마이크로서비스 내 효과적인 DB 설계
지겨운 msa...하지만 그만큼 성공적으로 전환한다는 것 또한 어렵다.
먼저 이를 위해서는 마이크로서비스의 목적을 정확하게 생각해봐야한다.
각 서비스를 분리해서 제공한다로 끝나지 않는 것!
- RESTful API가 적용된 프로젝트
- 독립적인 배포가 가능하도록 결합도를 낮춘 프로젝트
-> 서비스의 수정이 발생하여도 다른 서비스로의 영향이 없거나 적기 때문에, 독립적인 개발 및 배포가 가능하고 그만큼 테스트와 유지보수도 쉬워지는 것
마이크로 서비스 아키텍처는 기술셋에 의존된 설계 방식이 아니라 목표를 수립하고 달성하기 위해 기술셋을 선택하는 방식으로 접근하는게 좋다는 말이 인상깊었다.
마이크로 서비스를 사용하는 데 있어 중요한 영향력을 갖는 부분은 데이터 처리이다.
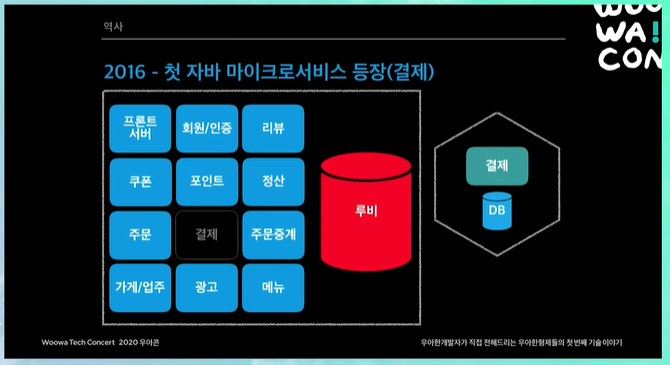
배민에서 마이크로 서비스를 도입했다고 했을 때에도 해당 서비스와 함께 DB가 완전 분리되었다.
물론 MSA!!! 오키!! DB 분리 고!! 라고 하면 좋지만, 현실적으로 어플리케이션의 구조적 변화가 심하게 일어나는 상황에서 위험도가 높아질 수 있다.
리스크를 최소화하며 마이크로서비스로 전환해 나가기위해서는 백엔드 → 데이터베이스(데이터) → 프론트엔드 순으로 점진적인 변화를 가져가는 것이 효과적이다.
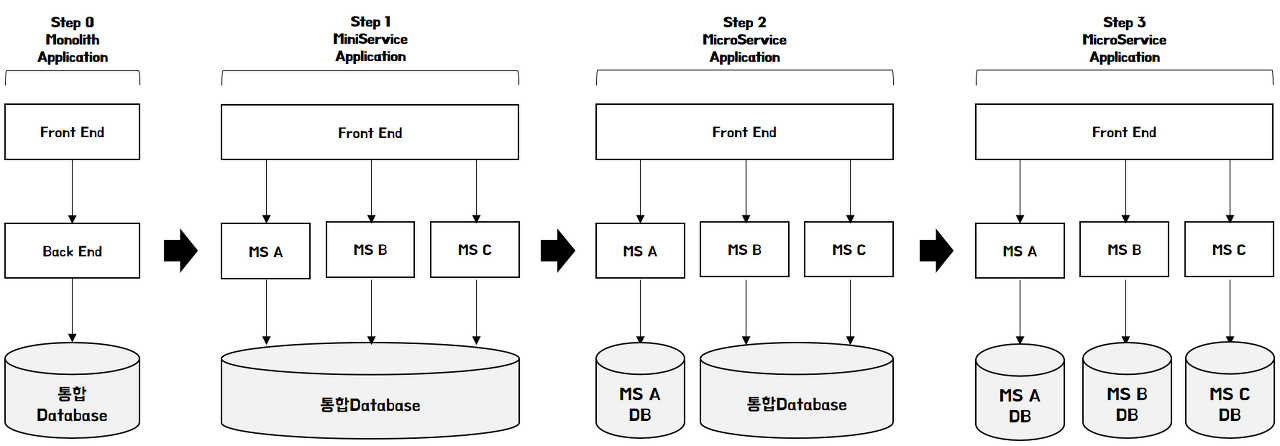
아키텍쳐의 변화
데이터베이스를 분리하게 될 경우, 발생할 수 있는 변화가 많다.
인프라 아키텍쳐
- 비용 : 데이터베이스의 물리적 노드 증가에 따른 비용 증가, 구축/운영 인력 증가
- 성능 : 호출 홉 증가에 따른 성능 저하, 데이터 전송에 따른 성능 저하
- 인력 : 기술셋 확장에 따른 지원 인력 증가
- 모델링 : 마이크로서비스 인터페이스 모델링, 데이터베이스 모델링(테이블 분할 설계 / 데이터 오너쉽 정의 등)
어플리케이션 아키텍쳐
서비스 간의 데이터 동기화 측면에서 고려할 사항들이 있다.
1. 조인 쿼리 : 모놀리식 어플리케이션 내 조인 쿼리에 대응하기 위한 동기/비동기 처리 호출 설계
2. 트랙잭션 관리 : 분산 트랜잭션 관리를 위한 이벤트 처리 설계
3. 보상 트랜잭션 : 데이터 복구를 위한 Saga 패턴 설계
4. API 증가 : 데이터 호출 증가에 따른 API 설계
5. 배치 : 배치 아키텍쳐 설계를 위한 데이터 통합 방안 설계
개발의 변화
테이블 재설계는 물론 데이터 오너쉽 정의, 배치처리 업무, 서비스 연관도 분할, MSA 비 대상 서비스와의 결합도 약화, 인터페이스 개발, 비즈니스 개선, 프로세스 개선 등 개발에서 확장된 업무들이 개발자의 역할로 부여 받게 된다.
이로 인해 개발자는 정확한 공수 산정 및 개발에 필요한 기술셋, 일정 등을 사전에 파악하기 어려워 무엇보다 개발 PL의 역할이 중요해진다.
데이터베이스를 구분하는 것은 단순히 물리적인 공간을 구분하는 것이 아닌 데이터의 정합성, 연속성을 보장하기 위해 많은 노력과 비용이 발생하는 아키텍처 패턴임을 명심해야 한다. 하지만 DB 분리를 위해 얻을 수 있는 장점과 기회비용을 면밀히 판단하여 점진적으로 변화를 꾀한다면 성공적으로 MSA로 전환할 수 있을 것이다.
단일 DB 패턴
기존 모놀리스 서비스 내 단일 DB 환경의 문제점은 아래와 같다.
마이크로서비스 간 정보 보호(은닉)의 어려움
데이터 통제의 어려움
결합도 증가에 따른 서비스 배포 독립성 확보 불가
마이크로 서비스 간 독립 DB 사용
각 마이크로 서비스가 자체 데이터를 소유하고 비즈니스를 서비스 내에서 처리할 수 있도록 데이터베이스를 분할하는 가장 이상..?적인 패턴이다.
신규 서비스를 이와 같은 형태로 설계하면 가장 좋긴 하다만.. 현행 서비스가 존재하고 단일 DB가 존재할 때 데이터의 결합도를 끊어낼 수 있도록 설계하는 것은 어려운 일이다.
이를 위해서는 서비스를 재분류하는 작업부터 시작해서 독립적인 스키마를 갖도록 설계해야 한다.
데이터 공유 방식 (View)
각 서비스 간 데이터의 완전한 분리가 불가능하다면, 서비스당 2개 이상의 데이터베이스에 접근하는 방법을 선택할 수 있다. 각 서비스가 독립적인 DB를 갖고, 서비스 간 데이터 조회가 필요한 경우 View를 사용함으로 결합도를 낮출 수 있다. View를 사용함으로 서비스에 표시되는 데이터를 숨기거나, 조인을 수행한 후 View로 제공할 수 있다.
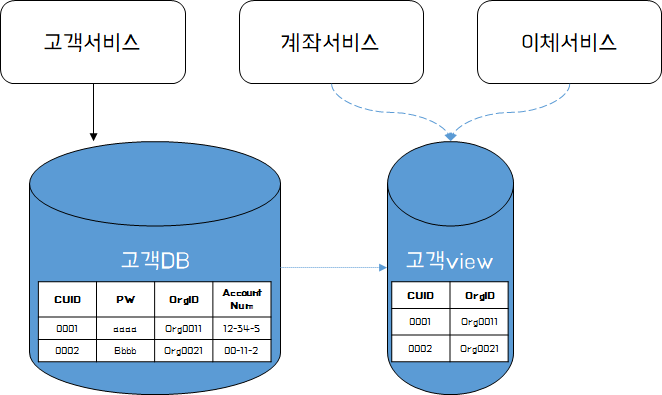
이 때 고려해야할 점은 View를 사용하여 성능이 향상될 수 있긴 하지만, View를 갱신하는 방식에서 데이터 정합성을 고려해야한다. (이건 ReadOnly의 전형적 이슈긴 함)
그리고 view를 사용함으로 데이터베이스에 직접 접근하는 방식보다는 결합도를 낮출 수 있긴 하지만, 여전히 read가 한 데이터베이스 내에서 발생한다는 점 또한 인지해야한다.
공통 마이크로서비스 활용
각 서비스가 각 데이터를 관리하고 서비스를 하면 좋지만 현실적으로 어려운 경우, 공통 서비스를 생성하고 Shared Data를 관리하는 방식을 고려할 수 있다.
즉 각 서비스 에서 개별적으로 사용하는 데이터는 각 서비스의 DB에 저장하고, 공통으로 사용하는 데이터 또는 상호 공유되어야 하는 데이터를 공통 서비스 내 공통 DB에 저장하는 것이다.
통서비스는 Front 서비스에게 공통 데이터를 직접 액세서 할 수 있도록 엔드포인트를 제공하고, 마이크로서비스 간에는 공통 데이터 또는 공유 데이터를 조회할 수 있는 API를 제공한다. 고객/계좌/이체(호출자) 서비스는 DB에 직접 액세스 하지 않고 API를 호출하여 결과를 전달 받는 방식으로 구현한다.
라는데 솔직히 명확하게 머리에선 이해가 잘 안간다.....
ReadOnly DB 활용
타 마이크로 서비스의 데이터를 CUD하는 경우에는 API, 조회는 ReadOnly DB를 이용하는 방식이다.
ReadOnly DB로 복제할 때 데이터 정합성 등을 염두에 두어 구현 방안을 설계해야한다.
그렇지만!!!!!!
물리적으로 독립된 DB를 사용하는 것은 비용, 유지보수적인 문제점이 많다.
Hibernate와 같은 프레임워크에 의해 백업되는 저장소 계층을 가지고 코드를 데이터베이스에 바인딩하여 객체나 데이터 구조를 데이터베이스와 쉽게 매핑할 수 있도록 하는 것이다.
