📒 인덱스란?
데이터베이스의 테이블에 대한 검색 속도를 향상시켜주는 자료구조
테이블에 특정 컬럼에 인덱스를 생성한다는 것은 해당 컬럼의 데이터를 정렬한 후 별도의 메모리 공간에 데이터의 물리적 주소와 함께 저장한다는 것을 의미한다. 컬럼의 값과 물리적 주소를 (key , value)의 한 쌍으로 저장하는 것이다.
인덱스는 목차, 색인의 역할을 한다!
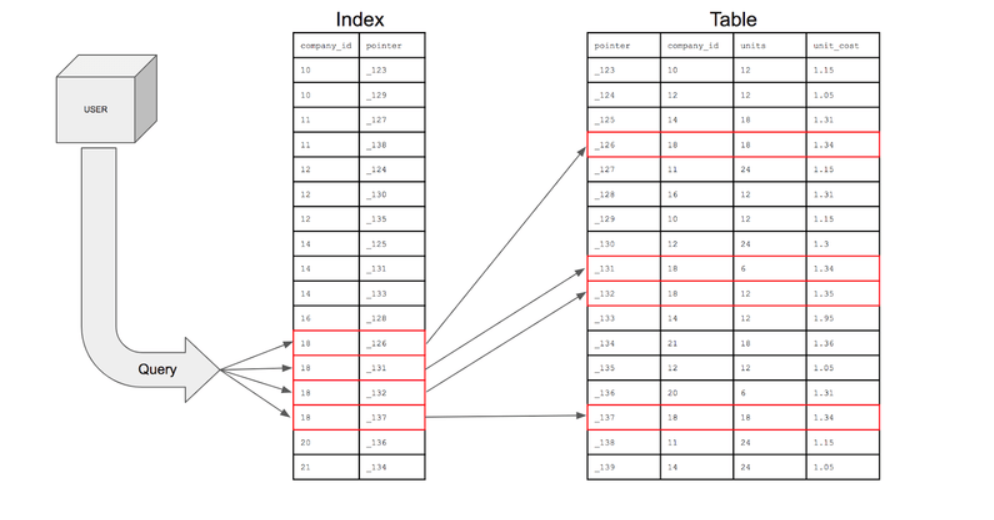
https://mangkyu.tistory.com/96
📒 인덱스의 장단점
🟠 장점
테이블을 검색하는 속도와 성능이 향상된다. 기존 where문을 사용할 때 테이블 전체를 조건과 비교하는 Full Table Scan 작업이 필요한데, 인덱스 사용시 데이터가 정렬된 형태로 있기 때문에 데이터를 빠르게 찾을 수 있다.
🟠 단점
인덱스를 관리하기 위한 추가 작업이 필요하며, 추가 저장 공간이 필요하다.또한 잘못 사용하는 경우 오히려 검색 성능의 저하가 일어날 수 있다.
++ 인덱스가 적용된 칼럼에 삽입, 삭제, 수정이 잦다면 인덱스 또한 수정해야하기때문에 성능이 낮아진다. 또한 인덱스는 제거되는 것이 아니라 '사용하지 않음'으로 남겨두기 때문에 인덱스가 과도하게 커질 수 있다.
🟠 인덱스를 사용하면 좋은 경우
- 규모가 큰 테이블
- 삽입, 수정, 삭제 작업이 자주 발생하지 않는 컬럼
- WHERE 이나 ORDER BY, JOIN 등이 자주 사용되는 컬럼
- 데이터의 중복도가 낮은 컬럼
인덱스에 대해 뭔가 제대로 언급된 걸 본 적이 없어서 인덱스의 장점이나 사용해야하는 이유에 대해서는 쓸 수 있었지만, 정확히 인덱스라는게 뭔지 정의를 내리는 게 어려웠다.
검색을 용이하게 해준다. 잘못 쓰면 느려진다....! 근데 인덱스가 뭔디..? 이런 마음
그리고 데이터의 중복도가 높은 컬럼 (ex. 남/여)는 인덱스 사용할 필요성이 낮다는 것부터가 이해가 안됨
그 때 인덱스의 자료구조를 보고 이해할 수 있었다.
📒 인덱스의 자료구조
인덱스를 여러 자료구조를 이용해서 구현할 수 있다.
대표적인 예가 해시 테이블과 B+Tree 인것이다.....!
여기서 깨달음을 얻을 수 있음.
🟠 Hash Table
해시 테이블이 무엇이냐, key 와 value 를 한 쌍으로 데이터를 저장하는 자료구조인것이다...!
이때 해시테이블의 시간 복잡도 O(1) , 매우 빠른 시간만에 원하는 데이터를 탐색할 수 있는 구조이다.
정렬되지 않은 일반 리스트의 시간 복잡도와 비교해보면은 당연히 빠르다.
고로 인덱스를 한번 생성해놓기만하면 검색 능력이 향상될수밖에 없는 것이다.
당연한거지만, 계속 명확하지 않은 정의로 장단점과 필요한 때만 읽다보니 오히려 이해가 안되는 상황이 발생했지만,
이해 완료!!!!!!!!!!!!!!
📒 인덱스의 동작 원리
그래도 동작 원리까지는 살펴보자.
데이터 블록이 10만개 있다고 가정할 때 SELECT문 실행시
server process가 구문 분석 과정을 마친 후 database buffer cache 에 조건이 부합하는 데이터가 있는지 확인
해당 정보가 buffer cache에 없다면 디스크 파일에서 조건에 부합하는 블럭을 찾아서 database buffer cache에 가져온 뒤 사용자에게 보여줌
이 때 인덱스가 없으면 10만개를 전부 database buffer cache 로 복사한 후 풀스캔으로 찾게 되는데
index가 있는 경우 where절의 조건 컬럼이 인덱스 키로 생성되어있는지 확인 후 인덱스에 조건에 부합하는 정보가 어떤 ROWID를 가지고 있는지 확인 후 ROWID에 있는 블럭을 찾아가 해당 블럭만 buffer cache에 복사한다.
