스파르타코딩클럽 3주차
지니뮤직 21년의 월간차트를 크롤링하자.
처음에 겁도 없이 최근 월간차트를 했더니 문자 투표 관련 메시지가 쭉 나와서 학원에서 제시한 21년의 월간차트를 이용하기로 했다.
근데... 나 잘 할 수 있을까?
처음 코드를 뽑기로 했다.
import requests
from bs4 import BeautifulSoup
# 타겟 URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20210701',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
title = soup.select_one('#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.title.ellipsis')
rank = soup.select_one('#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.number').text
artist = soup.select_one('#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.artist.ellipsis').text
print(title, rank, artist)
처음 시도는 좋았다.
"나는 타이틀을 전부 뽑아보고 싶다~~~"
import requests
from bs4 import BeautifulSoup
# 타겟 URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20210701',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for tr in trs:
title = tr.select_one('td.info > a.title.ellipsis').text.strip()
print(title)
# rank = soup.select_one('#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.number').text.strip()
# artist = soup.select_one('#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.artist.ellipsis').text.strip()
# print(title)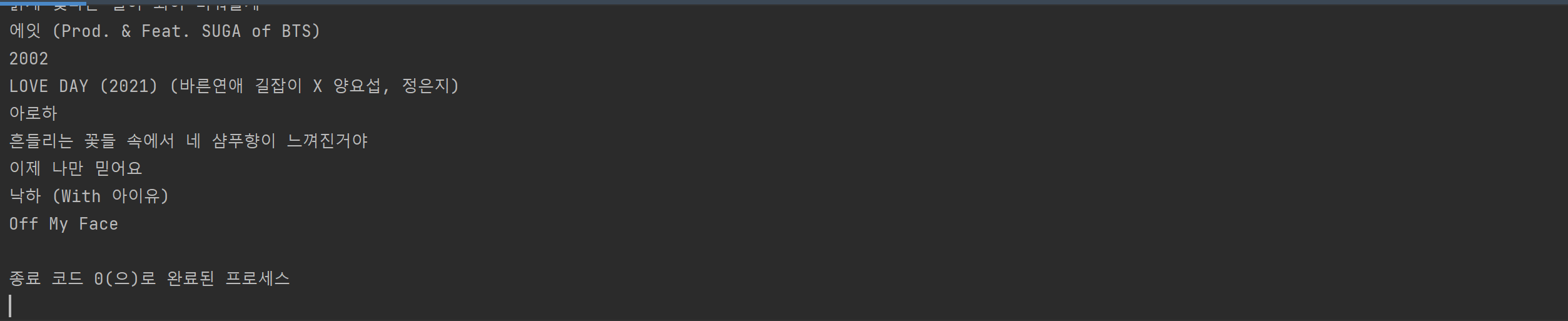
물론, 중간에 
이런 경우는 지워지지 못했다만, 대부분의 공백은 지워졌다.
strip()은 여기서 확인하기 : https://codechacha.com/ko/python-string-strip/
"나머지도 시도해버려~~~"
import requests
from bs4 import BeautifulSoup
# 타겟 URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20210701',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for tr in trs:
rank = tr.select_one('td.number').text.strip()
title = tr.select_one('td.info > a.title.ellipsis').text.strip()
print(rank, title)
# rank = soup.select_one('#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.number').text.strip()
# artist = soup.select_one('#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.artist.ellipsis').text.strip()
# print(title)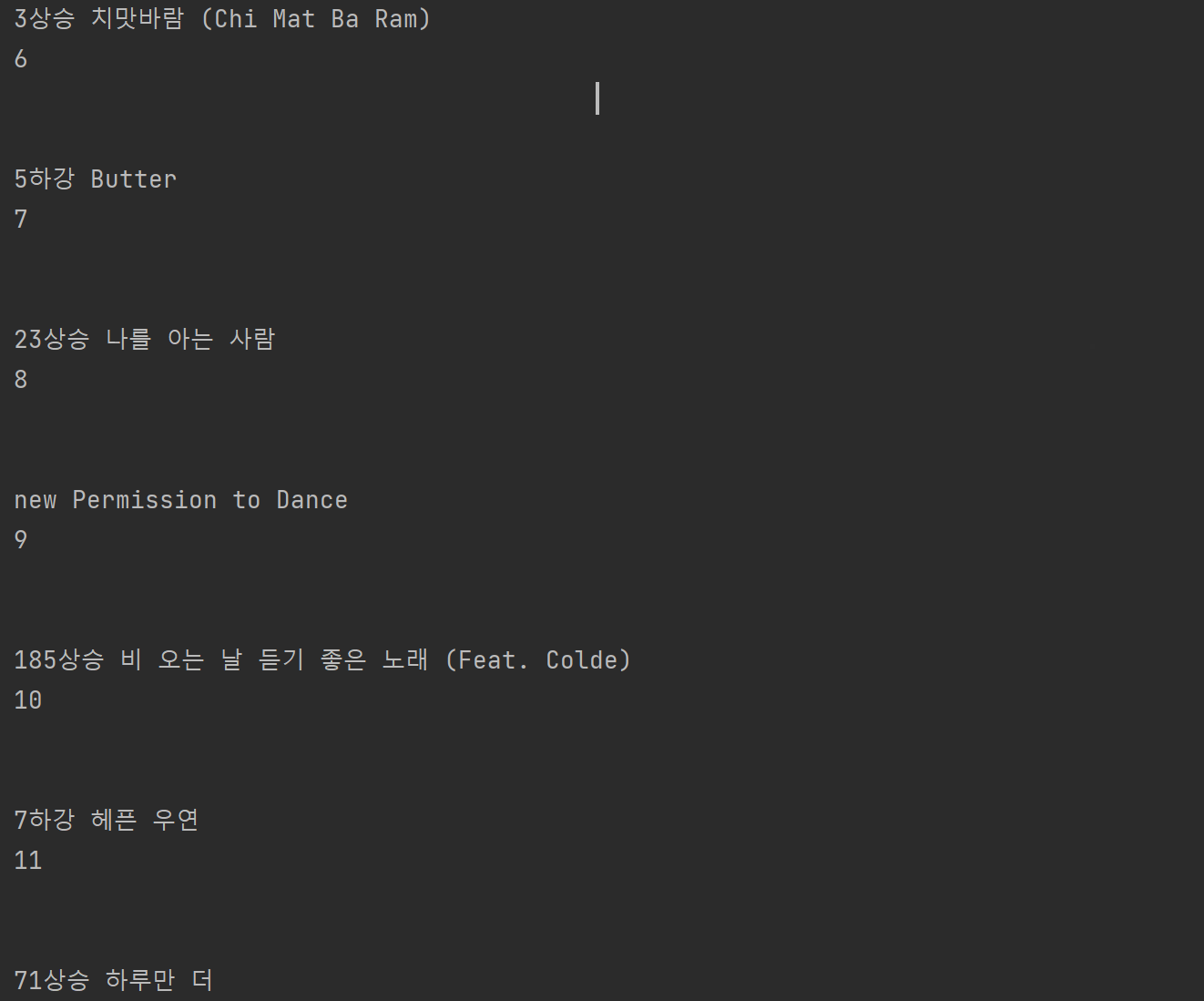
오... 나름 재밌게 되었다.
나는 이런 결괏값을 바라는 게 아니었다.
찾아보니 텍스트 슬라이싱하면 된다고 하기에 그걸 쓰기로 했다.
참고링크 : https://wikidocs.net/2838
import requests
from bs4 import BeautifulSoup
# 타겟 URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20210701',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#body-content > div.newest-list > div > table > tbody > tr')
for tr in trs:
rank = tr.select_one('td.number').text[0:2].strip()
title = tr.select_one('td.info > a.title.ellipsis').text.strip()
artist = tr.select_one('td.info > a.artist.ellipsis').text.strip()
print(rank, title, artist)
# rank = soup.select_one('#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.number').text.strip()
# artist = soup.select_one('#body-content > div.newest-list > div > table > tbody > tr:nth-child(1) > td.info > a.artist.ellipsis').text.strip()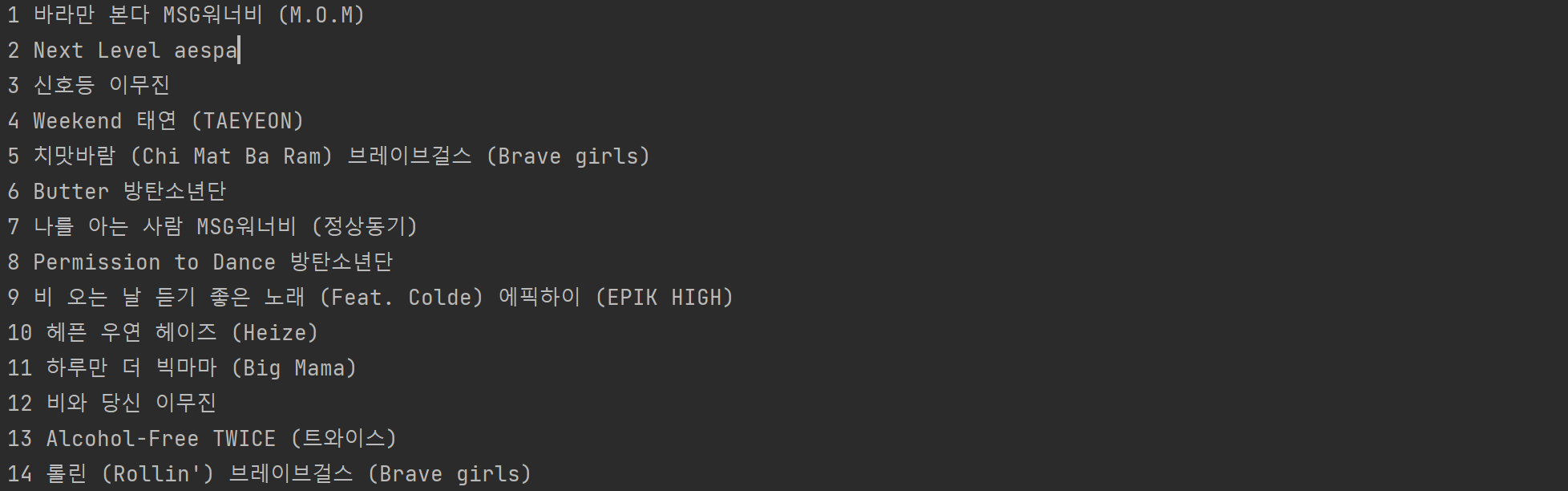
얼추 원하는 대로 된 것 같다. 중간에 15위에 랭크된 19금이란 곡은 제대로 안되어 어쩔 수 없지만, db에 넣게 된다면 별도로 수정을 하면 될 것 같다.
후기
처음 크롤링이 어려웠는데, 구글링하면서 다시 해보고, 또 슬라이싱 등을 복습할 수 있는 시간이 되어 좋았다. 역시 여러번 하라는 계신가...
다만, 이번 주차에서 몽고 db 아틀라스 연결이 안 되어 로컬로 하는 법을 별도로 배웠다.
아틀라스 안 되는 사람은 로컬로 연결해서 하는걸 추천한다.

무언가를 하고 있지만, 잘 안될 수 있습니다.