중치, 사이클 허용한다.
- 노드의 수가 적고, 모든 노드 쌍 사이의 최단 경로를 알아야 할 때 효율적이다.
동작 방식
메인 아이디어는 경유지(k)로 사용가능하도록 하나의 정점에 대한 제한을 풀어주는 것이다.
- dist[x][y] := x에서 y의 최단 거리. 불가능하면 -1
- dist 초기상태: 모든 노드 쌍의 거리를 저장하고, 간선이 없는 노드 쌍의 거리는 무한대로 설정
- 경유지인 k에 대해서
dist[i][k] + dist[k][j]와dist[i][j]를 비교하여 최단 거리를 선택- 모든 노드에 대해 이 과정을 반복
Floyd-Warshall의 가장 큰 장점은 모든 정점 간의 최단 거리를 한번에 구할 수 있고 구현이 굉장히 쉽다는 것이다.
코드 예시
- 1번 노드를 기준으로 다른 노드들까지의 최단거리를 구하는 코드이다.
for k in range(1, n + 1):
for i in range(1, n + 1):
for j in range(1, n + 1):
dist[i][j] = min(dist[i][j], dist[i][k] + dist[k][j])
# i -> j 직접 가는 거리 vs. i -> k -> j 경유 거리Bellman-Ford
- 모든 노드에 대해, 그래프의
모든 간선을 한 번씩 검사하면서 간선의 시작점에서 끝점까지의 거리를 갱신하려고 시도하는 알고리즘이다. - 음수 가중치를 가진 간선도 처리 가능
- 음수 가중치를 가진 순환(cycle)에 대해서는 불가능
동작 방식
- 초기화: 출발 노드의 거리 값을 0으로 설정하고, 그 외의 모든 노드의 거리 값을 무한대로 설정합니다.
- 간선 완화: 그래프의 모든 간선에 대해, 현재의 시작점에서 끝점까지의 거리가 기존의 거리보다 작으면 거리 값을 갱신합니다. 이 과정을 전체 노드의 수 - 1번 반복합니다.
Bellman-Ford 알고리즘은 음의 사이클을 체크할 때 사용할 수 있다.
- 음의 사이클 체크: 만약 더 이상 거리 값을 갱신하지 않는데도 불구하고 더 짧은 경로가 존재한다면, 그래프에 음의 사이클이 존재하는 것으로 판단
수도 코드
function BellmanFord(graph, source):
// Step 1: 초기화
distance[source] = 0
for each vertex v in graph: // 모든 노드들에 대해
if v ≠ source
distance[v] = ∞ // 출발 노드를 제외한 모든 노드의 거리는 무한대로 설정
predecessor[v] = undefined // 출발 노드를 제외한 모든 노드의 이전 노드는 정의되지 않음
// Step 2: 간선 완화
for i from 1 to size(vertices)-1: // 전체 노드의 수 - 1 번 반복
for each edge (u, v) with weight w in edges: // 모든 간선에 대해
if distance[u] + w < distance[v]:
distance[v] = distance[u] + w // 현재 간선을 거쳐가는 것이 더 짧으면 거리를 갱신
predecessor[v] = u
// Step 3: 음의 순환 체크
for each edge (u, v) with weight w in edges:
if distance[u] + w < distance[v]: // 더 이상 거리 갱신이 없어도 더 짧은 경로가 존재한다면
return "Graph contains a negative-weight cycle"
return distance, predecessor
정리
세 가지의 서로 다른 최단거리 알고리즘에 대해 알아보았다. 사용가능한 경우와 불가능한 경우가 서로 다르고, 시간복잡도 또한 달라서 문제와 상황에 따라 적절한 알고리즘을 선택하는 것이 중요하다.
